在java线程并发处理中,有一个关键字volatile的使用目前存在很大的混淆,以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉。
Java语言是支持多线程的,为了解决线程并发的问题,在语言内部引入了 同步块 和 volatile 关键字机制。
synchronized
同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用
synchronized 修饰的方法 或者 代码块。
volatile
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile很容易被误用,用来进行原子性操作。
volatile可保证可见性,无法保证原子性,能在一定程度上保证有序性。
volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
下面看一个例子,我们实现一个计数器,每次线程启动的时候,会调用计数器inc方法,对计数器进行加一
public class Counter {
public static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++;
}
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
运行结果:Counter.count=995实际运算结果每次可能都不一样,本机的结果为:运行结果:Counter.count=995,可以看出,在多线程的环境下,Counter.count并没有期望结果是1000
很多人以为,这个是多线程并发问题,只需要在变量count之前加上volatile就可以避免这个问题,那我们在修改代码看看,看看结果是不是符合我们的期望
public class Counter {
public volatile static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++;
}
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
运行结果:Counter.count=992
运行结果还是没有我们期望的1000,下面我们分析一下原因
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这写交互
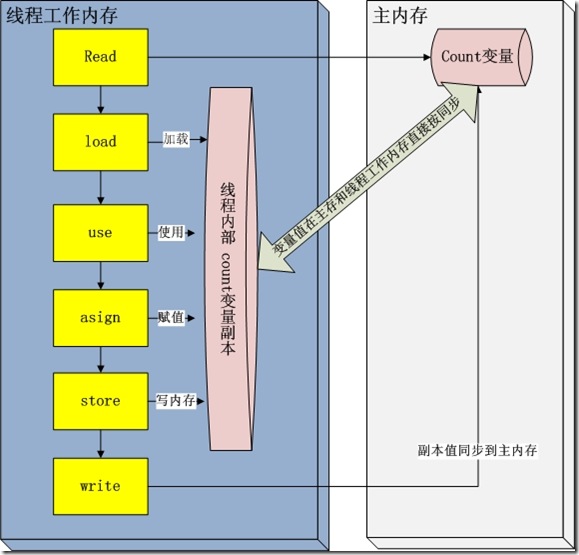
read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
//x、y为非volatile变量
//flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。