最近在学习python爬虫,看到网上有很多关于模拟豆瓣登录的例子,随意找了一个试了下,发现不能运行,对比了一下代码和豆瓣网站,发现原来是豆瓣网站做了修改,增加了反爬措施。
首先看下要模拟登录的网站:
打开开发者模式:

在账号和密码随意填入数据:
发现会发送一个post请求:
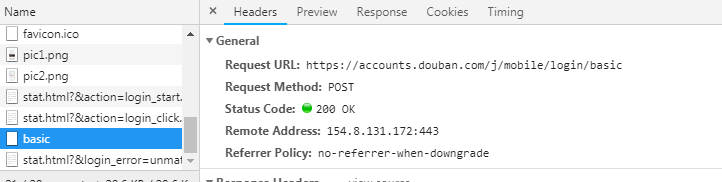
ur是:https://accounts.douban.com/j/mobile/login/basic
数据格式是:
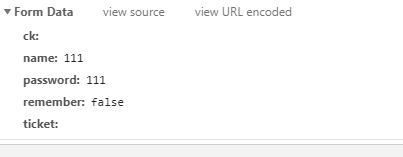
于是可以来编写代码:
import requests
def main():
url_basic = 'https://accounts.douban.com/j/mobile/login/basic'
url = 'https://www.douban.com/'
ua_headers = { "User-Agent":'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
data = {
'ck': '',
'name': '自己的账号',
'password': '自己的密码',
'remember': 'false',
'ticket': ''
}
s = requests.session()
s.post(url=url_basic, headers=ua_headers, data=data)
response = s.get(url=url, headers=ua_headers)
with open('douban.html' , 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
main()
第一步:
创建 s = requests.session()
作用是跨请求保持参数,也就是说s这个session对象所发出的所有请求之间会保持cookies
第二步:
用创建好的session对象携带账号,密码去发送post请求。
由于改版后的豆瓣返回的是一个josn数据,而不是像以前一样重定向,所以需要我们来重定向。
第三步:
携带登录成功保存的cookie去访问首页,就会得到你自己的首页.
最后得到个人首页: