倒排索引是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
一、实例描述
倒排索引简单地就是,根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他的一些策略(如页面点击投票率)等来给你返回结果。这个过程中,倒排索引就起到很关键的作用。
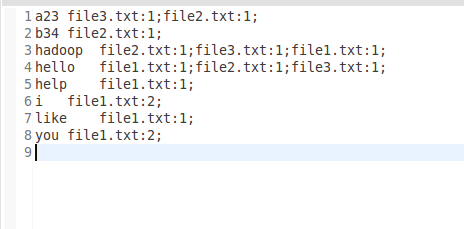
样例输入:

样例输出:
二、设计思路
倒排索引涉及几个过程:Map过程,Combine过程,Reduce过程。
Map过程:
当你把需要处理的文档上传到hdfs时,首先默认的TextInputFormat类对输入的文件进行处理,得到文件中每一行的偏移量和这一行内容的键值对<偏移量,内容>做为map的输入。在改写map函数的时候,我们就需要考虑,怎么设计key和value的值来适合MapReduce框架,从而得到正确的结果。由于我们要得到单词,所属的文档URL,词频,而<key,value>只有两个值,那么就必须得合并其中得两个信息了。这里我们设计key=单词+URL,value=词频。即map得输出为<单词+URL,词频>,之所以将单词+URL做为key,时利用MapReduce框架自带得Map端进行排序。
Combine过程:
Combine过程将key值相同得value值累加,得到一个单词在文档上得词频。但是为了把相同得key交给同一个reduce处理,我们需要设计为key=单词,value=URL+词频。
Reduce过程:
Reduce过程其实就是一个合并的过程了,只需将相同的key值的value值合并成倒排索引需要的格式即可。
三、程序代码
程序代码如下:
1 import java.io.IOException; 2 import java.util.StringTokenizer; 3 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 import org.apache.hadoop.util.GenericOptionsParser; 15 16 17 public class InvertedIndex { 18 19 public static class Map extends Mapper<LongWritable, Text, Text, Text>{ 20 private static Text word = new Text(); 21 private static Text one = new Text(); 22 23 @Override 24 protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, Text>.Context context) 25 throws IOException, InterruptedException { 26 // super.map(key, value, context); 27 String fileName = ((FileSplit)context.getInputSplit()).getPath().getName(); 28 StringTokenizer st = new StringTokenizer(value.toString()); 29 while (st.hasMoreTokens()) { 30 word.set(st.nextToken()+" "+fileName); 31 context.write(word, one); 32 } 33 } 34 } 35 36 public static class Combine extends Reducer<Text, Text, Text, Text>{ 37 private static Text word = new Text(); 38 private static Text index = new Text(); 39 40 @Override 41 protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context) 42 throws IOException, InterruptedException { 43 // super.reduce(arg0, arg1, arg2); 44 String[] splits = key.toString().split(" "); 45 if (splits.length != 2) { 46 return ; 47 } 48 long count = 0; 49 for(Text v:values){ 50 count++; 51 } 52 word.set(splits[0]); 53 index.set(splits[1]+":"+count); 54 context.write(word, index); 55 } 56 } 57 58 public static class Reduce extends Reducer<Text, Text, Text, Text>{ 59 private static StringBuilder sub = new StringBuilder(256); 60 private static Text index = new Text(); 61 62 @Override 63 protected void reduce(Text word, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context) 64 throws IOException, InterruptedException { 65 // super.reduce(arg0, arg1, arg2); 66 for(Text v:values){ 67 sub.append(v.toString()).append(";"); 68 } 69 index.set(sub.toString()); 70 context.write(word, index); 71 sub.delete(0, sub.length()); 72 } 73 } 74 75 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 76 Configuration conf = new Configuration(); 77 String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); 78 if(otherArgs.length!=2){ 79 System.out.println("Usage:wordcount <in> <out>"); 80 System.exit(2); 81 } 82 Job job = new Job(conf,"Invert Index "); 83 job.setJarByClass(InvertedIndex.class); 84 85 job.setMapperClass(Map.class); 86 job.setCombinerClass(Combine.class); 87 job.setReducerClass(Reduce.class); 88 89 job.setMapOutputKeyClass(Text.class); 90 job.setMapOutputValueClass(Text.class); 91 job.setOutputKeyClass(Text.class); 92 job.setOutputValueClass(Text.class); 93 94 FileInputFormat.addInputPath(job,new Path(args[0])); 95 FileOutputFormat.setOutputPath(job, new Path(args[1])); 96 System.exit(job.waitForCompletion(true)?0:1); 97 } 98 99 }