数据结构篇:
逻辑结构与物理结构的区别:
逻辑结构 :是指数据对象中数据元素之间的相互关系
逻辑结构分类:
集合——各个元素之间是“平等”的,类似于数学里面的集合
线性结构——数据结构中的数据元素是一对一关系的
树性结构——数据结构中的数据元素之间存在一对多的层次关系
图形结构——数据结构中的数据元素之间存在多对多的关系
物理结构 :是指数据的逻辑结构在计算机中的存储形式
物理结构的分类:
- 顺序存储结构——把数据元素存放在地址连续的存储单元中,其数据间的逻辑关系和物理关系是一致的。
- 链式存储结构—把数据元素存放在任意的存储单元中,这组存储单元可以是连续的,也可以是不连续的。通过指针来找到下一个数据元素的地址。
- 3.索引存储结构——B+ 树
算法的五大特征
- 有穷性——有限的步骤
- 确定性——不可二义性
- 可行性——每一步都是通过执行有限次数完成的
- 输入——零个或多个输入
- 输出——至少有一个或多个输出
链表存储结构和顺序存储结构的区别:
从逻辑结构来看:
a) 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费;数组可以根据下标直接存取。
b) 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项,非常繁琐)链表必须根据next指针找到下一个元素
从内存存储来看:
a) (静态)数组从栈中分配空间, 对于程序员方便快速,但是自由度小
b) 链表从堆中分配空间, 自由度大但是申请管理比较麻烦
从上面的比较可以看出,如果需要快速访问数据,很少或不插入和删除元素,就应该用数组;相反, 如果需要经常插入和删除元素就需要用链表数据结构了。
栈和队列的区别:
栈和队列都是线性表,都是限制了插入删除点的线性表(或者说是控制了访问点的线性表)
共同点:都是只能在线性表的端点插入和删除
不同点:栈的插入和删除都在线性表的同一个端点,该点通称栈顶,相应地,不能插入删除的另一个端点通称栈底,其特性是先进后出,队列在线性表的表头插入,表尾删除,表头一般称队头,表尾一般称队尾,其特性是先进先出
相同之处:n个(同类)数据元素的有限序列称为线性表。线性表的特点是数据元素之间存在“一对一”的关系,栈和队列都是操作受限制的线性表,他们和线性表一样,数据元素之间都存在“一对一”的关系不同之处:栈只允许在一段进行插入或删除操作的线性表,其最大的特点是“先进后出 ”;对列是只允许在一端进行插入,另一端进行删除操作的线性表,其最大的特点是“先进先出”。
二叉树的特点:
1、每个结点最多有两颗子树,结点的度最大为2。
2、左子树和右子树是有顺序的,次序不能颠倒。
3、即使某结点只有一个子树,也要区分左右子树。
4、二叉树可以是空树、只有一个根结点、根结点只有左子树、根结点只有右子树、根结点左右子树都有。
度为2 的树:树的结点的最大的度为2.
图小结:
图结构中结点之间的关系是任意的,图中的任意两个结点都可能有关系。
图分为有向图和无向图
有向图的基本算法:拓扑排序、最短路径(Dijkstra算法和Floyd算法)。
无向图的基本算法:最小生成树(prime算法,Kruska算法)、DFS、BFS
深度优先遍历与广度优先遍历
深度优先遍历 类似于二叉树的先序遍历,步骤:
(1)访问起始点v
(2)若v的第一个邻接点没有被访问过,则深度遍历该邻接点;
(3)若v的第一个邻接点已经被访问,则访问其第二个邻接点,进行深度遍历;重复以上步骤直到所有节点都被访问过为止
广度优先算法 类似于层次遍历,步骤:
(1)访问起始点v
(2)依次遍历v的所有未访问过得邻接点
(3)再依次访问下一层中未被访问过得邻接点;重复以上步骤,直到所有的顶点都被访问过为止
深度优先遍历,时间复杂度是O(n²)或O(n+e),使用递归
广度优先遍历,时间复杂度是O(n+e)或O(n²,其中e为图中边的个数,使用队列。
最小生成树的算法(普利姆算法,克鲁斯卡尔算法)
普利姆算法(Prim),算法执行过程:
将v0到其他顶点的所有边当做候选边
重复以下过程,直到所有的顶点被并入树中
1.从候选边中挑选出最小的边输出,并将于该边的另一端顶点并入树中
2.考查所有剩余的顶点,选取与这棵树相接的边最短的边
时间复杂度为O(n2),适用于稠密图
克鲁斯卡尔算法,思路:
每次找出后候选边中权值最小的边,并入生成树中,算法执行过程
将图中边按照权值从小到大排序,
然后从最小边开始扫描,
并检测当前边是否为候选边,即是否该边并入会构成回路
最短路径
迪杰斯特拉算法,用于计算图中某一结点到其余顶点的最短路径,思路:集合s存放图中一找到最短路径的顶点集合,U存放途中剩余顶点,算法步骤:
a.初始时,S只包含源点,即S={v},v的距离为0。U包含除v外的其他顶点,即:U={其余顶点},若v与U中顶点u有边,则<u,v>正常有权值,若u不是v的邻接点,则<u,v>权值为∞。
b.从U中选取一个距点集v最近的顶点k(min),把k加入S中(该选定的距离就是v到k的最短路径长度)。
c.以k为新考虑的中间点,修改V中点到U中各顶点的距离;若从源点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值的顶点k的距离加上边上的权。
d.重复步骤b和c直到所有顶点都包含在S中。
拓扑排序的概念以及实现(AOV网)
一种以顶点表示活动,以边表示活动的先后次序且没有回路的有向图,反映出整个工程中各个活动之间的先后关系的有向图。
拓扑算法的核心过程:
1.从有向图中选择一个没有前驱(入度为0)的顶点输出。
2.删除1中的顶点,并且删除从该顶点发出的全部边
3.一直重复。若图中没有环的时候,还可采用深度优先搜索遍历的方法进行拓扑排序
关键路径的相关概念
AOE网——对于活动在边上的我网
AOV和AOE的区别
相同点: 都是无环图
不同点:AOV活动在顶点,边无权值,代表活动之前的先后关系,
AOE活动在边,边有权值,代表活动持续的时间
关键路径的核心算法:最大路径长度的路径称为关键路径
关键活动:关键路径上的活动为关键路径,关键活动的最早开始时间等于最晚开始时间。由于AOE网中的某些活动是可以同时发生的,所以完成整个工程的时间应该是从始点到终点的最大路径长度,关键路径长度即为工程的最短完成时间。
各种查找方法
静态查找表:顺序查找、折半查找、分块查找
动态查找表:二叉排序树、平衡二叉树
顺序查找:结构简单,顺序结构和链式结构都可以,查找效率低
折半查找:要求查找表为顺序存储结构并且有序
分块查找:先把查找表分为若干子表,要求每个子表的元素都要比他后面的子表的元素小,从而保存块间是有序的,把各子表中的最大关键词构成一张索引表,表中还包含各子表的起始地址。
特点:块间有序,块内无序,查找时块间进行索引查找,块内进行顺序查找。
平衡二叉树:左右子树高度差不能大于1,且左右子树也都是平衡二叉树
快速排序:
快速排序(Quick Sort)使用分治法策略。它的基本思想是:在数据序列中选择一个元素作为基准值,每躺从数据序列的两端开始交替进行,将小于基准值元素交换到序列前端,将大于基准值的元素交换到序列后端,介于两者之间的位置则成为基准值的最终位置。同时,序列被划分成两个子序列,再分别对两个子序列进行快速排序,直到子序列长度为1,则完成排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
快速排序的优化
1.当整个序列有序时退出算法;
2.当序列长度很小时(根据经验是大概小于 8),应该使用常数更小的算法,比如插入排序等;
3.随机选取分割位置;
4.当分割位置不理想时,考虑是否重新选取分割位置;
5.分割成两个序列时,只对其中一个递归进去,另一个序列仍可以在这一函数内继续划分,可以显著减小栈的大小(尾递归):
6.将单向扫描改成双向扫描,可以减少划分过程中的交换次数
优化1:当待排序序列的长度分割到一定大小后,使用插入排序
原因:对于很小和部分有序的数组,快排不如插排好。当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差,此时可以使用插排而不是快排
优化2:在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割
优化3:优化递归操作,快排函数在函数尾部有两次递归操作,我们可以对其使用尾递归优化
优点:如果待排序的序列划分极端不平衡,递归的深度将趋近于n,而栈的大小是很有限的,每次递归调用都会耗费一定的栈空间,函数的参数越多,每次递归耗费的空间也越多。优化后,可以缩减堆栈深度,由原来的O(n)缩减为O(logn),将会提高性能。
各种排序:
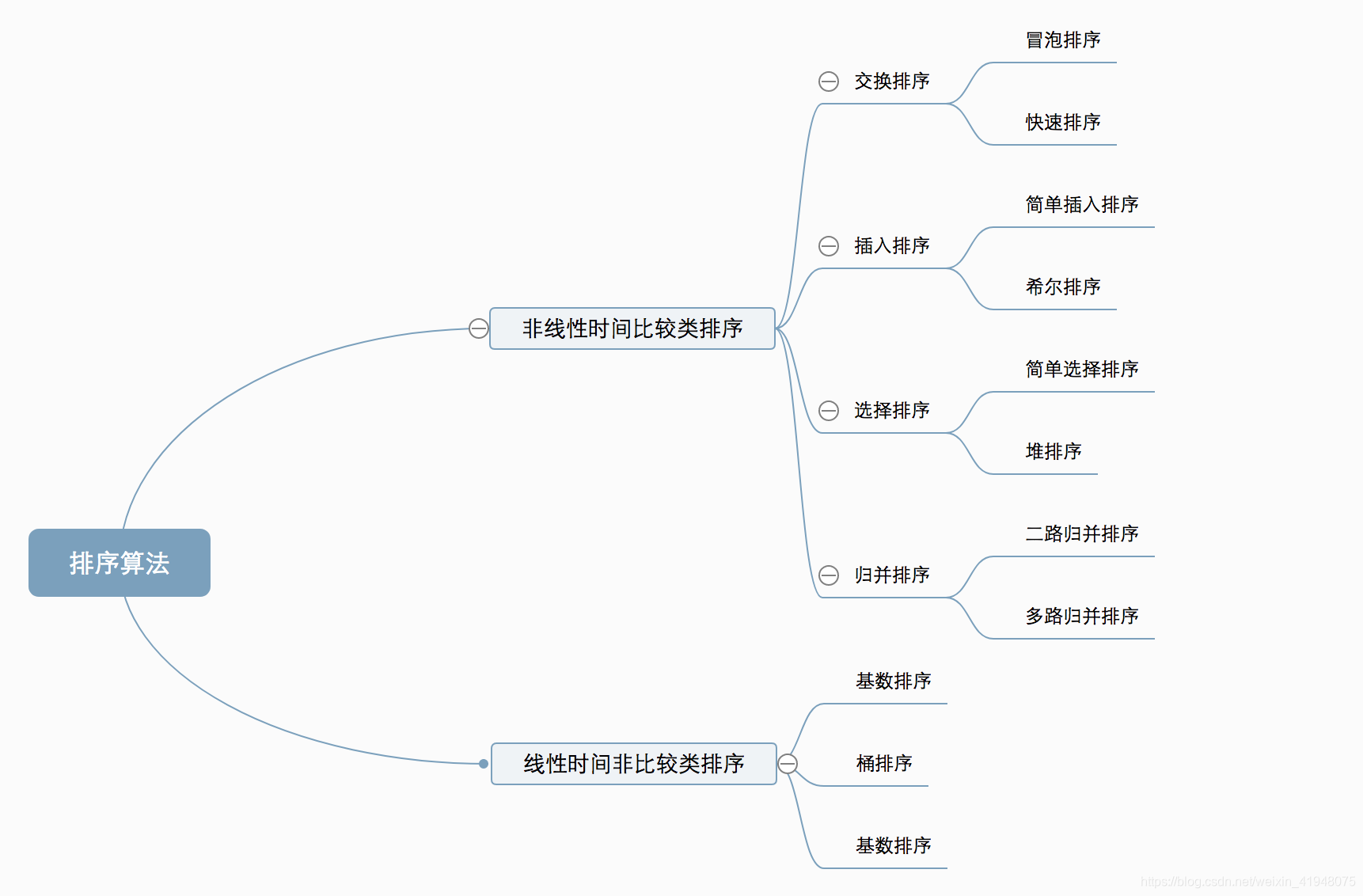
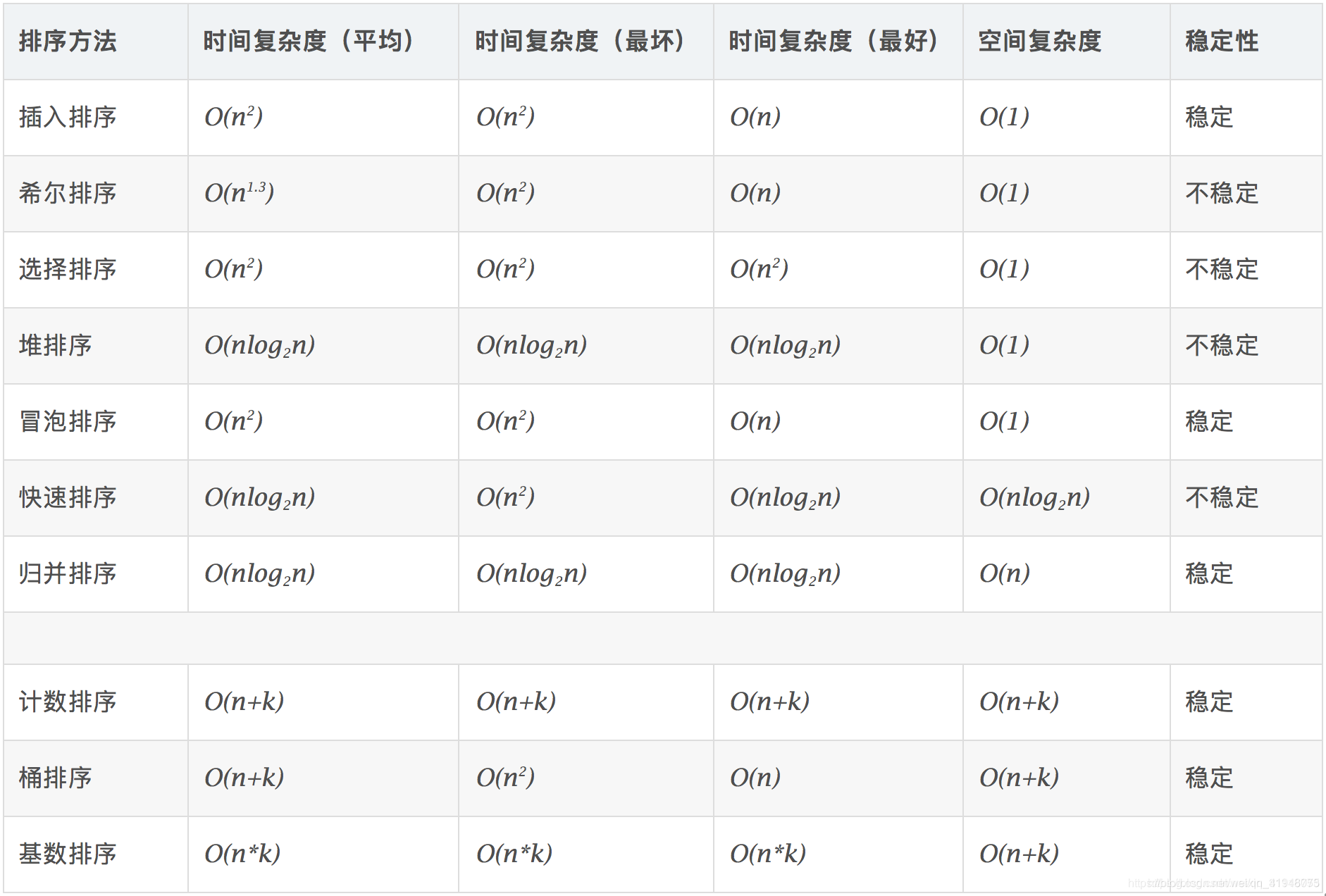
堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
最小/大堆用于求最小/大值,堆序列用于多次求极值的应用问题。
算法描述:将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
堆排序算法分析:最佳情况:T(n) = O(nlog2n) 最差情况:T(n) = O(nlog2n) 平均情况:T(n) = O(nlog2n)
直接选择排序算法有两个缺点:选择最小值效率低,必须遍历子序列,比较了所有元素后才能选出最小值,每躺将最小值交换到前面,其余元素原地不动,下一趟没有利用前一躺的比较结果,需要再次比较这些元素,重复比较很多。
堆排序改进了直接选择排序,采用最小/最大堆选择最小/最大值
归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
算法描述:
把长度为n的输入序列分成两个长度为n/2的子序列;
对这两个子序列分别采用归并排序;
将两个排序好的子序列合并成一个最终的排序序列。
B树和B+树的区别,以一个m阶树为例。
关键字的数量不同:B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
存储的位置不同:B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
分支结点的构造不同:B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
查询不同:B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
数据的存储结构
-
顺序存储。把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存 储单元的邻接关系来体现。其优点是可以实现随机存取,每个元素占用最少的存储空间;缺点是 只能使用相邻的一整块存储单元,因此可能产生较多的外部碎片。
-
链式存储。不要求逻辑上相邻的元素在物理位置上也相邻,借助指示元素存储地址的指针来表 示元素之间的逻辑关系。其优点是不会出现碎片现象,能充分利用所有存储单元;缺点是每个元 素因存储指针而占用额外的存储空间,且只能实现顺序存取。
-
索引存储。在存储元素信息的同时,还建立附加的索引表。索引表中的每项称为索引项,索引 项的一般形式是(关键字,地址)。其优点是检索速度快;缺点是附加的索引表额外占用存储空 间。另外,增加和删除数据时也要修改索引表,因而会花费较多的时间。
-
散列存储。根据元素的关键字直接计算出该元素的存储地址,又称哈希(Hash) 存储。其优点是 检索、增加和删除结点的操作都很快;缺点是若散列函数不好,则可能出现元素存储单元的冲 突,而解决冲突会增加时间和空间开销。
队列在计算机系统中的应用?
队列在计算机系统中的应用非常广泛,以下仅从两个方面来简述队列在计算机系统中的作用:第 一个方面是解决主机与外部设备之间速度不匹配的问题,第二个方面是解决由多用户引起 的资源竞争问题。
对于第一个方面,仅以主机和打印机之间速度不匹配的问题为例做简要说明。主机输出数据给打 印机打印,输出数据的速度比打印数据的速度要快得多,由于速度不匹配,若直接把输出的 数据送给打印机打印显然是不行的。解决的方法是设置一个打印数据缓冲区,主机把要打印输出 的数据依次写入这个缓冲区,写满后就暂停输出,转去做其他的事情。打印机就从缓冲区中按照 先进先出的原则依次取出数据并打印,打印完后再向主机发出请求。主机接到请求后再向缓冲区 写入打印数据。这样做既保证了打印数据的正确,又使主机提高了效率。由此可见,打印数据缓 冲区中所存储的数据就是一个队列。
对于第二个方面, CPU (即中央处理器,它包括运算器和控制器)资源的竞争就是一个典型 的例子。在一个带有多终端的计算机系统上,有多个用户需要CPU 各自运行自己的程序,它们分别通过各自的终端向操作系统提出占用CPU 的请求。操作系统通常按照每个请求在时间上的先后 顺序,把它们排成一个队列,每次把CPU 分配给队首请求的用户使用。当相应的程序运行结束或 用完规定的时间间隔后,令其出队,再把CPU 分配给新的队首请求的用户使用。这样既能满足每 个用户的请求,又使CPU 能够正常运行。
头节点的作用:
在链表中设置头结点:作用是为了链表操作时,可以对空表、非空表以及对首元素结点进行统一处理。
深度优先和广度优先的对比*
深度优先搜索(回溯法)
算法思路
深度优先搜索(DFS,Depth-First Search)是搜索的手段之一
它从某个状态开始,不断地转移状态直到无法转移,然后回退到前一步状态,继续转移到其他状态,如此不断重复,直到找到最终的解.根据深度优先搜索的特点,采用递归函数(隐式地利用了栈进行计算)实现比较简单.
算法效率
深度优先搜索从最开始的状态出发,遍历所有可以到达的状态.由此可以对所有的状态进行操作,或列举出所有的状态.作为搜索算法的一种,DFS对于寻找一个解的NP(包括NPC)问题作用很大.
但是,搜索算法毕竟是时间复杂度是O(n!)的阶乘级算法,它的效率比较低,在数据规模变大时,这种算法就显得力不从心了.关于深度优先搜索的效率问题,有多种解决方法.最具有通用性的是剪枝(prunning),也就是去除没有用的搜索分支.有可行性剪枝和最优性剪枝两种.此外,对于很多问题,可以把搜索与动态规划(DP,dynamic programming)、完备匹配(匈牙利算法)等高效算法结合.
2.宽度优先搜索(分支限界法)
算法思路
宽度优先搜索(BFS,Breadth-First Search)也是搜索的手段之一.他与深度优先搜索类似,从某个状态出发搜索所有可以到达的状态.根据宽度优先搜索的特点,采用队列实现比较简单.
算法效率
与深度优先不同之处在与搜索的顺序,宽度优先搜索总是先搜索距离初始状态近的状态.也就是说,它是按照开始状态->只需1次转移就可以到达的所有状态->只需2次转移就可以到达的所有状态->…这样的顺序进行搜索.对于同一个状态,宽度优先搜索只经过一次,因此复杂度为
O(状态数*转移的方式).很容易地用来求最短路径、最少操作之类问题的答案.
广度搜索的判断重复如果直接判断十分耗时,我们一般借助哈希表来优化时间复杂度.
3.Death-Breadth总结
宽度优先搜索与深度优先搜索一样,都会生成所有能够遍历到的状态,因此需要对所有状态进行处理时使用宽度优先也是可以的.但是递归函数可以很简短地编写,而且状态的管理也更简单,所以大多数情况下还是用深度优先搜索实现.反之,在求取最短路时深度优先搜索需要反复经过同样的状态,所以还是使用宽度优先搜索比较好.
宽度优先搜索会把状态逐个加入队列,因此通常需要与状态数成正比的内存空间.反之,深度优先搜索是与最大的递归深度成正比的.一般与状态数相比,递归的深度并不会太大,所以可以认为深度优先搜索更加节省内存.
部分参考:https://blog.csdn.net/weixin_44177594/article/details/105932432?spm=1001.2014.3001.5502