先说一下在读取配置文件时报错的问题--ConfigParser.MissingSectionHeaderError: File contains no section headers
问题描述:
在练习ConfigParser读取配置文件时,cmd一直报一个错:ConfigParser.MissingSectionHeaderError: File contains no section headers.如图:
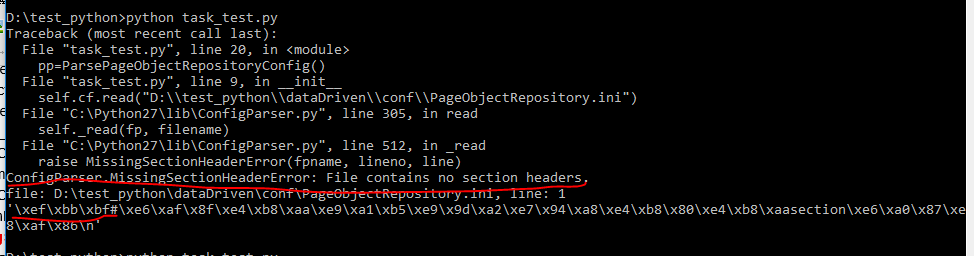
D: est_python>python task_test.py
Traceback (most recent call last):
File "task_test.py", line 20, in <module>
pp=ParsePageObjectRepositoryConfig()
File "task_test.py", line 9, in __init__
self.cf.read("D:\test_python\dataDriven\conf\PageObjectRepository.ini")
File "C:Python27libConfigParser.py", line 305, in read
self._read(fp, filename)
File "C:Python27libConfigParser.py", line 512, in _read
raise MissingSectionHeaderError(fpname, lineno, line)
ConfigParser.MissingSectionHeaderError: File contains no section headers.
file: D: est_pythondataDrivenconfPageObjectRepository.ini, line: 1
'xefxbbxbf#xe6xafx8fxe4xb8xaaxe9xa1xb5xe9x9dxa2xe7x94xa8xe4xb8x80xe4xb8xaasectionxe6xa0x87xe8xafx86
'
百度了一下网上的解决方案,
报错是因为配置文件PageObjectRepository.ini在windows下经过notepad编辑后保存为UTF-8或者unicode格式的话,会在文件的开头加上两个字节“xffxfe”或者三个字节“xefxbbxbf”。 就是--》BOM, BOM是什么?请看结尾
解决的办法就是在配置文件被读取前,把DOM字节个去掉。
网上也给了一个用正则去掉BOM字节的函数:就是把对应的字节替换成空字符串
remove_BOM()函数定义:
def remove_BOM(config_path):
content = open(config_path).read()
content = re.sub(r"xfexff","", content)
content = re.sub(r"xffxfe","", content)
content = re.sub(r"xefxbbxbf","", content)
open(config_path, 'w').write(content)
下面贴一下我的配置文件和读取配置文件的代码--:

代码:
#encoding=utf-8
from ConfigParser import ConfigParser
import re
def remove_BOM(config_path):#去掉配置文件开头的BOM字节
content = open(config_path).read()
content = re.sub(r"xfexff","", content)
content = re.sub(r"xffxfe","", content)
content = re.sub(r"xefxbbxbf","", content)
open(config_path, 'w').write(content)
class ParsePageObjectRepositoryConfig(object):
def __init__(self,config_path):
self.cf=ConfigParser()#生成解析器
self.cf.read(config_path)
print "-"*80
print "cf.read(config_path):
", self.cf.read(config_path)
def getItemsFromSection(self,sectionName):
print self.cf.items(sectionName)
return dict(self.cf.items(sectionName))
def getOptionValue(self,sectionName,optionName):#返回一个字典
return self.cf.get(sectionName,optionName)
if __name__=='__main__':
remove_BOM("D:\test_python\PageObjectRepository.ini")
pp=ParsePageObjectRepositoryConfig("D:\test_python\PageObjectRepository.ini")
remove_BOM
print "-"*80
print "items of '126mail_login':
",pp.getItemsFromSection("126mail_login")
print "-"*80
print "value of 'login_page.username' under section '126mail_login':
",pp.getOptionValue("126mail_login","login_page.username")
结果:
D: est_python>python task_test.py
--------------------------------------------------------------------------------
cf.read(config_path):
['D:\test_python\PageObjectRepository.ini']
--------------------------------------------------------------------------------
items of '126mail_login':
[('login_page.frame', 'id>x-URS-iframe'), ('login_page.username', "xpath>//input[@name='email']"), ('login_page.password', "xpath>//input[@name='password']"), ('login_page.loginbutton', 'id>dologin')]
{'login_page.loginbutton': 'id>dologin', 'login_page.username': "xpath>//input[@name='email']", 'login_page.frame': 'id>x-URS-iframe', 'login_page.password': "xpath>//input[@name='password']"}
--------------------------------------------------------------------------------
value of 'login_page.username' under section '126mail_login':
xpath>//input[@name='email']
BOM概念:
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
UTF-8 不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 “Zero Width No-Break Space” 的
UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8编码了。Windows
就是使用 BOM
来标记文本文件的编码方式的。类似WINDOWS自带的记事本等软件,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF
0xBB 0xBF,即BOM)。它是一串隐藏的字符,用于让记事本等编辑器识别这个文件是否以UTF-8编码。
从堆栈信息中可以看到UTF8编码的字符有BOM的字符串前边有:xefxbbxbf
'xefxbbxbf#xe6xafx8fxe4xb8xaaxe9xa1xb5xe9x9dxa2xe7x94xa8xe4xb8x80xe4xb8xaasectionxe6xa0x87xe8xafx86 '