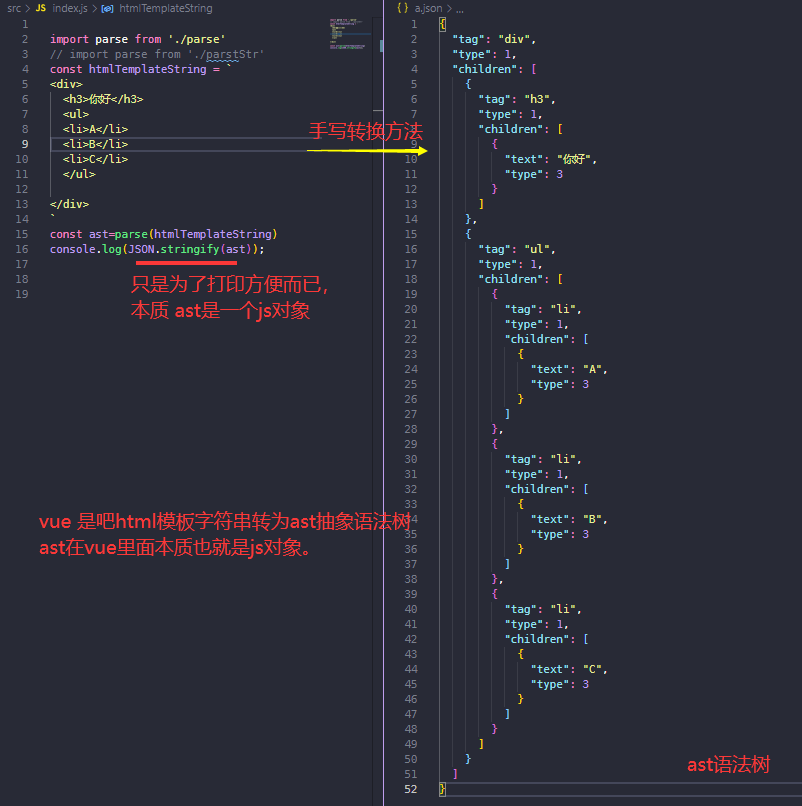
export default function parse(htmlStr) { htmlStr = htmlStr.replace(/^s+|s+$/g, '') let i = 0 let rest = htmlStr const startReg = /^<([a-z]+[0-6]?)>/
// const startReg = /^<([a-z]+[0-6]?)(s[^<]+)?>/ 这个功能更强大 可以匹配出 属性 ru <h1 class="demo" id="text">
const wordReg = /^([^<s]+)</[a-z]+[0-6]?>/ //除了空格和<的任意1到多个字符 const endReg = /^</([a-z]+[0-6]?)>/ const stack = [] while (i < htmlStr.length) { rest = htmlStr.slice(i) if (startReg.test(rest)) { const tag = rest.match(startReg)[1] stack.push({ tag: tag, type: 1, children: [] }) //遇到开始标签入栈 i += tag.length + 2 } else if (wordReg.test(rest)) { const word = rest.match(wordReg)[1] stack[stack.length - 1].children.push({ text: word, type: 3 }) i += word.length } else if (endReg.test(rest)) { const tag = rest.match(endReg)[1] const tagPop = stack.pop() if (!stack.length) return tagPop stack[stack.length - 1].children.push(tagPop) i += tag.length + 3 } else { i++ } } }