Day01--查询语句执行流程
mysql 基础架构:

MySQL 5.5.5 版本开始InnoDB成为了默认存储引擎
连接器:
链接器超时断开参数 wait_timeout 默认 8小时
缓存
mysql 缓存提供按需使用的方式 将参数 query_cache_type 设置成 DEMAND,这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定
MySQL 8.0 版本直接将查询缓存的整块功能删掉了
mysql> select SQL_CACHE * from T where ID=10;
分析器:
分析器先会做“词法分析”。再做“语法分析”
优化器:
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
执行器:
首先判读用户对表有没有查询权限。如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的
Day02--更新语句执行流程
更新比查询多涉及两个日志模块 redo log 和 binlog
mysql> update T set c=c+1 where ID=2;
redo log
redo log 属于innodb 独有日志。

如图 InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
write pos 是当前记录的位置 heckpoint 是当前要擦除的位置。中间绿色部分为剩余空间。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe
binlog
binlog 是server 层的日志
这两种日志有以下三点不同。
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
这个 update 语句的执行流程图,图中浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的。
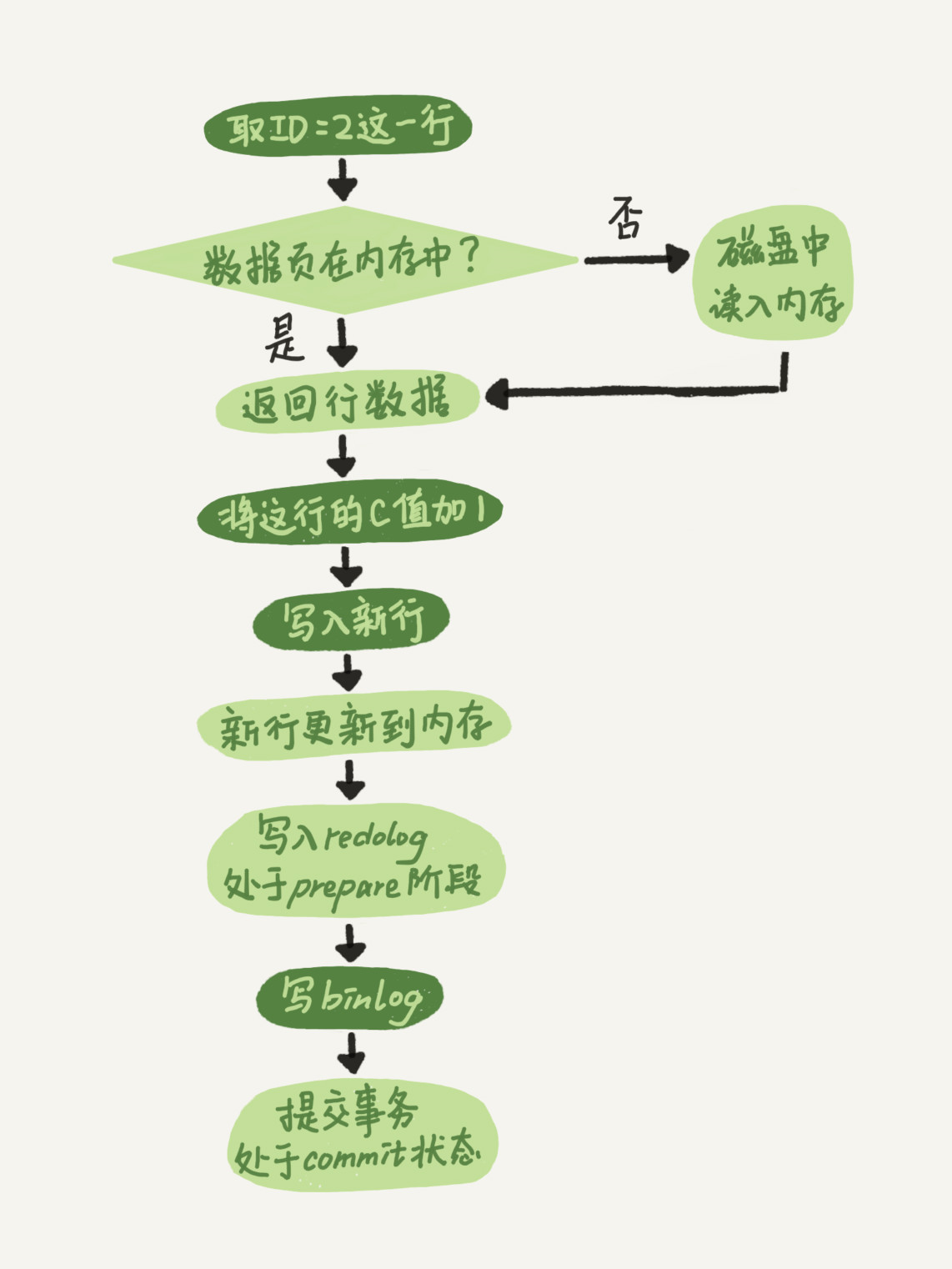
最后三步将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"
好处:为了让两份日志之间的逻辑一致
Day03--事务
隔离级别
当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
- 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
mysql> show variables like 'transaction_isolation';
事务隔离的实现
在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。

当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。
如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)
事务的启动方式
mysql 有以下两种启动事务的方式
- 显式启动事务语句, begin 或 start transaction。配套的提交语句是 commit,回滚语句是 rollback。
- set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行 commit 或 rollback 语句,或者断开连接。
执行 commit 则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务
你可以在 information_schema 库的 innodb_trx 这个表中查询长事务,比如下面这个语句,用于查找持续时间超过 60s 的事务。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
文章来源:极客时间 丁奇--MYSQL 实战 45讲
