1.简述人工智能、机器学习和深度学习三者的联系与区别。
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。“人工智能”是“一门技术科学”,它研究与开发的对象是“理论、技术及应用系统”,研究的目的是为了“模拟、延伸和扩展人的智能”。
机器学习是建立在有人的理论方法基础上让机器去帮人类实现目标的。需要向“喂入”大量的数据,使机器能够更加准确地做出预判。
深度学习是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。最显著的应用是计算机视觉和自然语言处理(NLP)领域。显然,“深度学习”是与机器学习中的“神经网络”是强相关,“神经网络”也是其主要的算法和手段;或者我们可以将“深度学习”称之为“改良版的神经网络”算法。
人工智能是一个很老的概念,机器学习是人工智能的一个子集,深度学习又是机器学习的一个子集。机器学习与深度学习都是需要大量数据来“喂”的,是大数据技术上的一个应用,同时深度学习还需要更高的运算能力支撑,如GPU。
2. 全连接神经网络与卷积神经网络的联系与区别。
卷积神经网络是通过一层一层的节点组织起来的。和全连接神经网络一样,卷积神经网络中的每一个节点就是一个神经元。在全连接神经网络中,每相邻两层之间的节点都有边相连,于是会将每一层的全连接层中的节点组织成一列,这样方便显示连接结构。而对于卷积神经网络,相邻两层之间只有部分节点相连,为了展示每一层神经元的维度,一般会将每一层卷积层的节点组织成一个三维矩阵。
除了结构相似,卷积神经网络的输入输出以及训练的流程和全连接神经网络也基本一致,以图像分类为列,卷积神经网络的输入层就是图像的原始图像,而输出层中的每一个节点代表了不同类别的可信度。这和全连接神经网络的输入输出是一致的。类似的,全连接神经网络的损失函数以及参数的优化过程也都适用于卷积神经网络。因此,全连接神经网络和卷积神经网络的唯一区别就是神经网络相邻两层的连接方式。
3.理解卷积计算。
以digit0为例,进行手工演算。
from sklearn.datasets import load_digits #小数据集8*8
digits = load_digits()
| 0 | 0 | 5 | 13 | 9 | 1 | 0 | 0 |
| 0 | 0 | 13 | 15 | 10 | 15 | 5 | 0 |
| 0 | 3 | 15 | 2 | 0 | 11 | 8 | 0 |
| 0 | 4 | 12 | 0 | 0 | 8 | 8 | 0 |
| 0 | 5 | 8 | 0 | 0 | 9 | 8 | 0 |
| 0 | 4 | 11 | 0 | 1 | 12 | 7 | 0 |
| 0 | 2 | 14 | 5 | 10 | 12 | 0 | 0 |
| 0 | 0 | 6 | 13 | 10 | 0 | 0 | 0 |

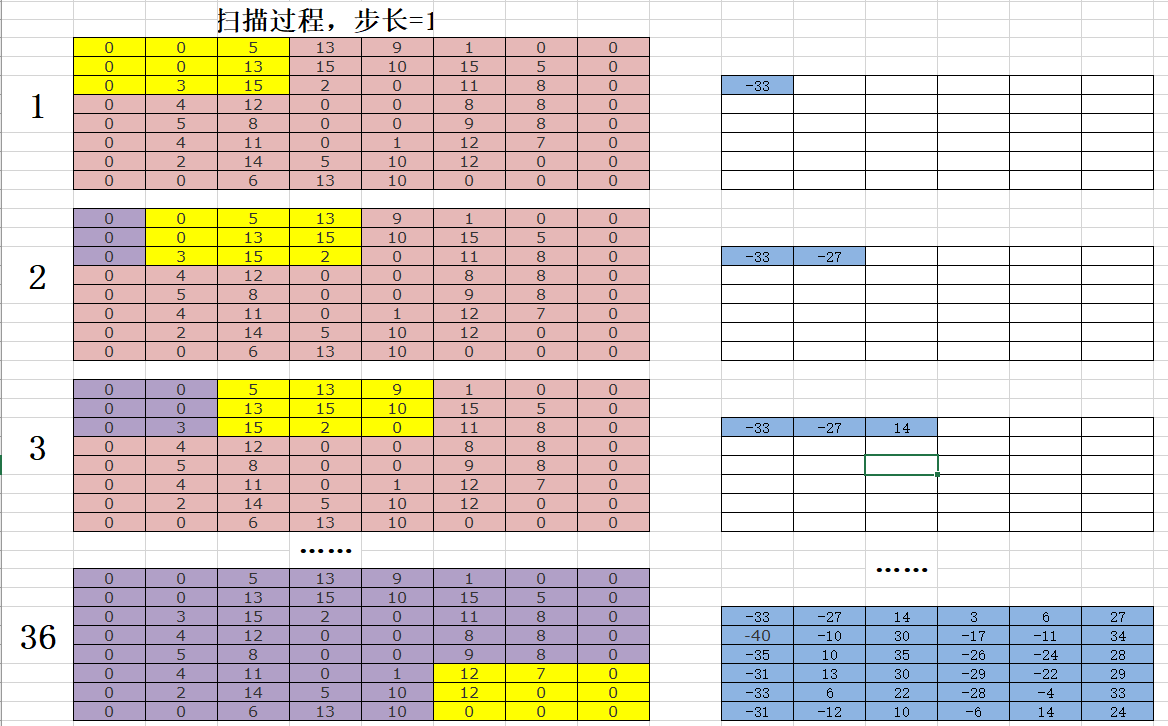
(8 - 3)/ 1 + 1 = 6
4.理解卷积如何提取图像特征。
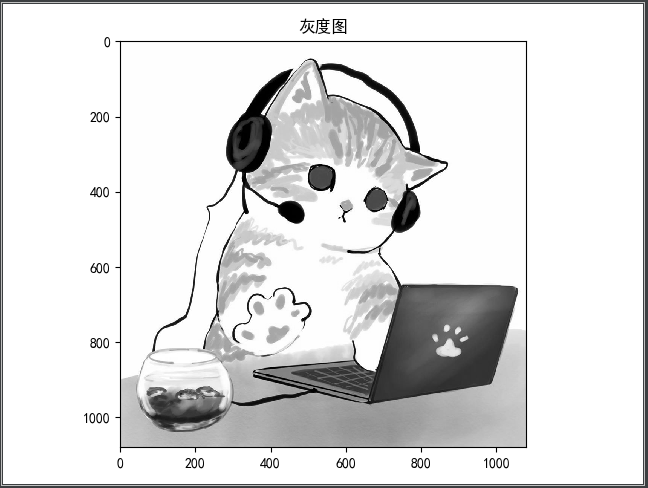
读取一个图像;
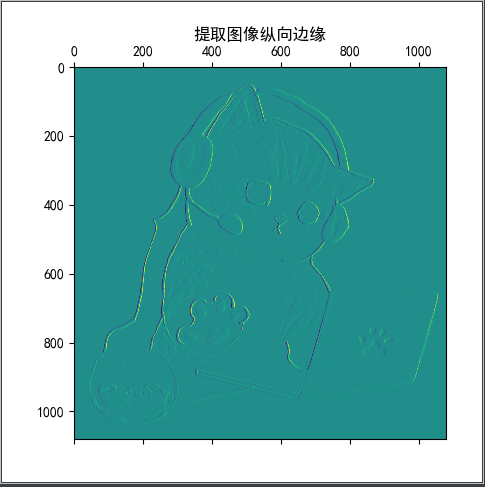
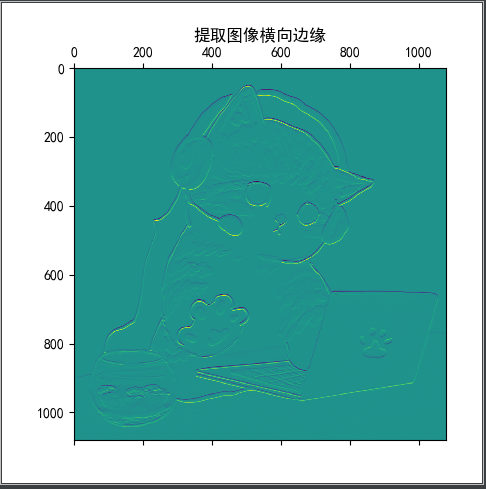
以下矩阵为卷积核进行卷积操作;
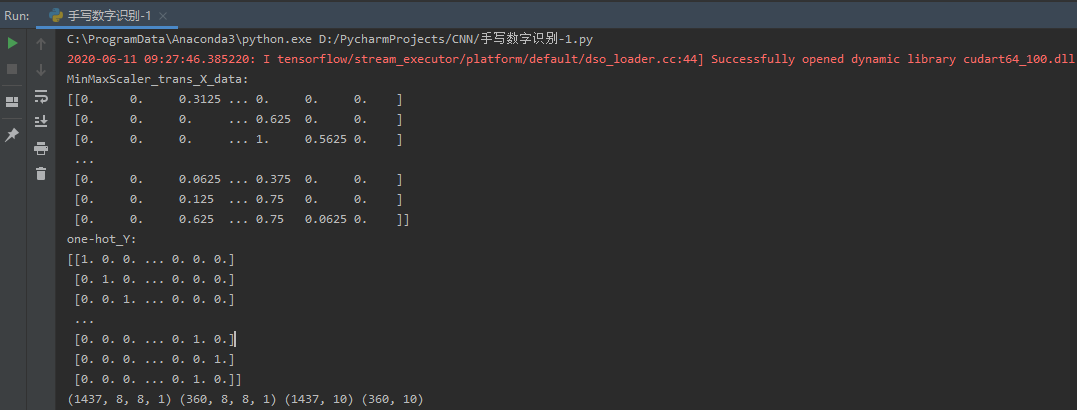
显示卷积之后的图像,观察提取到什么特征。
| 1 | 0 | -1 |
| 1 | 0 | -1 |
| 1 | 0 | -1 |
| 1 | 1 | 1 |
| 0 | 0 | 0 |
| -1 | -1 | -1 |
| -1 | -1 | -1 |
| -1 | 8 | -1 |
| -1 | -1 | -1 |
卷积API
scipy.signal.convolve2d
tf.keras.layers.Conv2D
代码如下:
1 from PIL import Image 2 from scipy.signal import convolve2d 3 from pylab import mpl 4 import matplotlib.pyplot as plt 5 import numpy as np 6 7 mpl.rcParams['font.sans-serif'] = ['SimHei'] 8 9 10 def img(filename): 11 """ 读取图像文件 """ 12 I = Image.open(filename) 13 # plt.title("原图") 14 # plt.imshow(I) 15 # plt.show() 16 return I 17 18 19 def img_convert(image): 20 """ 21 image.convert() 22 参数为1:为二值图像,非黑即白。每个像素用8个bit表示,0表示黑,255表示白。 23 参数为L:为灰度图像,每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。 24 转换公式:L = R * 299/1000 + G * 587/1000+ B * 114/1000。 25 """ 26 L = image.convert('L') # 变为灰色调 27 plt.title("灰度图") 28 plt.imshow(L) 29 plt.show() 30 return L 31 32 33 def convo_img(img, after_img): 34 """ 35 图像卷积 36 """ 37 cat = np.array(img) # 原图 38 after_cat = np.array(after_img) # 灰度图 39 40 # k = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]) 41 k1 = np.array([[1, 0, -1], [1, 0, -1], [1, 0, -1]]) # 垂直边缘检测 42 k2 = np.array([[1, 1, 1], [0, 0, 0], [-1, -1, -1]]) # 水平边缘检测 43 k3 = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]]) 44 # cat0 = convolve2d(after_cat, k, boundary='symm', mode='same') 45 cat1 = convolve2d(after_cat, k1, boundary='symm', mode='same') 46 cat2 = convolve2d(after_cat, k2, boundary='symm', mode='same') 47 cat3 = convolve2d(after_cat, k3, boundary='symm', mode='same') 48 plt.imshow(cat) 49 plt.title("原图") 50 plt.matshow(cat1) 51 plt.title("提取图像横向边缘") 52 plt.matshow(cat2) 53 plt.title("提取图像纵向边缘") 54 plt.matshow(cat3) 55 plt.title("提取图像边缘特征") 56 plt.show() 57 58 59 if __name__ == "__main__": 60 image = img("D:PycharmProjects卷积神经网络imagecat.jpg") 61 convert_image = img_convert(image) 62 convo_img(image, convert_image)


5. 安装Tensorflow,keras

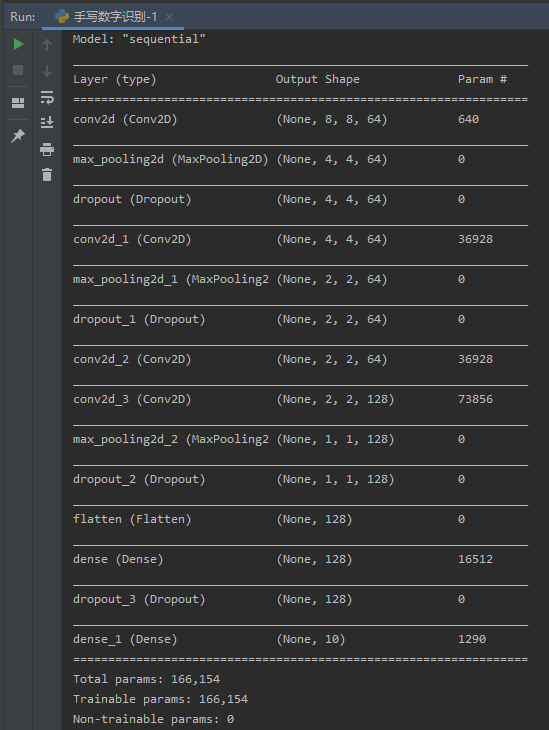
6. 设计手写数字识别模型结构,注意数据维度的变化。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2D
model = tf.keras.Sequential()
model.add(Conv2D(…))
model.add(MaxPool2D(…))
...
#可以上传手动演算的每层数据结构的变化过程。model.summary()
代码如下:
1 from sklearn.datasets import load_digits 2 from sklearn.model_selection import train_test_split 3 from sklearn.preprocessing import MinMaxScaler, OneHotEncoder 4 from tensorflow.keras.models import Sequential 5 from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D 6 import matplotlib.pyplot as plt 7 import numpy as np 8 import pandas as pd 9 import seaborn as sns 10 11 12 def create_dataset(): 13 digits = load_digits() 14 X_data = digits.data.astype(np.float32) 15 Y_data = digits.target.astype(np.float32).reshape(-1, 1) # 将Y_data变为一列 16 17 return X_data, Y_data 18 19 20 def process_data(X_data, Y_data): 21 # 将属性缩放到一个指定的最大和最小值(通常是1-0之间) 22 scaler = MinMaxScaler() 23 X_data = scaler.fit_transform(X_data) 24 print("MinMaxScaler_trans_X_data:") 25 print(X_data) 26 Y = OneHotEncoder().fit_transform(Y_data).todense() # 进行oe-hot编码 27 print("one-hot_Y:") 28 print(Y) 29 return X_data, Y 30 31 32 def split_dataset(X_data, Y): 33 # 转换为图片的格式(batch, height, width, channels) 34 X = X_data.reshape(-1, 8, 8, 1) 35 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y) 36 print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) 37 return X_train, X_test, y_train, y_test 38 39 40 def digits_model(X_train): 41 """ 构建模型 """ 42 model = Sequential() 43 44 ks = (3, 3) 45 input_shape = X_train.shape[1:] 46 47 # 一层卷积 48 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', input_shape=input_shape, activation='relu')) 49 # 池化层1 50 model.add(MaxPool2D(pool_size=(2, 2))) 51 model.add(Dropout(0.2)) 52 # 二层卷积 53 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu')) 54 # 池化层2 55 model.add(MaxPool2D(pool_size=(2, 2))) 56 model.add(Dropout(0.2)) 57 58 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu')) 59 model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu')) 60 model.add(MaxPool2D(pool_size=(2, 2))) 61 model.add(Dropout(0.2)) 62 63 model.add(Flatten()) # 平坦层 64 model.add(Dense(128, activation='relu')) # 全连接层 65 model.add(Dropout(0.2)) 66 model.add(Dense(10, activation='softmax')) # 激活函数 67 68 print(model.summary()) 69 70 return model 71 72 73 def train_model(model, X_train, y_train): 74 """ 训练模型 """ 75 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 76 train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=256, epochs=45, verbose=2) 77 return train_history 78 79 80 def score_model(model, X_test, y_test): 81 """ 评估模型 """ 82 return print(model.evaluate(X_test, y_test)[1]) 83 84 85 def test_model(model, X_test): 86 """ 测试模型 """ 87 y_pre = model.predict_classes(X_test) 88 89 return y_pre 90 91 92 def crossrtab_matrix(y_test): 93 """ 94 交叉表、交叉矩阵 95 查看预测数据与原数据对比 96 """ 97 y_test = np.argmax(y_test, axis=1).reshape(-1) 98 y_test = np.array(y_test)[0] 99 crosstab = pd.crosstab(y_test, y_pre, rownames=['labels'], colnames=['predict']) 100 matrix = pd.DataFrame(crosstab) 101 sns.heatmap(matrix, annot=True, cmap="RdPu", linewidths=0.2, linecolor='pink') 102 plt.show() 103 104 105 if __name__ == '__main__': 106 X_data, Y_data = create_dataset() 107 X_data, Y = process_data(X_data, Y_data) 108 X_train, X_test, y_train, y_test = split_dataset(X_data, Y) 109 model = digits_model(X_train) 110 train_model(model, X_train, y_train) 111 score_model(model, X_test, y_test) 112 y_pre = test_model(model, X_test) 113 crossrtab_matrix(y_test)
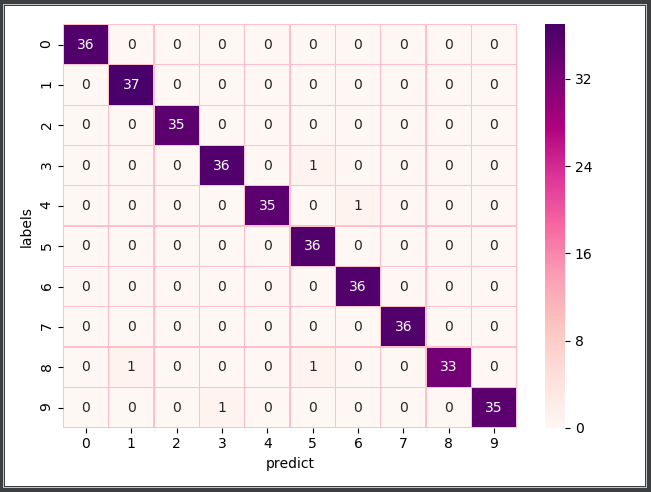
运行结果如下:


参考:
https://www.jianshu.com/p/afe485aa08ce
https://blog.csdn.net/junjun150013652/article/details/82217571