模型微调
微调模型的方法:
1.特征提取(仅改变最后的输出层):去掉输出层,将剩下的整个网络当做一个固定的特征提取机,应用到新的数据集中
2.采用预训练模型的结构(采用预训练模型的结构,所有的权重初始化,重新训练)
3.训练特定层,冻结其他层(将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配)
浅层卷积层提取基础特征,比如边缘,轮廓等基础特征;深层卷积提取抽象特征,比如整个脸型;全连接层根据特征组合进行评分分类;
如何使用预训练模型,由数据集大小和新旧数据集(预训练的数据集和我们要解决的数据集)之间数据的相似度来决定的:
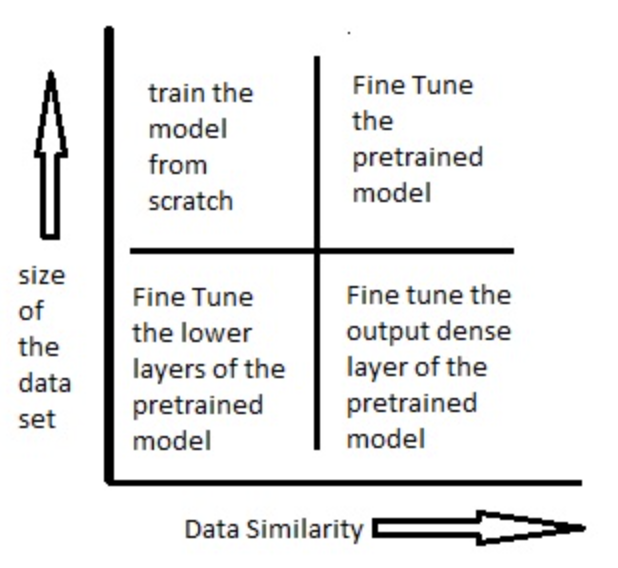
场景一:数据集小,数据相似度高;只需要将输出层改成符合问题情境下的结构,我们使用预处理模型作为模式提取器;
场景二:数据集小,数据相似度不高;冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,最后一层也需要根据相应的输出格式来进行修改;(新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补)
场景三:数据集大,数据相似度不高;将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练;
场景四:数据集大,数据相似度高;保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练;
注意事项:
1.在修改模型的过程中,我们通过会采用比一般训练模型更低的学习速率,预先训练的权重相比随机初始化的权重更不错,所以通常不会过快的扭曲他们,一般将初始学习率比从头训练的学习率小十倍;
2.小数据集(小于参数数量)上训练CNN会极大地影响CNN泛化的能力,通常会导致过度拟合
什么情况下使用微调:
(1)数据集相似;
(2)自己搭建或cnn模型正确率过低;
(3)数据集相似,数据量太少;
(4)计算资源太少;
Mobilenetv1:
虽然MobileNet网络结构和延迟已经比较小了,但是很多时候在特定应用下还是需要更小更快的模型,为此引入了宽度因子 alpha(Width Mutiplier)在每一层对网络的输入输出通道数进行缩减,输入通道数由 M 到 alpha*M,输出通道数由 N 到 alpha*N,变换后的计算量变为: DK x DK x alpha x M x DF x DF + alpha x M x alpha x N x DF x DF;
通常alpha在(0, 1]之间,比较典型的值有 1, 0.75, 0.5 和 0.25。计算量和参数数量减少程度与未使用宽度因子之前提高了1/alpha**2倍。