8、Hadoop输入输出格式
除了 Spark 封装的格式之外,也可以与任何 Hadoop 支持的格式交互。Spark 支持新旧两套Hadoop 文件 API,提供了很大的灵活性。
要使用新版的 Hadoop API 读入一个文件,需要告诉 Spark 一些东西。 newAPIHadoopFile接收一个路径以及三个类。第一个类是“格式”类,代表输入格式。相似的函数hadoopFile() 则用于使用旧的 API 实现的 Hadoop 输入格式。第二个类是键的类,最后一个类是值的类。如果需要设定额外的 Hadoop 配置属性,也可以传入一个 conf 对象。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("hadoop").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val inputFile = "pandainfo.json"//读取csv文件
// 新式API
val job = new Job()
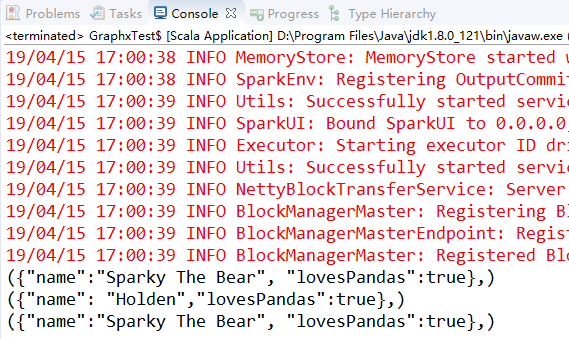
val data = sc.newAPIHadoopFile("pandainfo.json", classOf[KeyValueTextInputFormat], classOf[Text], classOf[Text], job.getConfiguration)
data.foreach(println)
data.saveAsNewAPIHadoopFile("hadoop_json", classOf[Text], classOf[Text], classOf[TextOutputFormat[Text,Text]], job.getConfiguration)
// // 旧式API
// val input = sc.hadoopFile[Text,Text,KeyValueTextInputFormat](inputFile).map{
// case(x,y) => (x.toString,y.toString)
// }
// input.foreach(println)
}
}

9、文件压缩
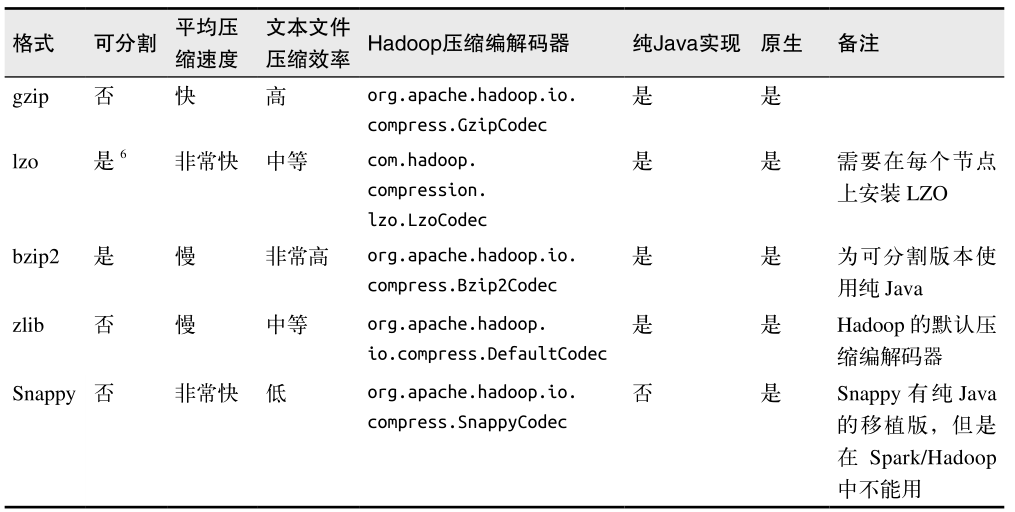
在大数据工作中,我们经常需要对数据进行压缩以节省存储空间和网络传输开销。对于大多数 Hadoop 输出格式来说,我们可以指定一种压缩编解码器来压缩数据。我们已经提过,Spark 原生的输入方式( textFile 和 sequenceFile )可以自动处理一些类型的压缩。在读取压缩后的数据时,一些压缩编解码器可以推测压缩类型。
这些压缩选项只适用于支持压缩的 Hadoop 格式,也就是那些写出到文件系统的格式。写入数据库的 Hadoop 格式一般没有实现压缩支持。如果数据库中有压缩过的记录,那应该是数据库自己配置的。表列出了可用的压缩选项。
三、文件系统
Spark 支持读写很多种文件系统,可以使用任何我们想要的文件格式。
本地/“常规”文件系统:Spark 支持从本地文件系统中读取文件,不过它要求文件在集群中所有节点的相同路径下都可以找到。
Amazon S3:将一个以s3n://开头的路径以s3n://bucket/path-within-bucket的形式传给Spark的输入方法。
HDFS:在Spark中使用HDFS只需要将输入路径输出路径指定为hdfs://master:port/path就可以了。
四、Spark SQL中的结构化数据
1、Apache Hive
Apache Hive 是 Hadoop 上的一种常见的结构化数据源。Hive 可以在 HDFS 内或者在其他存储系统上存储多种格式的表。这些格式从普通文本到列式存储格式,应有尽有。SparkSQL 可以读取 Hive 支持的任何表。
要把 Spark SQL 连接到已有的 Hive 上,你需要提供 Hive 的配置文件。你需要将 hive-site.xml 文件复制到 Spark 的 ./conf/ 目录下。这样做好之后,再创建出 HiveContext 对象,也就是 Spark SQL 的入口,然后你就可以使用 Hive 查询语言(HQL)来对你的表进行查询,并以由行组成的 RDD 的形式拿到返回数据。
//用scala创建HiveContext并查询数据
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val hiveCtx = new HiveContext(sc)
val rows = hiveCtx.sql("SELECT name,age FROM users")
val firstRow = rows.first()
println(firstRow.getString(0)) // 字段0是name字段
2、JSON
如果你有记录间结构一致的 JSON 数据,Spark SQL 也可以自动推断出它们的结构信息,并将这些数据读取为记录,这样就可以使得提取字段的操作变得很简单。要读取 JSON 数据,首先需要和使用 Hive 一样创建一个 HiveContext 。(不过在这种情况下我们不需要安装好 Hive,也就是说你也不需要 hive-site.xml 文件。)然后使用 HiveContext.jsonFile 方法来从整个文件中获取由 Row 对象组成的 RDD。除了使用整个 Row 对象,你也可以将 RDD数据注册为一张表,然后从中选出特定的字段。例如:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext
object Test {
def main(args: Array[String]): Unit = {
// 再Scala中使用SparkSQL读取json数据
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val hiveCtx = new HiveContext(sc)
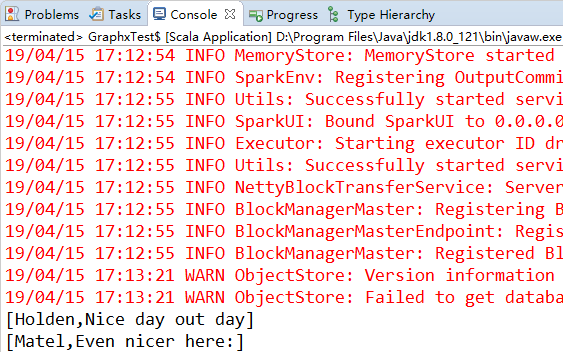
val input = hiveCtx.jsonFile("tweets.json")
input.registerTempTable("tweets")
val results = hiveCtx.sql("SELECT user.name,text FROM tweets")
results.collect().foreach(println)
}
}

3、数据库
通过数据库提供的 Hadoop 连接器或者自定义的 Spark 连接器,Spark 可以访问一些常用的数据库系统。常见的有四种常见的连接器:Java数据库连接、Cassandra、HBase、Elasticsearch。下面演示如何使用 jdbcRDD 连接 MySQL 数据库。
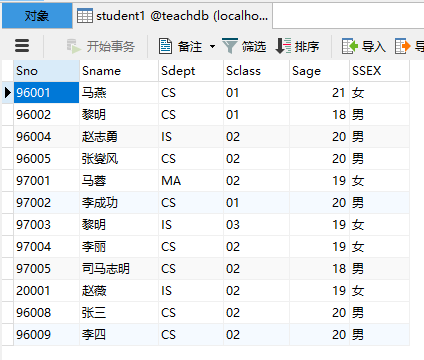
首先我们有一个名为teachdb的数据库,里面有一张名为student1的表,有如下数据:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val sqlContext = new SQLContext(sc)
val mysql = sqlContext.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/teachdb")
.option("dbtable", "student1").option("driver", "com.mysql.jdbc.Driver") // 注意这儿需要导入"mysql-connector-java-5.1.40-bin"包
.option("user", "root").option("password", "0000").load()
mysql.registerTempTable("student1")
mysql.sqlContext.sql("select * from student1").collect().foreach(println)
}
}
这篇博文主要来自《Spark快速大数据分析》这本书里面的第五章,内容有删减,还有本书的一些代码的实验结果。