实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件。
实例环境:python3.7
BeautifulSoup库、XPath(需手动安装)
urllib库(内置的python库,无需手动安装)
实例网站:
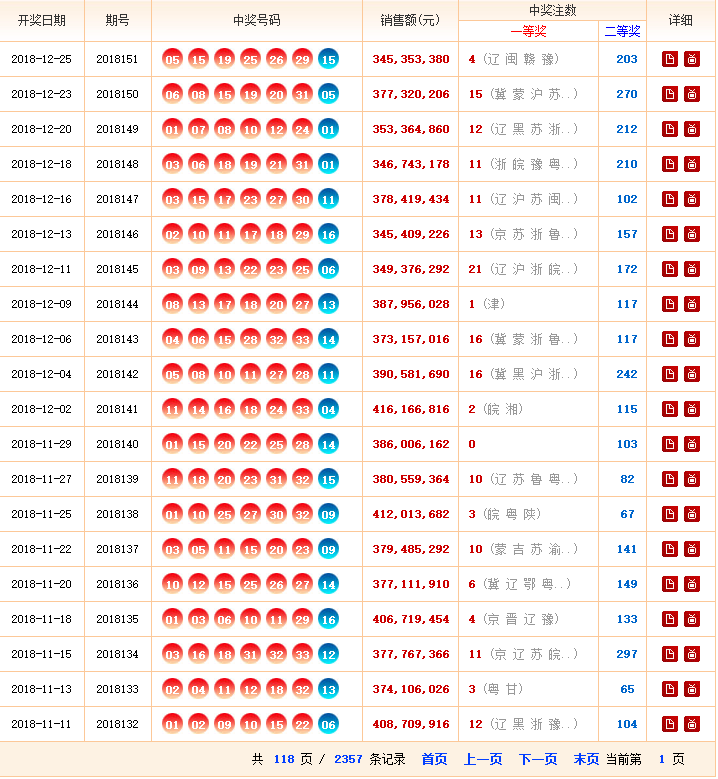
第一步,点击链接http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html进入网站,查看网站基本信息,注意一共要爬取118页数据。
第二步,查看网页源代码,熟悉网页结构,标签等信息。

实例代码:
#encoding=utf-8
#pip install lxml
from bs4 import BeautifulSoup
import urllib.request
from lxml import etree
class GetDoubleColorBallNumber(object):
def __init__(self):
self.urls = []
self.getUrls()
self.items = self.spider(self.urls)
self.pipelines(self.items)
def getUrls(self):
URL = r'http://kaijiang.zhcw.com/zhcw/html/ssq/list.html'
htmlContent = self.getResponseContent(URL)
soup = BeautifulSoup(htmlContent, 'html.parser')
tag = soup.find_all('p')[-1]
pages = tag.strong.get_text()
pages = '3'
for i in range(2, int(pages)+1):
url = r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_' + str(i) + '.html'
self.urls.append(url)
#3、 网络模块(NETWORK)
def getResponseContent(self, url):
try:
response = urllib.request.urlopen(url)
except urllib.request.URLError as e:
raise e
else:
return response.read().decode("utf-8")
#3、爬虫模块(Spider)
def spider(self,urls):
items = []
for url in urls:
try:
html = self.getResponseContent(url)
xpath_tree = etree.HTML(html)
trTags = xpath_tree.xpath('//tr[not(@*)]') # 匹配所有tr下没有任何属性的节点
for tag in trTags:
# if tag.xpath('../html'):
# print("找到了html标签")
# if tag.xpath('/td/em'):
# print("****************")
#如果存在em子孙节点
if tag.xpath('./td/em'):
item = {}
item['date'] = tag.xpath('./td[1]/text()')[0]
item['order'] = tag.xpath('./td[2]/text()')[0]
item['red1'] = tag.xpath('./td[3]/em[1]/text()')[0]
item['red2'] = tag.xpath('./td[3]/em[2]/text()')[0]
item['red3'] = tag.xpath('./td[3]/em[3]/text()')[0]
item['red4'] = tag.xpath('./td[3]/em[4]/text()')[0]
item['red5'] = tag.xpath('./td[3]/em[5]/text()')[0]
item['red6'] = tag.xpath('./td[3]/em[6]/text()')[0]
item['blue'] = tag.xpath('./td[3]/em[7]/text()')[0]
item['money'] = tag.xpath('./td[4]/strong/text()')[0]
item['first'] = tag.xpath('./td[5]/strong/text()')[0]
item['second'] = tag.xpath('./td[6]/strong/text()')[0]
items.append(item)
except Exception as e:
print(str(e))
raise e
return items
def pipelines(self,items):
fileName = u'双色球.txt'
with open(fileName, 'w') as fp:
for item in items:
fp.write('%s %s %s %s %s %s %s %s %s %s %s %s
'
%(item['date'],item['order'],item['red1'],item['red2'],item['red3'],item['red4'],item['red5'],item['red6'],item['blue'],item['money'],item['first'],item['second']))
if __name__ == '__main__':
GDCBN = GetDoubleColorBallNumber()
实例结果:

