透视是一种通过聚合和旋转把数据行转换成数据列的技术。当透视数据时,需要确定三个要素:要在行(分组元素)中看到的元素,要在列(扩展元素)上看到的元素,要在数据部分看到的元素(聚合元素)。
SQL Server数据库中,PIVOT在帮助中这样描述滴:可以使用 PIVOT 和UNPIVOT 关系运算符将表值表达式更改为另一个表。PIVOT 通过将表达式某一列中的唯一值转换为输出中的多个列来旋转表值表达式,并在必要时对最终输出中所需的任何其余列值执行聚合。UNPIVOT 与 PIVOT 执行相反的操作,将表值表达式的列转换为列值。
数据表如下所示:

with C as ( select YEAR(orderdate) as orderyear,MONTH(orderdate) AS ordermonth,val from Sales.OrderValues ) select * from C PIVOT(sum(val) for ordermonth in ([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])) as P

扩展一下,为每一个顾客返回最近的5此订单的订单信息
with C as ( select custid,val,ROW_NUMBER() over(partition by custid order by orderdate desc,orderid desc) as rownum from Sales.OrderValues ) select * from C PIVOT(max(val) for rownum in ([1],[2],[3],[4],[5])) as P

如果我们需要把每个客户的最近的5分订单ID链接一个字符串,可以使用2012中心的concat函数
CONCAT(字串1, 字串2, 字串3, ...): 将字串1、字串2、字串3,等字串连在一起。
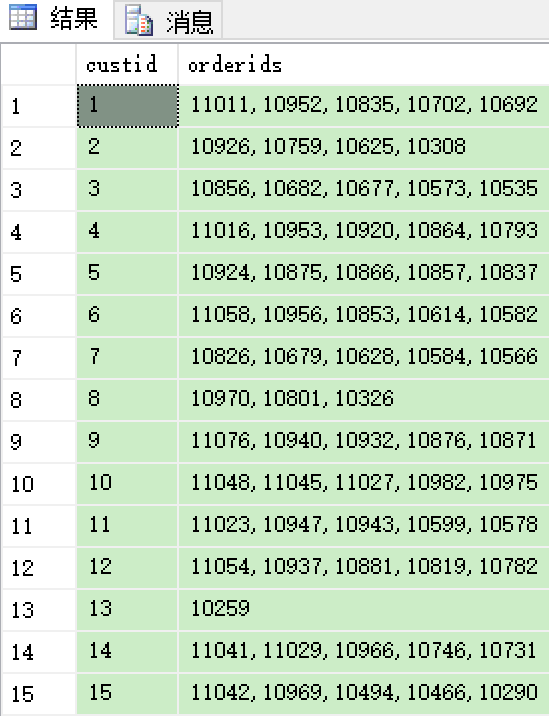
with C as ( select custid,CAST(orderid as varchar(11)) as sorderid,ROW_NUMBER() over(partition by custid order by orderdate desc,orderid desc) as rownum from Sales.OrderValues ) select custid,CONCAT([1],','+[2],','+[3],','+[4],','+[5]) as orderids from C PIVOT(max(sorderid) for rownum in ([1],[2],[3],[4],[5])) as P
https://technet.microsoft.com/zh-cn/library/ms177410(v=sql.105).aspx
这是PIVOT相关文档说明