大数据调优总体方向:CPU,内存以及IO(Disk,Network)三个方面来进行。
对于多次使用的数据(RDD/DataFrame),通过cache()或者persis()来进行缓存,避免每一次都从数据源获取(减少磁盘IO);
系统资源优化
如下参数可以进行调优(可以参见附录中介绍的spark和yarn的交互内容):
num-executors:executor数量(Spark Job的进程数量);结合executor-core进行考虑,两者相乘的量[40,100],尽量不要超过YARN的总core的指定比例,有的说25%,有的说50%
executor-memory:executor内存上线,建议8G左右,申请的内存总量(num-executors*executor-memory)不要超过YARN的80%;
executor-cores:executor的核数(线程数),即并行执行task的数据量,建议值4个,总量不要超过YARN总核数的50%;
driver-memory:默认1G,足以。
spark.default.parallelizm:spark的并行度,默认数是待处理数据的hdfs的datablock数量;但是如果数据量很大的话明显不合适,task数量>>core的数量会拉低效率;spark官方建议要么是和分配的从cores数量保持一致,或者是2个(根据spairk的官方tune(http://spark.apache.org/docs/latest/tuning.html#level-of-parallelism)建议,每个core最佳的任务数是2~3个)。这个地方似乎有矛盾,后续有时间再查一下。
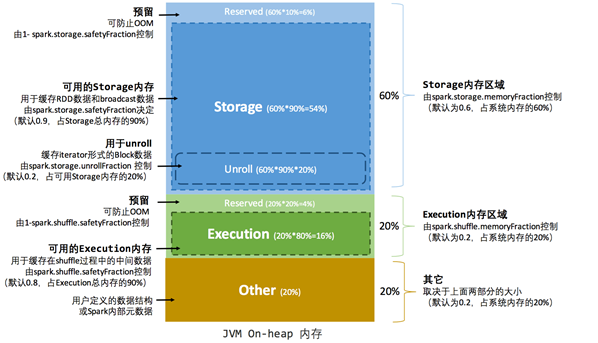
spark.storage.memoryFraction:persis()和cache()所占用的内存比例,默认是60%;根据应用场景进行调整;
spark.shuffle.memoryFraction:用于存放shuffle过来的数据的内存的比例,默认是20%;根据应用场景进行调整。
操作(开发)优化
persisit/ cache
当数据需要进行复用的时候,最好进行缓存;
persis的类型如下:
|
级别 |
使用空间 |
使用空间 |
是否在内存中 |
是否在磁盘上 |
备注 |
|
MEMORY_ONLY |
高 |
低 |
是 |
否 |
|
|
MEMORY_ONLY_2 |
高 |
低 |
是 |
否 |
数据存2份 |
|
MEMORY_ONLY_SER |
低 |
高 |
是 |
否 |
数据序列化 |
|
MEMORY_ONLY_SER_2 |
低 |
高 |
是 |
否 |
数据序列化,数据存2份 |
|
MEMORY_AND_DISK |
高 |
中等 |
部分 |
部分 |
如果数据在内存中放不下,则溢写到磁盘 |
|
MEMORY_AND_DISK_2 |
高 |
中等 |
部分 |
部分 |
数据存2份 |
|
MEMORY_AND_DISK_SER |
低 |
高 |
部分 |
部分 |
|
|
MEMORY_AND_DISK_SER_2 |
低 |
高 |
部分 |
部分 |
数据存2份 |
|
DISK_ONLY |
低 |
高 |
否 |
是 |
|
|
DISK_ONLY_2 |
低 |
高 |
否 |
是 |
数据存2份 |
数据结构(类型)优化
能用string就不要用object,能用int就不要用string;
序列化优化
序列化采用KryoSerializer,采用该序列化库,需要对序列化的对象进行注册;
评估内存消耗
创建RDD,绑定数据后cache,然后到web UI的storage里面能够看到该RDD的数据量是多大;
另外在代码中通过 SizeEstimator.estimate来进行内存对象占用空间估计值;
广播大变量
算子优化
reduceByKey,aggregateByKey替换groupByKey
算子上面考虑:reduceByKey以及aggregateByKey要优于groupByKey,因为前面两者都会在本地做本地合并之后再汇聚到了reduce节点进行全局汇聚,无论是内存还是CPU,还是IO都会减少。groupByKey则是在map节点查到符合条件得数据后直接shuffle到reduce节点;之后完全依赖于reduce节点对数据进行全局合并。
broadcast + map取代join
rdd1.join(rdd2),将会导致数据shuffle,shffle并不数据传输那么简单,是一系列复杂的操作;所以即使数据传输,采用boradcast方式也是要比shuffle划算的多。所以如果是join操作可以考虑采用broadcast方式来实现。采用broadcast比较适合小数据量的情况,这是因为broadcast是会为每一个executor都传输这个对象,所以如果本身比较大,这样IO开销其实和shuffle已经差不多了。
不过broadcast流程是首先将要传输的数据传输到driv节点,然后再有Driver节点通过Torrent的方式进行传输(就是迅雷的那种种子模式)到所有的executor节点,所以这个过程其实是冗余传输(可能并不是所有的节点都需要该数据),但是因为基于种子的传输速度非常快,所以很多时候没如果数据量比较小还是一种很高效的方式。
broadcast有两种方式,第一种是编程方式;另外一种是通过sparkSQL的方式(代码参见附录)。对于sql方式要注意一个配置:
spark.sql.autoBroadcastJoinThreshold,这个参数用于设置广播的数据上限,因为如果数据量太大,广播的方式也是很消耗网络带宽的,默认值是10M,可以根据情况来调大这个阈值。
map vs. mappartition
采用mappatition来进行数据操作。map是在元素级别的数据操作,一次性只处理一个元素;mappartition则是在分区级别的数据操作,一次mapPartition的函数将需要加载该分区全部的数据来进行操作。
所以立足于mappartition来进行编程更加合理;但是有一点mappartition更加容易OOM,这个是因为什么呢?因为map函数一次只处理一个元素,所以不存在一次加载数据问题,但是mapPartition则是每个分区一次性加载该分区数据,然后再进行便利操作。
map和mapPartition实现比较请见附录。
和mapPartition类似的还有一个foreachPartition,两者都是基于分区的数据角度来处理数据,区别在于mapPartition会有一个累积的返回值,foreachParition只是在分区上面进行数据处理,没有返回值。另外一点小贴士:这两个基于分区的操作很多时候都会用到迭代器,注意不啊哟实用iterator里面的size()函数,因为一旦调用了size(),迭代器里面的数据就会比从头到尾走一遍,这样指针就会放到末尾,当你真正通过next()函数来进行数据处理的时候会发现数为空(因为指针在末尾)。
所以一般情况查询处理采用mapPartition,如果是插入更新等操作,采用foreachPartition操作。
使用coalesce函数进行数据分区收缩
分区收缩本质是减小并行度(分区和并行度在spark里面是等义词);当数据因为Filter等操作变小了之后,可以通过coalesce函数来对分区进行收缩,提供后续查询处理操作。coalesce设有两种模式shuffle=true/false,对于收缩shuffle可以设置为false或者true,对于增加分区必须要shuffle=false(因为子RDD可能会和父RDD多个分区发生关系)。这里讲一下分区变化将会导致hash值发生变化,所以其实分区无论扩张还是收缩其实都是有shuffle和不shuffle两种模式;如果是shuffle,则是全局的数据重新组织;如果不shuffle,相当于只是在本地进行数据重新组织,但是其实都是增加/减小并行度。
不过对于repartition而言,则是特指shuffle=true,即全局数据重排的模式;如果是不shuffle,则是一般采用coalesce函数来进行处理。
repartitionAndSortWithPartitions
此函数的优势在于在各个分区map的时候就进行了排序,shuflle之后到各个重排节点已经是排好序的了,这样在重新组织排序的时候工作量将会减轻很多;充分利用了map节点的资源,减轻reduce节点的压力。这个其实和reduceByKey的策略是一样的。
多用treeReduce以及treeAggregate
对于shuffle类算子,最终数据是要汇聚到driver节点的,所以如果只是进行粗粒度汇聚就集合到driver节点将会导致driver节点OOM,为了避免这种情况,可以使用treeReduce以及treeAggregate,他们原理就是进行多次reduce,最终到达driver的点是经过多次reduce操作的结果。参看下图:
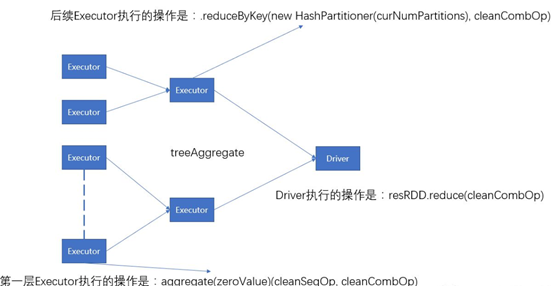
形成树状的层次操作;所以从效率来讲并没有提高,但是最终受益的driver节点,处理的数据量减少了。
附录
spark分区shuffle与不shuffle
有的为了解决数据倾斜问题,就是希望能够进行shuffle,多个分区更加容易使得数据均匀,所以通过增加分区实现数据合并,减轻数据倾斜。coalesce()在分区扩容shuffle还为true的情况下是无效的;这个也是为什么要把扩容封装为repartition的原因,扩容shuffle只能是true;但是对于收缩而言,既可以shuffle,也可以是非shuffle,即全局重排
1 scala> var data = sc.parallelize(List(1,2,3,4)) 2 data: org.apache.spark.rdd.RDD[Int] = 3 ParallelCollectionRDD[45] at parallelize at <console>:12 4 5 scala> data.partitions.length 6 res68: Int = 30 7 8 scala> val result = data.coalesce(2, false) 9 result: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[57] at coalesce at <console>:14 10 11 scala> result.partitions.length 12 res77: Int = 2 13 14 scala> result.toDebugString 15 res75: String = 16 (2) CoalescedRDD[57] at coalesce at <console>:14 [] 17 | ParallelCollectionRDD[45] at parallelize at <console>:12 [] 18 19 scala> val result1 = data.coalesce(2, true) 20 result1: org.apache.spark.rdd.RDD[Int] = MappedRDD[61] at coalesce at <console>:14 21 22 scala> result1.toDebugString 23 res76: String = 24 (2) MappedRDD[61] at coalesce at <console>:14 [] 25 | CoalescedRDD[60] at coalesce at <console>:14 [] 26 | ShuffledRDD[59] at coalesce at <console>:14 [] 27 +-(30) MapPartitionsRDD[58] at coalesce at <console>:14 [] 28 | ParallelCollectionRDD[45] at parallelize at <console>:12 []
repartitionAndSortWithPartition
在使用这个函数的时候,注意ordering是一个隐式变量:
1 scala> var data = sc.parallelize(List(1,2,3,4)) 2 data: org.apache.spark.rdd.RDD[Int] = 3 ParallelCollectionRDD[45] at parallelize at <console>:12 4 5 scala> data.partitions.length 6 res68: Int = 30 7 8 scala> val result = data.coalesce(2, false) 9 result: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[57] at coalesce at <console>:14 10 11 scala> result.partitions.length 12 res77: Int = 2 13 14 scala> result.toDebugString 15 res75: String = 16 (2) CoalescedRDD[57] at coalesce at <console>:14 [] 17 | ParallelCollectionRDD[45] at parallelize at <console>:12 [] 18 19 scala> val result1 = data.coalesce(2, true) 20 result1: org.apache.spark.rdd.RDD[Int] = MappedRDD[61] at coalesce at <console>:14 21 22 scala> result1.toDebugString 23 res76: String = 24 (2) MappedRDD[61] at coalesce at <console>:14 [] 25 | CoalescedRDD[60] at coalesce at <console>:14 [] 26 | ShuffledRDD[59] at coalesce at <console>:14 [] 27 +-(30) MapPartitionsRDD[58] at coalesce at <console>:14 [] 28 | ParallelCollectionRDD[45] at parallelize at <console>:12 []
所以在使用这个函数的时候,你的自定义函数也是需要隐式的。
1 val sparkConf = new SparkConf().setAppName("test").setMaster("local[4]") 2 val sc = new SparkContext(sparkConf) 3 val wordsRDD: RDD[String] = sc.textFile("D:\Spark_数据\numbers_data.txt") 4 val resultRDD = wordsRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).map(each => (each._2, each._1)) 5 /** 6 * key怎么排序,在这里定义 7 * 为什么在这里声明一个隐式变量呢,是因为在源码中,方法中有一个隐式参数;不设置是按照默认的排序规则进行排序; 8 */ 9 implicit val my_self_Ordering = new Ordering[String] { 10 override def compare(a: String, b: String): Int = { 11 val a_b: Array[String] = a.split("_") 12 val a_1 = a_b(0).toInt 13 val a_2 = a_b(1).toInt 14 val b_b = b.split("_") 15 val b_1 = b_b(0).toInt 16 val b_2 = b_b(1).toInt 17 if (a_1 == b_1) { 18 a_2 - b_2 19 } else { 20 a_1 - b_1 21 } 22 } 23 } 24 25 val rdd = resultRDD.map(x => (x._1 + "_" + x._2, x._2)).repartitionAndSortWithinPartitions(new KeyBasePartitioner(2)) 26 /** 27 * 自定义分区器 28 * 29 * @param partitions 30 */ 31 class KeyBasePartitioner(partitions: Int) extends Partitioner { 32 //分区数 33 override def numPartitions: Int = partitions 34 //该方法决定了你的数据被分到那个分区里面 35 override def getPartition(key: Any): Int = { 36 val k = key.asInstanceOf[String] 37 Math.abs(k.hashCode() % numPartitions) 38 } 39 }
coalesce vs. repartition
repartition底层调用的就是coalesce,coalesce函数有一个参数shuffle,默认为false;repartition则是在调用coalesce的时候,指定shuffle=true;所以repartition是一定会发生shuffle的。这里其实牵涉到一个宽依赖和窄依赖;前者将会发生shuffle,因为宽依赖代表着子RDD将会依赖父RDD的多个分区(或者全部分区),比如join,groupByKey等,因为子RDD依赖于多个分区,所以无法保证所有的父RDD的分区都和子RDD是在同一个节点上(甚至大概率是会跨节点的),跨节点传输就产生了shuffle;窄依赖则是值子RDD只会依赖于父RDD的一个分区,比如map操作,filter操作,都是在分区内完成的。
map vs. mapPartition
首先来看一下map和mapPartition的算法的区别。下面的这个是map操作实现元素+1,而mapPartitions的函数,用于首先累加。
1 import org.apache.spark.{SparkConf, SparkContext} 2 3 object mapAndMapPartitions { 4 def main(args: Array[String]): Unit = { 5 val conf = new SparkConf().setAppName("mapAndMapPartitions").setMaster("local") 6 var sc = new SparkContext(conf) 7 8 var aa = sc.parallelize(1 to 7, 2) // RDD有两个分区 9 aa.foreach(println) // output: 1 2 3 & 4 5 6 7 , 分别为两个区的元素 10 11 println("1.map------------------------------------------") 12 val aa_res = aa.map( x => x + 1) 13 println("Partitions' number: " + aa_res.getNumPartitions) // 获取partitions数目, output: 2 14 println("map: " + aa_res.collect().mkString(" ")) 15 16 println("2.mapPartitions--------------------------------") 17 var cc_ref = aa.mapPartitions( x => { 18 var result = List[Int]() 19 var cur = 0 20 while(x.hasNext){ 21 cur += x.next() 22 } 23 result.::(cur).iterator 24 }) 25 println("mapPartitions: " + cc_ref.collect().mkString(" ")) 26 } 27 }
输出结果
1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 1.map------------------------------------------ 9 map: 2 3 4 5 6 7 8 10 2.mapPartitions-------------------------------- 11 mapPartitions: 6 22
可以看到map返回的数量和数据源元素数量一致的,mapPartition返回的数据量则是和分区数量是一致的;这验证了两者操作的级别是不一样的。在mapPartition里面做很多操作是所有的当前分区里面的元素共享的,但是对于map操作而言,因为map操作还是发生在每个分区,但是map操作半身并不区分分区,所以你也不知道当前元素到底是是在哪个分区,所以无法设置共享对象;比如每个元素都要连接数据库做比较/check,如果map需要你的为每一个元素创建一个数据库链接;但是mapPartitions你需要在partition级别创建一个连接即可。
关于join的三种形式
不需要shuffle,就是采用broadcast方式,除此之外,就是需要shuffle,这里有两种模式:
第一个是Shuffle Hash Join,这种方式是将数据在join之前,按照key进行重新分区,此时将会产生shuffle,然后同key的数据比如会在同一个节点,就可以在单节点进行join;因为是小表,所以这里构建了一张hash表,用于作为小表的数据索引(hash table的作用就是内存数据的索引表),大表在join的时候,通过这张hash表就可以快速的定位到小表数据,进行关联。但是有一个疑问:Shuffle Hash Join会广播吗?我理解不会,但是我看到很多文章都调了广播。
与之类似的是sort merge join同是需要shuffle,但是这种join不再需要构建hash表,注意,对于Hash join的key是全部加载到内存中,然后取其hash值,根据hash值来定位数据,再进行join;sort merge join则不再维护一张hash表了,而是作为主表的(builder)供遍历,streamer表的数据用来提供数据,因为都是排好序的(所以称之为sort),所以在streamer提供了某个key,在builder表中的K位置找到了,streamer下一个key就可以直接到builder表中下一个位置来进行查找。主要是节省了一张hash表。
broadcast方式代码实现
下面的是sparkSql的方式
1 //读取ip表 2 val df = ... 3 4 //如果数据小于设定的广播大小则将该表广播,默认10M 5 df.cache.count 6 7 //注册表 8 df.registerTempTable("ipTable") 9 10 //关联 11 sqlContext.sql("select * from (select * from ipTable)a join (select * from hist)b on a.ip = b.ip") 12 13 ......
下面的是编程方式实现broadcast
1 // Broadcast+map的join操作,不会导致shuffle操作。 2 // 使用Broadcast将一个数据量较小的RDD作为广播变量 3 val rdd2Data = rdd2.collect() 4 val rdd2Bc = sc.broadcast(rdd2Data) 5 6 // 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。 7 // 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的,那么就判定可以进行join。 8 def function(tuple: (String,Int)): (String,(Int,String)) ={ 9 for(value <- rdd2Bc.value){ 10 if(value._1.equals(tuple._1)) 11 return (tuple._1,(tuple._2,value._2.toString)) 12 } 13 (tuple._1,(tuple._2,null)) 14 } 15 16 // 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。 17 // 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的,那么就判定可以进行join。 18 // 此时就可以根据自己需要的方式,将rdd1当前数据与rdd2中可以连接的数据,拼接在一起(String或Tuple)。 19 val rdd3 = rdd1.map(function(_)) 20 21 //结果如下,达到了与传统join相同的效果 22 scala> rdd1.map(function(_)).collect 23 res31: Array[(String, (Int, String))] = Array((jame,(23,cave)), (wade,(3,bulls)), (kobe,(24,lakers)))
reduceByKey vs groupByKey
下面是经典的wordcount实现:
1 val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local") 2 val sc = new SparkContext(conf) 3 val words = Array("one", "two", "two", "three", "three", "three") 4 val wordsRDD = sc.parallelize(words).map(word => (word, 1)) 5 val wordsCountWithReduce = wordsRDD. 6 reduceByKey(_ + _). 7 collect(). 8 foreach(println) 9 val wordsCountWithGroup = wordsRDD. 10 groupByKey(). 11 map(w => (w._1, w._2.sum)). 12 collect(). 13 foreach(println)
在代码层面上,你会看到groupByKey的实现wordcount是依赖于三个算子,分别是map(),groupByKey()以及map(),从DAG构建的RDD,首先是通过map各个数据节点本地构建<key value>数据集,然后基于本地构建的数据集执行groupbyKey操作,该算子是无法指定函数,只是纯粹在各个节点进行分组(将同key数据打包),通过shuffle将数据同步到reduce节点后,map函数实现同key(同单词)累加。
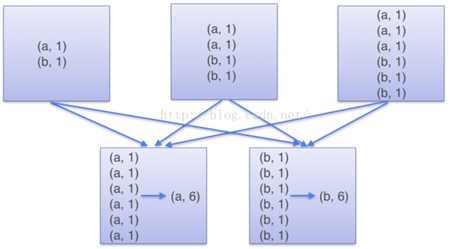
但是reduceByKey只是依赖两个算子,分别是构建本地数据集的map算子,以及reduceBykey算子,这个reduceByKey算子是可以指定"处理函数"的,从reduceByKey的算子实现逻辑是首先是在对数据进行本地的处理(在本地使用"处理函数"),然后再将数据基于key进行shuffle到reduce节点,进行二次(全局)"处理函数"的操作。
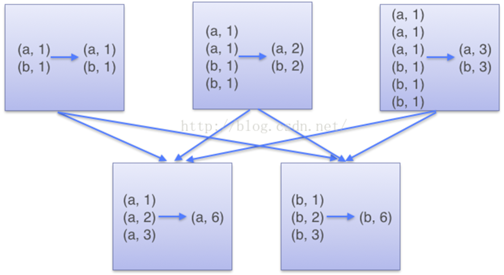
当然最后无论是reduceByKey还是groupByKey都是要从reduce节点将数据汇总到Driver节点的。
spark和yarn的交互图
贴一张spark和yarn交互的图:

图中spark部分是Driver,Executor,Cache以及Task,yarn部分组件是Resource Manager(Cluster Manager),WorkNode。spark context将会被打包发送到RM中,RM将会分配container0来运行这个context,即AM,AM将会向RM申请资源,RM下发资源列表给了AM,AM将会向各个work node去申请资源,即拉起container来运行executor。资源申请完毕后,Driver将会根据DAG来向各个Executor下发Task来操作数据。
spark内存模型
附上一张内存图,之前一直没明白到底有什么用,学到系统资源配置这份上了,才算知道用途。
spark.default.parallelism的官方说明
For distributed shuffle operations like reduceByKey and join, the largest number of partitions in a parent RDD. For operations like parallelize with no parent RDDs, it depends on the cluster manager:
Local mode: number of cores on the local machine
Mesos fine grained mode: 8
Others: total number of cores on all executor nodes or 2, whichever is larger
Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user.
参考
对于reduceByKey以及groupByKey的解释。
https://www.cnblogs.com/LuisYao/p/6813228.html
https://blog.csdn.net/zongzhiyuan/article/details/49965021
关于总体优化
https://www.cnblogs.com/jcchoiling/p/6440709.html
https://www.cnblogs.com/liangjf/p/8322410.html
https://blog.csdn.net/u013514928/article/details/52789169 分区和shuffle