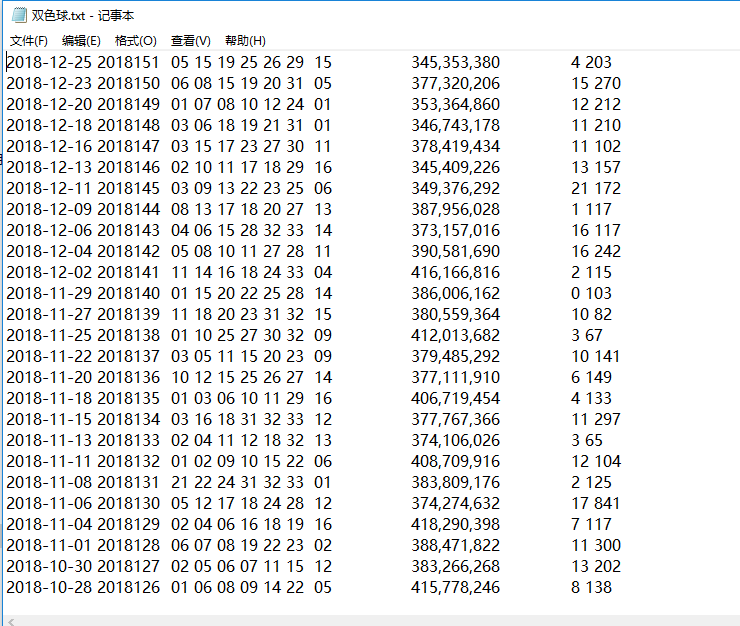
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件。
实例环境:python3.7
BeautifulSoup库、xlwt库(需手动安装)
urllib库、re库(内置的python库,无需手动安装)
实例网站:
第一步,点击链接http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html进入网站,查看网站基本信息,注意一共要爬取118页数据。
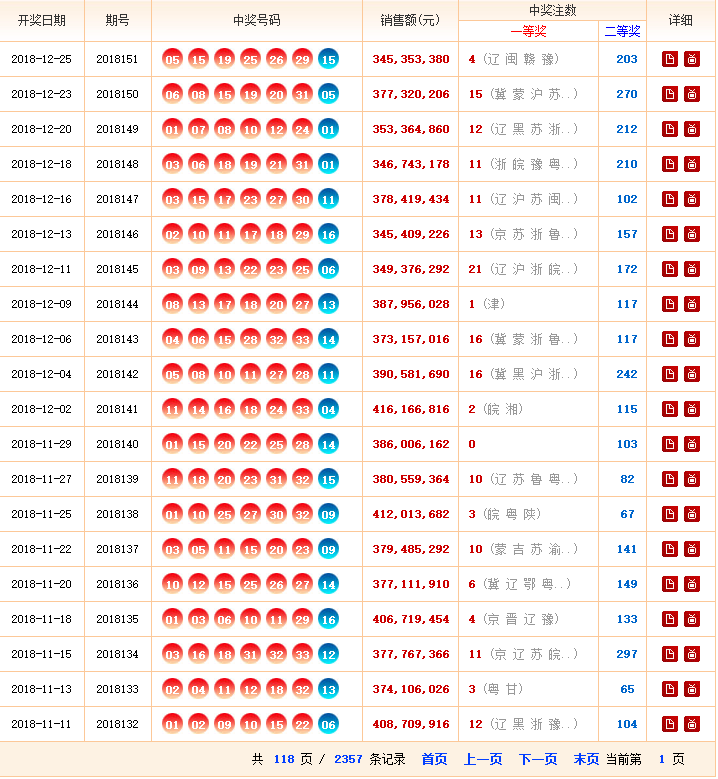
第二步,查看网页源代码,熟悉网页结构,标签等信息。

实例思路:
一个爬虫程序的结构:
1、调度模块(Scheduler):安排发起网络请求的策略
2、网络模块(network):发起网络请求,并接受服务器返回
3、爬虫模块(Spider):解析、爬取数据
4、Item模块:定义爬取的数据项
5、Piplines模块:对已经爬取的数据做后续处理(存入数据库、存入文件系统、传递给流式处理框架,等等)
下面的示例程序基本实现了上述几个模板
实例代码:
getWinningNum.py
#encoding=utf-8 import re from bs4 import BeautifulSoup import urllib.request from save2excel import SavaBallDate #4、 Item模块 定义爬取的数据项 class DoubleColorBallItem(object): date = None order = None red1 = None red2 = None red3 = None red4 = None red5 = None red6 = None blue = None money = None firstPrize = None secondPrize = None class GetDoubleColorBallNumber(object): def __init__(self): self.urls = [] self.urls = self.getUrls() self.items = self.spider(self.urls) self.pipelines(self.items) SavaBallDate(self.items) # 获取 urls 的函数 def getUrls(self): URL = r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html' htmlContent = self.getResponseContent(URL) soup = BeautifulSoup(htmlContent, 'lxml') tag = soup.find_all('p')[-1] pages = tag.strong.get_text() for i in range(1, int(pages)+1): url = r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_' + str(i) + '.html' self.urls.append(url) return self.urls #3、 网络模块(NETWORK)发起网络请求,并接受服务器返回 def getResponseContent(self, url): try: response = urllib.request.urlopen(url) except URLError as e: raise e else: return response.read().decode("utf-8") #3、 爬虫模块(Spider) 解析、爬取数据 def spider(self,urls): items = [] for url in urls: try: htmlContent = self.getResponseContent(url) soup = BeautifulSoup(htmlContent, 'lxml') tags = soup.find_all('tr', attrs={}) for tag in tags: if tag.find('em'): item = DoubleColorBallItem() tagTd = tag.find_all('td') item.date = tagTd[0].get_text() item.order = tagTd[1].get_text() tagEm = tagTd[2].find_all('em') item.red1 = tagEm[0].get_text() item.red2 = tagEm[1].get_text() item.red3 = tagEm[2].get_text() item.red4 = tagEm[3].get_text() item.red5 = tagEm[4].get_text() item.red6 = tagEm[5].get_text() item.blue = tagEm[6].get_text() item.money = tagTd[3].find('strong').get_text() item.firstPrize = tagTd[4].find('strong').get_text() item.secondPrize = tagTd[5].find('strong').get_text() items.append(item) except Exception as e: raise e # print(str(e)) return items # Piplines模块:对已经爬取的数据做后续处理(存入数据库、存入文件系统、传递给流式处理框架,等等) def pipelines(self,items): fileName = u'双色球.txt' with open(fileName, 'w') as fp: # a 为追加 w 为覆盖若存在 for item in items: fp.write('%s %s %s %s %s %s %s %s %s %s %s %s ' %(item.date,item.order,item.red1,item.red2,item.red3,item.red4,item.red5,item.red6,item.blue,item.money,item.firstPrize,item.secondPrize)) if __name__ == '__main__': GDCBN = GetDoubleColorBallNumber()
save2excel.py
#encoding=utf-8 import xlwt class SavaBallDate(object): def __init__(self, items): self.items = items self.run(self.items) def run(self,items): fileName = u'双色球.xls' book = xlwt.Workbook(encoding='utf-8') sheet=book.add_sheet('ball', cell_overwrite_ok=True) sheet.write(0, 0, u'开奖日期') sheet.write(0, 1, u'期号') sheet.write(0, 2, u'红1') sheet.write(0, 3, u'红2') sheet.write(0, 4, u'红3') sheet.write(0, 5, u'红4') sheet.write(0, 6, u'红5') sheet.write(0, 7, u'红6') sheet.write(0, 8, u'蓝') sheet.write(0, 9, u'销售金额') sheet.write(0, 10, u'一等奖') sheet.write(0, 11, u'二等奖') i = 1 while i <= len(items): item = items[i-1] sheet.write(i, 0, item.date) sheet.write(i, 1, item.order) sheet.write(i, 2, item.red1) sheet.write(i, 3, item.red2) sheet.write(i, 4, item.red3) sheet.write(i, 5, item.red4) sheet.write(i, 6, item.red5) sheet.write(i, 7, item.red6) sheet.write(i, 8, item.blue) sheet.write(i, 9, item.money) sheet.write(i, 10, item.firstPrize) sheet.write(i, 11, item.secondPrize) i += 1 book.save(fileName) if __name__ == '__main__': pass
实例结果:
数据量有点大,可能需要等一会儿,下面为程序运行结束后的文件夹。

__pycache__文件夹为程序运行自动生成的文件夹,不用管。