1.这样一个问题,作为一个开发人员需要掌握数据库的哪些东西? 在开发中涉及到数据库,基本上只用到了sql语句,如何写sql以及对其进行优化就比较重要,那些mysql的厚本书籍针对的是DBA,我们只需要学习其中的sql就可以了。
2.既然会写sql是目标,那么怎么才能写好sql.学习下面几点:
1)Mysql的执行顺序,这个是写sql的核心,之前遇到的一些错误就是因为对其不了解;
2)如何进行多表查询,优化,这个是很重要的部分;
3)sql语句的函数,sql提供的函数方便了很多操作;
3.这篇对Mysql语句执行顺序的学习做了总结:
1)Mysql语法顺序,即当sql中存在下面的关键字时,它们要保持这样的顺序:
- select[distinct]
- from
- join(如left join)
- on
- where
- group by
- having
- union
- order by
- limit
2)Mysql执行顺序,即在执行时sql按照下面的顺序进行执行:
- from
- on
- join
- where
- group by
- having
- select
- distinct
- union
- order by
3)针对上面的Mysql语法顺序和执行顺序,循序渐进进行学习:
建立如下表格orders:
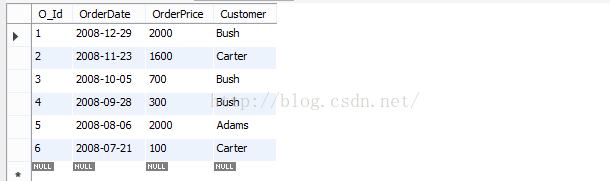
注:下面所有语句符合语法顺序(也不可能不符合,因为会报错^_^),只分析其执行顺序:(join和on属于多表查询,放在最后展示)
语句一:
- select a.Customer
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams'
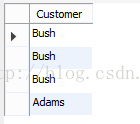
分析一:首先是from语句找到表格,然后根据where得到符合条件的记录,最后select出需要的字段,结果如下:
语句二groupby:groupby要和聚合函数一起使用
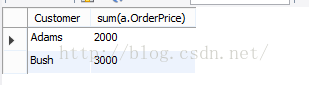
- select a.Customer,sum(a.OrderPrice)
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams'
- group by a.Customer
分析二:在from,where执行后,执行group by,同时也根据group by的字段,执行sum这个聚合函数。这样的话得到的记录对group by的字段来说是不重复的,结果如下:
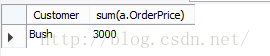
语句三having:
- select a.Customer,sum(a.OrderPrice)
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
分析三:由于where是在group之前执行,那么如何对group by的结果进行筛选,就用到了having,结果如下:
语句四distinct: (为测试,先把数据库中Adams那条记录的OrderPrice改为3000)
- select distinct sum(a.OrderPrice)
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1700
分析四:将得到一条记录(没有distinct,将会是两条同样的记录):

语句五union:完全是对select的结果进行合并(默认去掉重复的记录):
- select distinct sum(a.OrderPrice) As Order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As Order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
分析五:默认去掉重复记录(想保留重复记录使用union all),结果如下:

语句六order by:
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
- order by order1
分析:升序排序,结果如下:

语句七limit:
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As order1
- from orders a
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
- order by order1
- limit 1
分析七:取出结果中的前1条记录,结果如下:
语句八(上面基本讲完,下面是join 和 on):

- select distinct sum(a.OrderPrice) As order1,sum(d.OrderPrice) As order2
- from orders a
- left join (select c.* from Orders c) d
- on a.O_Id = d.O_Id
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 1500
- union
- select distinct sum(a.OrderPrice) As order1,sum(e.OrderPrice) As order2
- from orders a
- left join (select c.* from Orders c) e
- on a.O_Id = e.O_Id
- where a.Customer='Bush' or a.Customer = 'Adams' or a.Customer = 'Carter'
- group by a.Customer
- having sum(a.OrderPrice) > 2000
- order by order1
- limit 1
分析八:上述语句其实join on就是多连接了一张表,而且是两张一样的表,都是Orders。 执行过程是,在执行from关键字之后根据on指定的条件,把left join指定的表格数据附在from指定的表格后面,然后再执行where字句。
注:
1)使用distinct要写在所有要查询字段的前面,后面有几个字段,就代表修饰几个字段,而不是紧随distinct的字段;
2)group by执行后(有聚合函数),group by后面的字段在结果中一定是唯一的,也就不需要针对这个字段用distinct;
转载:https://blog.csdn.net/jintao_ma/article/details/51253356