原文在这里:https://blog.csdn.net/hearthougan/article/details/76192381
距离有近有远,时间有长有短,温度有高有低,我们知道可以用米或者千米来度量距离,用时分秒可以来度量时间的长短,用摄氏度或者华氏度来度量温度的高低,那么我们常说这句话信息多,那句话信息少,那么信息的多少用什么度量呢?信息量!
信息量是度量知晓一个未知事物需要查询的信息的多少,单位是比特。比如昨天你错过一场有8匹赛马的比赛,编号为1~8号,每匹马赢的概率都一样,那么你需要获得多少信息(也就是猜测多少次)才可以知道哪匹马获胜?利用二分法,猜测三次即可,如下图:
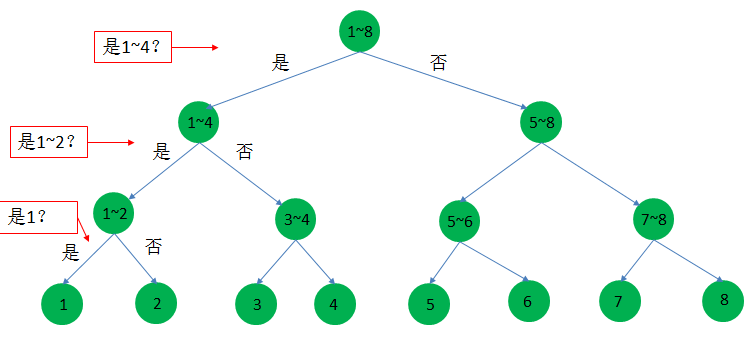
那么你需要的信息量就是3比特。信息量度量的是从未知到已知所需信息的多少,比如上图,一开始不知道哪匹马 获胜,我们开始猜测,最后猜测是1号获胜,其中需要3比特信息。
但是因为每匹马是等概率获胜的,而你又不知道哪匹马获胜,如果最后猜测出来是3号胜,这同样也需要3比特信息, 同理最后猜测出其它号的马获胜,每个都是需要3比特信息。那么现在我想计算一下,猜测出最后获胜的马,平均需要多少比特信息呢?也就是对信息量求期望(加权平均),我们给这个期望一个名字,就是信息熵。这里每匹马获胜是等概率的,当然平均也是3比特。
那么假如现在1~8号获胜的概率分别为{1/2、1/4、 1/8、 1/16、 1/64、 1/64、 1/64、 1/64},那么现在你平均要猜测对少次呢?猜测的时候,肯定是按照概率大小的来测,如下图:
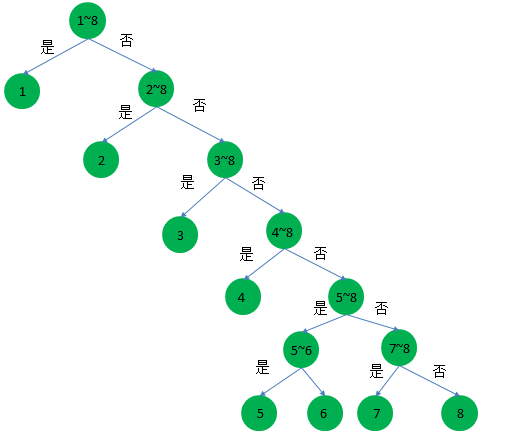
对应上图,猜测每匹马获胜至少要猜测的次数分别为1、2、3、4、6、6、6、6;那么平均要猜测多少次呢?即:
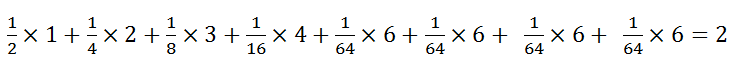
也就是猜测出获胜的马匹,平均需要2次。由于我们描述事物的时候常常使用随机变量,给出随机变量取值的概率, 那么该如求该随机变量取某个值时的信息量和该随机变量的信息熵呢?上例中我们用次数来表示信息量,对信息求期望作为信息熵,那么我们如何抽象成数学模型呢?
信息量:随机变量取某个值时,其概率倒数的对数就是信息量。
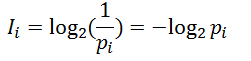
其中底数可以是2,单位是比特,底数也可以是其他,单位也相应不同,这里不予细究。
比如上例概率不等的时候,猜测6号获胜的所需的信息量为:
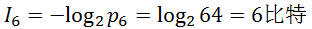
这恰好符合我们的认识。
信息熵:信息量的期望。
**
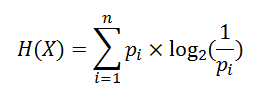
**
比如上例,设X为赛马编号,则X的信息熵为:
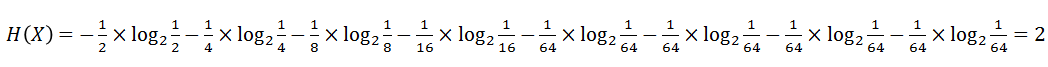
所以,这也符合我们之前的认识。
例:
如果上例还是不明白,再举一个例子,一个箱子有9个球,4个红色,3个绿色,2个黄色,如下图:
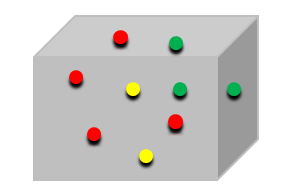
我们从中抽取一个红球、黄球、绿球所带来的信息量分别为:
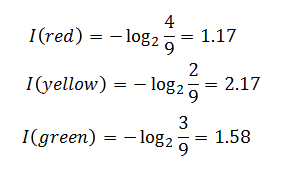
由于从箱子里抽取球,有三种可能,红、黄、绿。设X为球的颜色,则:
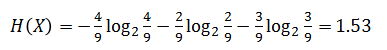
即随机变量X的信息熵为1.53。
总结:
信息量:从未知到已知所需信息的含量。
信息熵:信息量的期望。