执行引擎
执行引擎是java虚拟机的重要组成部分。它的作用是接收字节码,解析字节码,执行并输出执行结果。
虚拟机是相对于物理机的概念,物理机的执行引擎是直接建立在处理器、寄存器、指令集和操作系统的层面上的。虚拟机的执行引擎是JVM自己实现的。所以可以定制指令集和执行引擎的结构体系。
运行时栈帧结构
栈帧是支持虚拟机进行方法调用和方法执行的数据结构。它存储在运行时数据区的虚拟机栈中。
每一个方法的从开始到完成的过程,都对应了一个栈帧的入栈和出栈的过程。
一个栈帧包含了:局部变量表,操作数栈,动态连接,方法返回地址。
局部变量表和操作数栈在编译的时候,已经可以完全确定,并且写入到了Class文件的方法表的Code属性之中。因此一个栈帧需要多大的内存,不会受到程序运行期的变量数据影响。
局部变量表
用来存放方法参数和方法中的局部变量。
如果是占用内存比较大的对象,在使用结束但是作用域还有其他执行比较长的语句之前,可以把它置为null,然后就可以被gc。但是不建议对所有的对象都这个处理,没有必要的地方不需要有这么多的类似代码。
同时,使用JIT编译执行的时候,赋null值的操作将会被抹除。
局部变量不会被赋予初始值,所以必须初始化才能使用。
操作数栈
一个后进先出的栈。
我理解的,局部变量用于存储,操作数用于计算。比如执行一个加法操作,需要将两个数值压入操作数栈顶,调用其他方法的时候,可以通过操作数栈来传递参数。
动态连接
每个方法都包含一个指向运行时常量池中的方法引用。持有这个引用(这里应该是指符号引用)就可以支持在方法调用的过程中动态连接。
方法调用
不等同于方法执行,目的是为了确定方法的版本。可以说,就是确定方法的直接引用。
非虚方法
Class文件中的方法引用都是常量池中的符号引用,在类加载的解析操作中,部分符号引用将会白转换为直接引用。
这些可以在解析阶段转换的方法:
需要满足:编译器可知,运行期不可变。这种方法叫非虚方法。
非虚方法:静态方法,私有方法,构造器,父类方法,final方法。
分派
描述虚拟机如何定位要执行的方法。
- 静态分派:编译阶段的分派,根据变量声明的类型来确定要执行的方法。重载方法的选择使用静态分派。
- 动态分派:运行阶段的分派,根据变量实际的类型来确定要执行的方法。重写方法的选择使用动态分派。
静态分派:
编译阶段需要定义方法的符号引用,符号引用用于描述一个方法,描述的度量是方法名和方法参数。如果有方法重载,这个时候就需要编译器选择一个合适的符号引用,这个阶段是在编译期做的,所以只能使用参数的声明类型来识别,称为静态分派。
-
public class StaticDispatch {
-
static abstract class Human{
-
}
-
static class Man extends Human{
-
}
-
static class Woman extends Human{
-
}
-
public static void sayHello(Human guy){
-
System.out.println("hello,guy!");
-
}
-
public static void sayHello(Man guy){
-
System.out.println("hello,gentlemen!");
-
}
-
public static void sayHello(Woman guy){
-
System.out.println("hello,lady!");
-
}
-
-
public static void main(String[] args) {
-
Human man=new Man();
-
Human woman=new Woman();
-
sayHello(man);
-
sayHello(woman);
-
}
-
}
输出:
hello,guy!
hello,guy!
动态分派:在编译期确定了静态分派的方法符号引用之后,在运行的时候,还要根据调用方法的实际对象类型来确定要调用那个类的符合这个符号引用的方法。动态分派将会根据方法的符号引用,在运行时的实际对象类型中寻找方法,如果找不到,会去超类寻找。
-
public class DynamicDispatch {
-
static abstract class Human{
-
protected abstract void sayHello();
-
}
-
static class Man extends Human{
-
@Override
-
protected void sayHello() {
-
System.out.println("man say hello!");
-
}
-
}
-
static class Woman extends Human{
-
@Override
-
protected void sayHello() {
-
System.out.println("woman say hello!");
-
}
-
}
-
public static void main(String[] args) {
-
-
Human man=new Man();
-
Human woman=new Woman();
-
man.sayHello();
-
woman.sayHello();
-
man=new Woman();
-
man.sayHello();
-
}
-
}
输出:
man say hello!
woman say hello!
woman say hello!
方法重载的选择:
-
public class LiteralTest {
-
/**/
-
public static void sayHello(char arg){
-
System.out.println("hello char");
-
}
-
public static void sayHello(int arg){
-
System.out.println("hello int");
-
}
-
-
public static void sayHello(long arg){
-
System.out.println("hello long");
-
}
-
-
public static void sayHello(Character arg){
-
System.out.println("hello Character");
-
}
-
public static void main(String[] args) {
-
sayHello('a');
-
}
-
}
因为传入的是一个char类型,所以会选择第一个方法,如果删除第一个方法,将会选择第二个,以此类推,优先级为第1 2 3 4 个方法。也就是说,最后才选择装箱。如果有可变参数的方法,那么它将至绝对的最后一个选择。
基于栈的字节码解释执行引擎
使用解释的方式来执行字节码方法。
基于栈的指令集与基于寄存器的指令集
java编译器输出的指令流,基本上是一种基于栈的指令集架构,它们依赖操作数栈进行工作,与之相对的另外一套常用的指令集架构是基于寄存器的指令集,最典型的就是x86的二地址指令集,这些指令依赖寄存器进行工作。那么基于栈的指令集和基于寄存器的指令集在这两者之间的不同:
例如,分别使用这两种指令集去计算"1+1"的结果,基于栈的指令计算过程:
iconst_1
iconst_1
iadd
istore_0
两个iconst_1指令连续的把两个常量1压入栈后,iadd指令把栈顶的两个值出栈并相加,然后把结果放回栈顶,最后istore_0把栈顶的值放到局部便量表的第0个slot中。
如果是基于寄存器的指令集,程序会是这样的:
mov eax,1
add eax,1
mov指令把EAX寄存器的值设为1,然后add指令再把这个值加1,结果就保存在EAX寄存器中。
基于栈的指令集最主要的优点就是可移植性,寄存器由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免的要受到硬件的约束。
栈架构指令集的主要缺点是执行速度相对来说稍慢一些。栈架构指令集的代码虽然紧凑,但是完成相同功能所需的指令数量一般会比寄存器架构多,因为出栈、入栈操作本身就产生了相当多的指令。更重要是栈实现在内存中,频繁的栈访问也就意味着频繁的内存访问,相对于处理器来说,内存始终是执行速度的瓶颈,尽管虚拟机可以采用栈顶缓存的手段,把最常用的操作映射到寄存器中以避免直接内存访问,但这也只是优化措施而不是解决本质问题的方法,因此,由于指令数量和内存访问的原因,导致了栈架构指令集的执行速度相对较慢。
基于栈的解释器执行过程
-
public int calculate(){
-
int a = 100;
-
int b = 200;
-
int c = 300;
-
return (a + b) * c;
-
}
我们编译代码后使用javap -verbose命令查看字节码指令,具体字节码代码如下所示:
-
public int calculate();
-
Code:
-
Stack=2, Locals=4, Args_size=1
-
0: bipush 100
-
2: istore_1
-
3: sipush 200
-
6: istore_2
-
7: sipush 300
-
10: istore_3
-
11: iload_1
-
12: iload_2
-
13: iadd
-
14: iload_3
-
15: imul
-
16: ireturn
-
LineNumberTable:
-
line 3: 0
-
line 4: 3
-
line 5: 7
-
line 6: 11
-
-
}
根据字节码可以看出,这段代码需要深度为2的操作数栈(Stack=2)和4个Slot的局部变量空间(Locals=4)。下面,使用7张图片来描述上面的字节码代码执行过程中的代码、操作数栈和局部变量表的变化情况。
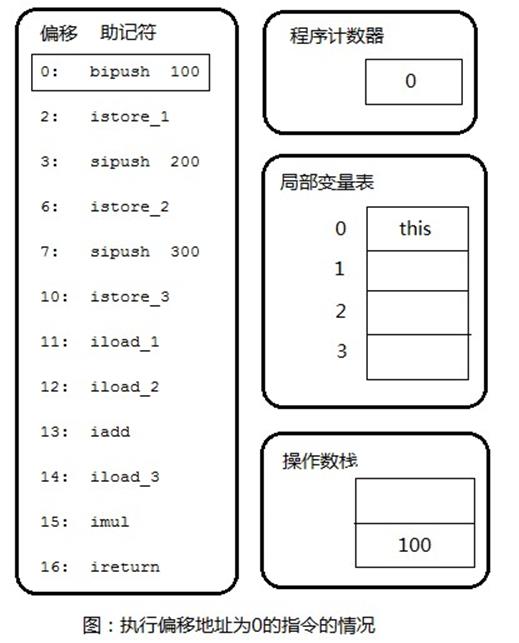
上图展示了执行偏移地址为0的指令的情况,bipush指令的作用是将单字节的整型常量值(-128~127)推入操作数栈顶,后跟一个参数,指明推送的常量值,这里是100。

上图则是执行偏移地址为1的指令,istore_1指令的作用是将操作数栈顶的整型值出栈并存放到第1个局部变量Slot中。后面四条指令(3、6、7、10)都是做同样的事情,也就是在对应代码中把变量a、b、c赋值为100、200、300。后面四条指令的图就不重复画了。

上面展示了执行偏移地址为11的指令,iload_1指令的作用是将局部变量第1个Slot中的整型值复制到操作数栈顶。

上图为执行偏移地址12的指令,iload_2指令的执行过程与iload_1类似,把第2个Slot的整型值入栈。
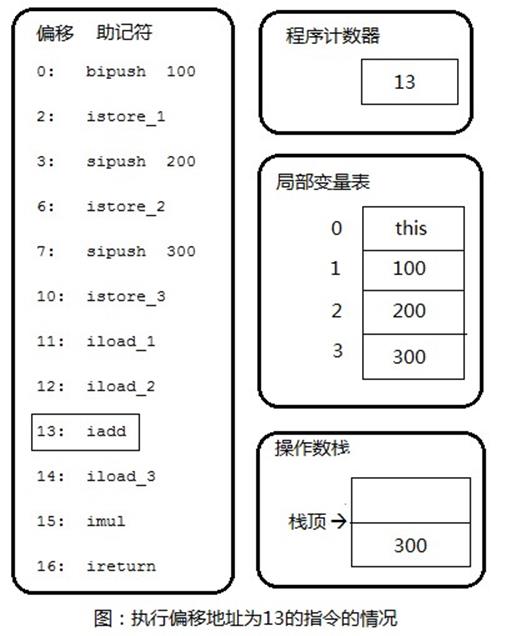
上图展示了执行偏移地址为13的指令情况,iadd指令的作用是将操作数栈中前两个栈顶元素出栈,做整型加法,然后把结果重新入栈。在iadd指令执行完毕后,栈中原有的100和200出栈,它们相加后的和300重新入栈。

上图为执行偏移地址为14的指令的情况,iload_3指令把存放在第3个局部变量Slot中的300入栈到操作数栈中。这时操作数栈为两个整数300,。
下一条偏移地址为15的指令imul是将操作数栈中前两个栈顶元素出栈,做整型乘法,然后把结果重新入栈,这里和iadd指令执行过程完全类似,所以就不重复画图了。

上图是最后一条指令也就是偏移地址为16的指令的执行过程,ireturn指令是方法返回指令之一,它将结束方法执行并将操作数栈顶的整型值返回给此方法的调用者。到此为止,该方法执行结束。
注:上面的执行过程只是一种概念模型,虚拟机最终会对执行过程做出一些优化来提高性能,实际的运作过程不一定完全符合概念模型的描述。不过从这段程序的执行过程也可以看出栈结构指令集的一般运行过程,整个运算过程的中间变量都是以操作数栈的出栈和入栈为信息交换途径。