目录:
一、基础概念
1、paramiko模块
2、进程与线程
1、进程
2、线程
3、进程与线程的区别
4、Python GIL
5、thread模块
6、Join与Daemon
7、线程锁(Mutex)
8、GIL VS 线程锁
9、递归锁
10、Semaphore(信号量)
11、Event
12、queue
13、生产者消费者模型
一、基础概念
1、paramiko模块
paramiko基于SSH用于连接远程服务器并执行相关操作
SSHClient
用于连接远程服务器并执行基本命令
1、基于用户名密码连接


import paramiko ssh = paramiko.SSHClient() #创建ssh对象 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #允许连接不在know_hosts文件中的主机 ssh.connect(hostname='172.16.233.131', port=22, username='root',password='admin') #连接服务器 stdin,stdout,stderr = ssh.exec_command('top -bn 1') #执行命令 res, err = stdout.read(), stderr.read() result = res if res else err #显示输出 print(result.decode()) #输出值需要解码 #打印结果 ssh.close() #关闭链接
2、基于公钥密码链接
import paramiko ssh = paramiko.SSHClient() #创建ssh对象 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #允许连接不在know_hosts文件中的主机 private_key = paramiko.RSAKey.from_private_key_file('/Users/Gavin/.ssh/id_rsa') #通过ssh私钥文件访问 ssh.connect(hostname='172.16.233.131', port=22, username='root',pkey=private_key) #连接服务器 stdin,stdout,stderr = ssh.exec_command('top -bn 1') #执行命令 res, err = stdout.read(), stderr.read() result = res if res else err #显示输出 print(result.decode()) #输出值需要解码 #打印结果 ssh.close() #关闭链接
SFTPClient
用于链接远程服务器并上传下载
1、基于用户名密码上传下载
import paramiko transport = paramiko.Transport(('172.16.233.131',22)) # transport.connect(username='root',password='admin') sftp = paramiko.SFTPClient.from_transport(transport) #链接服务器 sftp.put('1.txt', '/tmp/1.txt') #上传文件 sftp.get('/tmp/yum.log','yum.log') #下载文件 sftp.close()
2、基于公钥密码链接
import paramiko transport = paramiko.Transport(('172.16.233.131',22)) private_key = paramiko.RSAKey.from_private_key_file('/Users/Gavin/.ssh/id_rsa') transport.connect(username='root',pkey=private_key) sftp = paramiko.SFTPClient.from_transport(transport) #链接服务器 sftp.put('1.txt', '/tmp/1.txt') #上传文件 sftp.get('/tmp/yum.log','yum.log') #下载文件 sftp.close()
2、进程与线程
1、进程(process)
程序并不能单独运行,只有将程序装载到内存中,系统为他分配资源才能运行,而这种执行的程序就程为进程,程序与进程的区别在于:程序是指令的集合,它是进程运行的静态描述文本,进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统调度下,可以实现并发执行,这样的设计,大大提高CPU的利用率,进程的出现让每个用户感觉自己是在独享CPU,因此进程就是为了在CPU上实现多道编程而提出的
有了进程为什么还要线程?
进程有很多优点,它提高了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机利用率,很多人不理解既然进程这么优秀,为什么还要线程,其实仔细观察就会发现进程还有很多缺陷,主要体现在:
- 进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了
- 进程在执行过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程汇总有些工作不依赖输入的数据,也将无法执行
一个操作系统就像一个工厂,工厂里面有很多个生产车间,不同的车间生产不同的产品,每个车间就相当于一个进程,且你的工厂又穷,供电不足,同一时间只能给一个车间供电,为了能让所有车间同时生产,工厂的电工只能给不同的车间分时供电,但是轮到你的车间时,发现只有一个工人在干活,结果生产效率极低,为了解决这个问题应该怎么办,没错,就是多加几个工人,让几个工人并行工作,每个工人就是线程!
2、线程(thread)
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运行单位,一条线程指的是进程中的一个单一顺序的控制流,一个进程可以并发多个线程,每个线程并行执行不同的任务
3、进程与线程的区别
- 同一个进程中的不同线程共享该进程的地址空间,而进程是独立拥有各自的地址空间
- 线程可以直接访问它所属进程的数据分段,而进程有它父进程数据分段拷贝
- 线程能直接和同一个进程中的线程通信,而进程必须使用中间件的方式和其他进程通信
- 新线程很容易创建,而新进程需要从它的父进行进行拷贝
- 线程可以对同一进程的线程进行大量的控制;进程只能对子进程进行控制
- 改变主线程可能会影响该进程中其他的线程,而修改父进程不会影响子进程
4、Python GIL(Global Interpreter Lock)
在CPython中,由于python解释器是用C语言写的,所以在执行python命令时,无论启动多少个线程,有多少个CPU,在执行的时候python都会淡定的在同一时刻只允许一个线程运行,这是因为解释器调用C语言的接口,如果没有GIL的话,每个进程都会独自加载内存数据,完成运算后返回数据,这时返回的数据有可能会乱序,所以需要增加GIL来保证数据运算的准确性
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
5、threading模块
线程有两种调用方式,如下:
1、直接调用
import threading import time def say(num): print('runing on number: %s' %num) time.sleep(1) if __name__ == '__main__': for i in range(1,50): t = threading.Thread(target=say, args=('%s' %i,)) #target是执行的函数名,不加() args为元组方式,如果有参数需要在args中传递,如果没有不需要但是target后面','必须有 t.start() #线程通过start()启动
2、继承式调用
import threading import time class MyThread(threading.Thread): def __init__(self,num): super(MyThread,self).__init__() self.num = num def run(self): #继承式调用中,必须函数名必须叫run print('running task : %s' %self.num) time.sleep(2) if __name__ == '__main__': for i in range(1,10): t = MyThread('t%s' %i) t.start()
6、Join与Daemon
join()是等价于其他语言中的wait()函数,这样代表程序没执行完毕前不会往下执行,这样就将并行方式变为串行
1、通过举例说明join的用法,下面来计算所有线程完成的时间
import threading import time class MyThread(threading.Thread): def __init__(self,num): super(MyThread,self).__init__() self.num = num def run(self): print('running task: %s ' % self.num) time.sleep(2) print('task %s done..' % self.num) if __name__ == '__main__': start_time = time.time() t_obj = [] #创建空列表 for i in range(10): t = MyThread(i) t.start() t_obj.append(t) #将线程生成的实例放入到列表中 for t in t_obj: #针对每个线程进行join方法,这样做的目的在于先让全部线程运行起来,然后使用join方法保证所有子线程结束后再往下执行主线程内容 t.join() print('the total time is %s' %(time.time() - start_time))
输出如下:
running task: 0 running task: 1 running task: 2 running task: 3 running task: 4 running task: 5 running task: 6 running task: 7 running task: 8 running task: 9 task 0 done.. task 1 done.. task 2 done.. task 3 done.. task 4 done.. task 9 done.. task 6 done.. task 7 done.. task 8 done.. task 5 done.. the total time is 2.00982666015625
一些进程是后台进程,比如发送心跳报文,或者收集某些日志活动,它们只有在主程序运行时才生效,如果杀死主进程后,这些进程应该立即被杀掉而不应该等待它们执行完毕再关闭正常程序。
一般来说,系统启动后就会生成主进程,当主进程结束后,程序还需要看哪些非守护进程(非Daemon进程)在执行,只有非守护进程执行结束后才退出程序,对于后台进程来说,在调用时可以配置为Daemon进程,这样主进程关闭后,直接退出
Daemon就是用来将程序中的非主进程变为守护进程的方法
需要注意的是有些情况下Daemon线程停止为非预期方式,他们的资源(文件、数据库、交互报文等)没有被正确的释放,如果你想你的线程优雅的停止,确保他们为非守护进程同时使用更稳妥的信号进制例如Event方式
下面通过例子来说明Daemon与非Daemon进程的区别:
1、默认情况下产生的子进程为非守护进程
import threading import time class MyThread(threading.Thread): def __init__(self,num): super(MyThread,self).__init__() self.num = num def run(self): print('running task: %s %s' % (self.num,threading.current_thread())) time.sleep(2) print('task %s done..' % self.num) if __name__ == '__main__': start_time = time.time() for i in range(10): t = MyThread(i) t.start() print('the total time is %s the main thread is %s' %((time.time() - start_time), threading.current_thread()))#使用current_thread来显示当前进程,在主分支上的为主进程,在程序开始运行时产生
输出如下: running task: 0 <MyThread(Thread-1, started 123145494654976)> running task: 1 <MyThread(Thread-2, started 123145499910144)> running task: 2 <MyThread(Thread-3, started 123145505165312)> running task: 3 <MyThread(Thread-4, started 123145510420480)> running task: 4 <MyThread(Thread-5, started 123145515675648)> running task: 5 <MyThread(Thread-6, started 123145520930816)> running task: 6 <MyThread(Thread-7, started 123145526185984)> running task: 7 <MyThread(Thread-8, started 123145531441152)> running task: 8 <MyThread(Thread-9, started 123145536696320)> running task: 9 <MyThread(Thread-10, started 123145541951488)> the total time is 0.0020771026611328125 the main thread is <_MainThread(MainThread, started 140736324867008)> #可以看到当主进程执行完毕后,子进程仍然在执行 task 0 done.. task 1 done.. task 3 done.. task 2 done.. task 4 done.. task 5 done.. task 8 done.. task 6 done.. task 7 done.. task 9 done..
2、通过daemon方式产生守护进程
import threading import time class MyThread(threading.Thread): def __init__(self,num): super(MyThread,self).__init__() self.num = num def run(self): print('running task: %s %s' % (self.num,threading.current_thread())) time.sleep(2) print('task %s done..' % self.num) if __name__ == '__main__': start_time = time.time() for i in range(10): t = MyThread(i) t.setDaemon(True) #在进程执行前设置为守护进程 t.start() print('the total time is %s the main thread is %s' %((time.time() - start_time), threading.current_thread()))#使用current_thread来显示当前进程,在主分支上的为主进程,在程序开始运行时产生
输出如下: running task: 0 <MyThread(Thread-1, started daemon 123145377271808)> running task: 1 <MyThread(Thread-2, started daemon 123145382526976)> running task: 2 <MyThread(Thread-3, started daemon 123145387782144)> running task: 3 <MyThread(Thread-4, started daemon 123145393037312)> running task: 4 <MyThread(Thread-5, started daemon 123145398292480)> running task: 5 <MyThread(Thread-6, started daemon 123145403547648)> running task: 6 <MyThread(Thread-7, started daemon 123145408802816)> running task: 7 <MyThread(Thread-8, started daemon 123145414057984)> running task: 8 <MyThread(Thread-9, started daemon 123145419313152)> running task: 9 <MyThread(Thread-10, started daemon 123145424568320)> the total time is 0.003493070602416992 the main thread is <_MainThread(MainThread, started 140736324867008)> #当程序中的非守护进程执行完毕后直接退出程序
7、线程锁(互斥锁Mutex)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,这就意味着每个线程可以访问同一份数据,此时如果2个线程同时修改同一份数据,会出现什么状况?
python2下会出现异常情况:
#_*_ coding: utf-8 _*_ import time import threading def addNum(): global num #每个线程中都获取这个全局变量 print('--get num:', num) time.sleep(3) num -=1 #对此公共变量进行-1操作 num = 100 #设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: t.join() print('final num: ', num)
('--get num:', 100) ('--get num:', 100) ('--get num:', 100) ('--get num:', 100) ('final num: ', 2)
正常情况num应该为0,在python2.7上运行多次,会发现最后打印出来结果不总是0,这是因为多个线程都要对num进行减一操作,由于线程都是并发同时运行的,所以线程很有可能同时拿走了num=100这个初始变量交给cpu去运算,当A线程运行完毕后结果为99,但此时B线程运行结果也是99,两个线程同时cpu运算结果再赋值给num变量后,结果就是99,如何解决这个问题?很简单,每个线程在修改公共数据时,为了避免自己在还没修改完的时候别人也来修改此数据,可以给这个数据加一把锁,这样其他线程想修改此数据就必须等你修改完毕并把锁释放后才能再访问此数据(3.X版本自动加了锁)
加锁版本
#_*_ coding: utf-8 _*_ import time import threading def addNum(): global num #每个线程中都获取这个全局变量 print('--get num:', num) time.sleep(3) lock.acquire() #修改数据前加锁 num -=1 #对此公共变量进行-1操作 lock.release() #修改后释放 num = 100 #设定一个共享变量 thread_list = [] lock = threading.Lock() #生成全局锁 for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: t.join() print('final num: ', num)
8、GIL VS Lock
上面加的锁是用户级lock,跟GIL没有关系,下面通过一张图来理解:
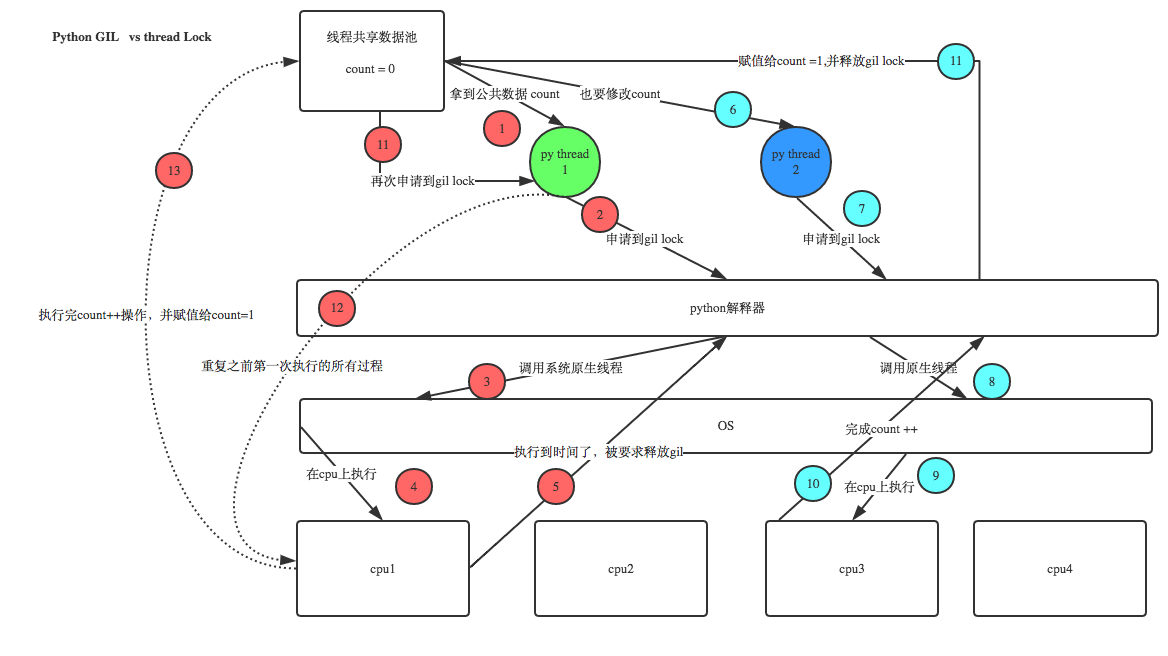
在图中可以看出,GIL是在解释器要求执行底层OS调用时增加的锁,这个操作是在第一个线程需要cpu执行指令时防止其他线程也来调用cpu而要求的操作,而线程锁是在资源分配时就开始使用的,保证两个线程不能在同一时刻拿到内存中的同样的数据,第二个进程需要在第一个进程对共享数据操作完毕才能拿到共享数据,这样保证操作不会出现乱序现象
这里需要注意的是:GIL是为了降低程序开发的复杂度,比如你写python不需要关心内存回收的问题,因为python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,没过一段时间它起wake up做一次全局轮询看哪些内存数据已经被清空,此时你自己的程序里的线程和py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器垃圾回收线程在清空这个变量过程中clearing时刻,可能一个其他线程正好又重新给这个还没来得及清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其他人都不能动,这样就解决了上述问题,这可以说是python早期版本遗留的问题
9、RLock(递归锁)
说白了就是一个大锁中还有增加子锁,举例说明:一个人家中有小区门、楼道门与房门,每个门都需要单独的锁,如果此人记忆力不好,会每次在开门时不知道需要哪个钥匙,这时就没法正确的打开门,递归锁就是这个道理,对每个锁进行单独的标示,这样保证数据在多重计算时不会乱序
import threading import time def run1(): print('grab the first part data') lock.acquire() global num num += 1 lock.release() return num def run2(): print('grab the second part data') lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print('between run1 and run2'.center(50,'#')) res2 = run2() lock.release() print(res,res2) if __name__ == '__main__': num, num2 = 0,0 lock = threading.RLock() for i in range(10): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: #active_count()表示查看当前线程数,该句表示当程序不只包括主进程时,说明还有子进程在运行 print(threading.active_count()) else: print('all threads done'.ceter(50,'#')) print(num,num2)
10、Semaphore(信号量)
互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据,比如公交车上有10个座位,只有等有空闲的座位腾出来才能坐下
import threading import time def run(num): semaphore.acquire() time.sleep(1) print('run the thread: %s ' %num) semaphore.release() if __name__ == '__main__': num = 0 semaphore = threading.BoundedSemaphore(2) #最多允许5个线程同时运行 for i in range(20): t = threading.Thread(target=run,args=(i,)) t.start() while threading.active_count() != 1: pass else: print('all thread done'.center(50,'#'))
run the thread: 0 run the thread: 1 run the thread: 2 run the thread: 3 run the thread: 5 run the thread: 4 run the thread: 6 run the thread: 7 run the thread: 8 run the thread: 9 run the thread: 10 run the thread: 11 run the thread: 12 run the thread: 13 run the thread: 15 run the thread: 14 run the thread: 17 run the thread: 16 run the thread: 18 run the thread: 19 #################all thread done##################
11、Event
Event是一个简单信号对象,可以代表一个内部的标记,线程可以通过标记来判断是否需要等待标记变化来完成操作。
event = threading.Event()
event.wait() 等待flag被设置
event.set() 设置flag
event.clear()清除设置的flag
event.is_set() 判断flag是否被设置
通过Event来实现两个或者多个线程间的交互,下面例子是一个红绿灯的例子,即启动一个线程做交通指挥灯,生成几个线程做车辆,车辆按红灯停绿灯行的规则来操控
import time import threading event = threading.Event() def lighter(): count = 0 while True: if count > 5 and count < 10: event.clear()#红灯,把标志位清空 print('�33[41;1mred light is on ....�33[0m') elif count > 10: event.set() #设置标志位,变绿灯 count = 0 else: event.set() print('�33[42;1mgreen light is on ....�33[0m') time.sleep(1) count += 1 def car(name): while True: if event.is_set(): #代表设置了标志位,代表绿灯时 print('[%s] running ....' % name) time.sleep(1) else: print('[%s] see red light, waiting....' % name) event.wait() print('�33[34;1m[%s] green light is on ,start going...�33[0m' % name) light = threading.Thread(target=lighter,) light.start() car1 = threading.Thread(target=car,args=('Tesla',)) car1.start()
12、queue
queue在多个线程需要交互数据时非常有用,通常queue分为三类:
- class queue.Queue(maxsize=0) #先入先出
- class queue.LifoQueue(maxsize=0) #后入先出
- class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级队列
maxsize是队列的长度限制,maxsize是一个整数,当queue中的长度达到maxsize后queue将被锁定直到queue中的数据被消耗掉,如果maxsize设置小于或者等于0表示queue长度是没有限制的
在优先级队列中,越低的值代表的优先级越高,通常在编写时,优先级放在前面,数据放在后面,格式为(priority_number, data)
queue的方法:
1、Queue.qsize()
2、Queue.empty()#如果队列为空,返回True
3、Queue.full() #如果队列满了返回True
4、Queue.put(item,block=True,timeout=None) #put是将数据存入队列也就是生产者的角色
在put中,如果队列满了,put操作会卡住,直到有消费者消耗了队列中的数据,如果需要立即返回可以将block设置为False或者设置一个timeout值
5、Queue.put_nowait() #等价于Queue.put(block=Flase)
6、Queue.get(block=True,timeout=None)
类似与put操作,如果队列空了切block合timeout都为默认值,get操作会卡住,直到队列中有数据,如果需要立即返回队列为空,可以将 block设置为False或者设置timeout值
7、Queue.get_nowait() #等价于Queue.get(block=False)
8、Queue.task_done()
表明以前排队任务完成,通常是被消费者线程使用的,对于每个get()操作用于获取任务,然后通知队列该任务已完成
9、Queue.join() 直到queue被消耗完毕
13、生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
import threading import queue def producter(): for i in range(10): q.put('骨头%s' %i) print('开始等待所有的骨头都被取走...') q.join() #阻塞queue直到收到task_done()信号 print('所有的骨头都被取走了...') def consumer(name): while q.qsize() > 0: print('%s 取到 ' %name ,q.get()) q.task_done() #告知join()这个任务执行完毕 q = queue.Queue() p = threading.Thread(target=producter) p.start() c1 = consumer('alex')
import time,random import queue,threading q = queue.Queue() def Producer(name): count = 0 while count < 20: time.sleep(random.randrange(4)) q.put(count) print('Producer %s has produced %s 包子.' % (name, count)) count += 1 def consumer(name): count = 0 while count < 20: time.sleep(random.randrange(3)) if not q.empty(): data = q.get() #print(data) print('�33[32;1mconsumer %s has eat %s 包子..�33[0m' %(name, data)) else: print('没有包子了'.center(15,'#')) count += 1 p1 = threading.Thread(target=Producer,args=('Jhon',)) c1 = threading.Thread(target=consumer,args=('Jack',)) p1.start() c1.start()