1. 读邮件数据集文件,提取邮件本身与标签。
列表
numpy数组
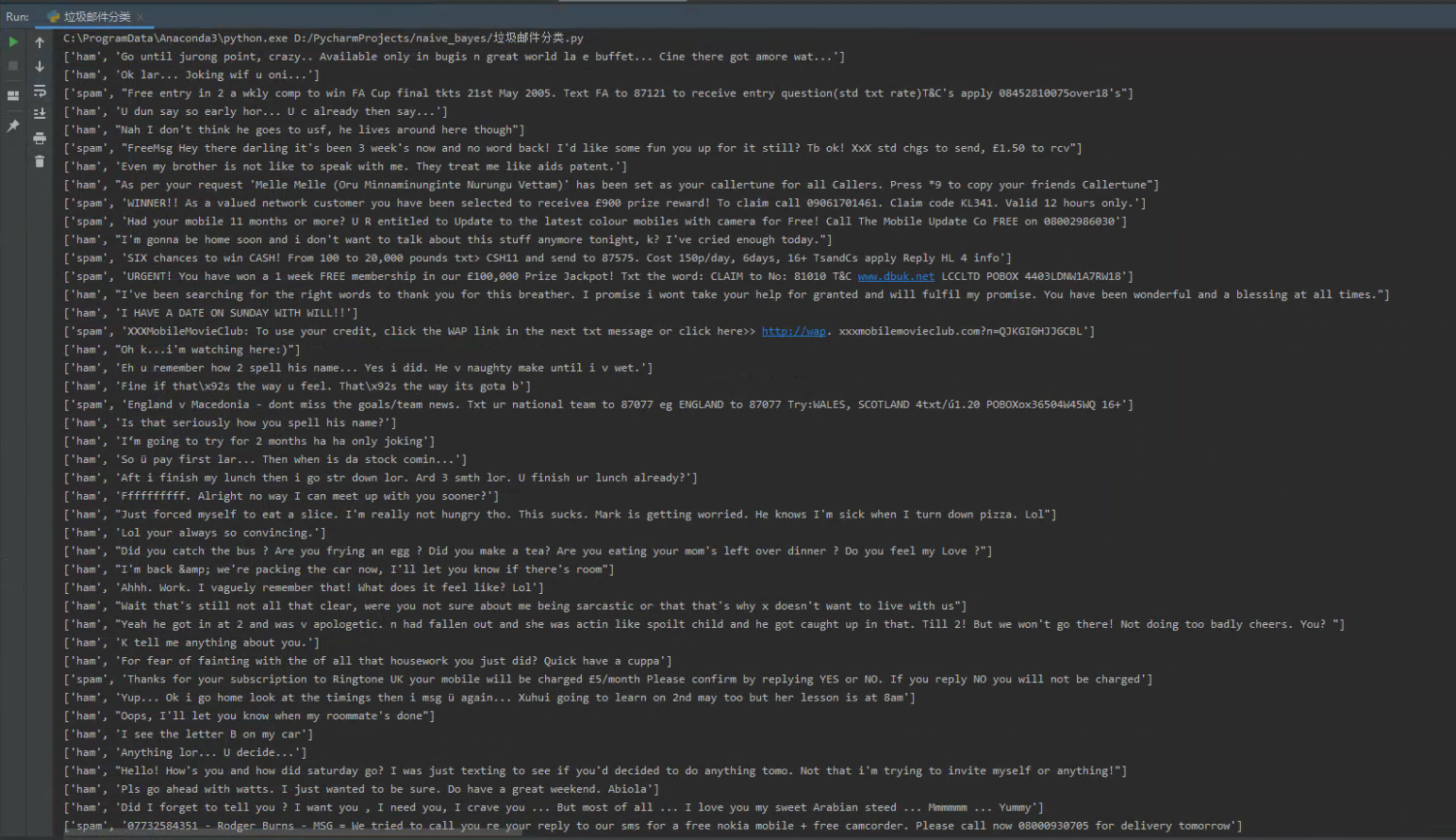
1 import csv 2 3 4 def read_file(): 5 file_path = r'D://PycharmProjects//naive_bayes//data//SMSSpamCollection' 6 sms = open(file_path, encoding='utf-8') 7 csv_reader = csv.reader(sms, delimiter=' ') 8 for r in csv_reader: 9 print(r) 10 sms.close() 11 12 13 if __name__ == '__main__': 14 read_file()
2.邮件预处理
- 邮件分句
- 句子分词
- 大小写,标点符号,去掉过短的单词
- 词性还原:复数、时态、比较级
- 连接成字符串
2.1 传统方法来实现
1 ''' 2 传统方法实现 3 ''' 4 # 利用列表、字典、集合等操作进行词频统计 5 sep = '.,:;?!-_' 6 exclude = {'a', 'the', 'and', 'i', 'you', 'in'} 7 8 9 def gettxt(): 10 txt = open(r'D://PycharmProjects//naive_bayes//data//test.txt', 'r').read().lower() # 大小写 11 for ch in sep: 12 txt = txt.replace(ch, '') # 标点符号 13 return txt 14 15 16 bigstr = gettxt() # 获取待统计字符串 17 biglist = bigstr.split() # 英文分词列表 18 bigdict = {} 19 for word in biglist: 20 bigdict[word] = bigdict.get(word, 0) + 1 # 词频统计字典 21 for word in exclude: 22 del(bigdict[word]) # 无意义词 23 bigitems = list(bigdict.items()) 24 bigitems.sort(key=lambda x: x[1], reverse=True) # 按词频排序 25 for i in range(10): 26 w, c = bigitems[i] 27 print('{0:>10}:{1:<5}'.format(w, c)) # TOP10
2.2 nltk库的安装与使用
pip install nltk
import nltk
nltk.download() # sever地址改成 http://www.nltk.org/nltk_data/
或
https://github.com/nltk/nltk_data下载gh-pages分支,里面的Packages就是我们要的资源。
将Packages文件夹改名为nltk_data。
或
网盘链接:https://pan.baidu.com/s/1iJGCrz4fW3uYpuquB5jbew 提取码:o5ea
放在用户目录。
----------------------------------
安装完成,通过下述命令可查看nltk版本:
import nltk
print nltk.__doc__
1 import nltk 2 3 print(nltk.__doc__)
2.1 nltk库 分词
nltk.sent_tokenize(text) #对文本按照句子进行分割
nltk.word_tokenize(sent) #对句子进行分词
1 import nltk 2 3 text = "I've been searching for the right words to thank you for this breather. I promise i wont take your help for " 4 "granted and will fulfil my promise. You have been wonderful and a blessing at all times." 5 6 sents = nltk.sent_tokenize(text) 7 sents

1 nltk.word_tokenize(sents[0]) 2 text.split()

2.2 punkt 停用词
from nltk.corpus import stopwords
stops=stopwords.words('english')
*如果提示需要下载punkt
nltk.download(‘punkt’)
或 下载punkt.zip
https://pan.baidu.com/s/1OwLB0O8fBWkdLx8VJ-9uNQ 密码:mema
复制到对应的失败的目录C:UsersAdministratorAppDataRoaming ltk_data okenizers并解压。
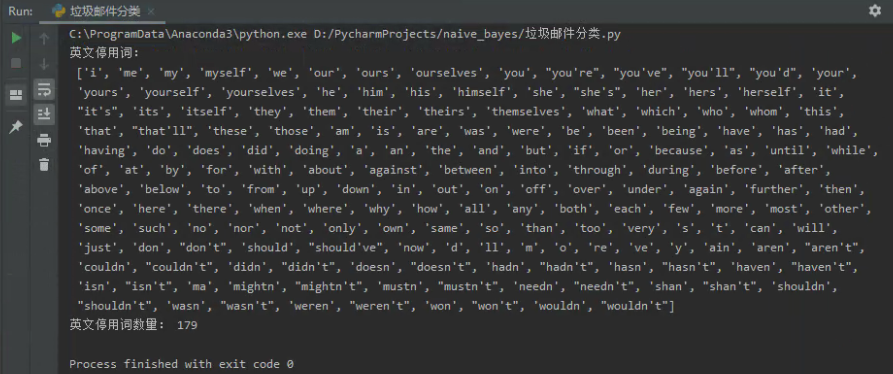
1 from nltk.corpus import stopwords 2 3 stops = stopwords.words('english') 4 print(stops) 5 print(len(stops))
1 text = "I've been searching for the right words to thank you for this breather. I promise i wont take your help for " 2 "granted and will fulfil my promise. You have been wonderful and a blessing at all times." 3 ''' 4 方法一 5 ''' 6 # tokens = [] 7 # for sent in nltk.sent_tokenize(text): 8 # for word in nltk.word_tokenize(sent): 9 # tokens.append(word) 10 # print(tokens) 11 ''' 12 方法二 13 ''' 14 tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)] 15 print("分词后的句子: ", tokens) 16 print("总共有", len(tokens), "个单词") 17 18 tokens = [token for token in tokens if token not in stops] 19 print("去除停用词后的句子: ", tokens) 20 print("总共有", len(tokens), "个单词")

2.3 NLTK 词性标注
1 nltk.pos_tag(tokens)

2.4 Lemmatisation(词性还原)
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
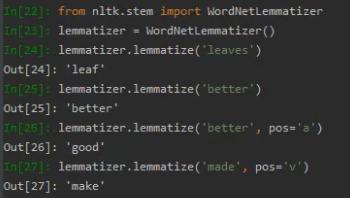
lemmatizer.lemmatize('leaves') #缺省名词
lemmatizer.lemmatize('best',pos='a')
lemmatizer.lemmatize('made',pos='v')
一般先要分词、词性标注,再按词性做词性还原。
2.5 编写预处理函数
def preprocessing(text):
sms_data.append(preprocessing(line[1])) #对每封邮件做预处理
1 from nltk.corpus import stopwords 2 import nltk 3 import csv 4 5 6 def preprocessing(text): 7 """ 8 预处理 9 """ 10 # text = text.decode("utf-8") 11 tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)] # 分词 12 stops = stopwords.words('english') # 使用英文的停用词表 13 tokens = [token for token in tokens if token not in stops] # 去除停用词 14 15 preprocessed_text = ' '.join(tokens) 16 return preprocessed_text 17 18 19 def create_dataset(): 20 """ 21 导入数据 22 """ 23 file_path = r'D://PycharmProjects//naive_bayes//data//SMSSpamCollection' 24 sms = open(file_path, encoding='utf-8') 25 sms_data = [] 26 sms_label = [] 27 csv_reader = csv.reader(sms, delimiter=' ') 28 for line in csv_reader: 29 sms_label.append(line[0]) # 提取出标签 30 sms_data.append(preprocessing(line[1])) # 提取出特征 31 sms.close() 32 print("数据集标签: ", sms_label) 33 print("数据集特征: ", sms_data) 34 35 36 if __name__ == '__main__': 37 create_dataset()

3. 训练集与测试集
4. 词向量
5. 模型
学习链接:https://blog.csdn.net/tinyjian/article/details/79110495