转载自:https://mp.weixin.qq.com/s/umH7ImZZVhdfgMdZ3Hz5fA
ELK介绍
ELK最早是Elasticsearch(以下简称ES)、Logstash、Kibana三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark、Beats等组件,改名为Elastic Stack,成为现在最流行的开源日志解决方案,虽然有了新名字但大家依然喜欢叫她ELK,现在所说的ELK就指的是基于这些开源软件构建的日志系统。
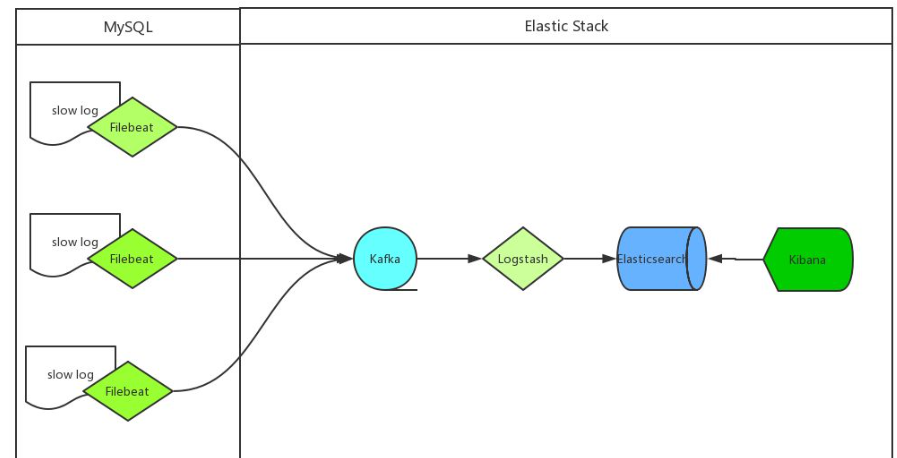
我们收集mysql慢日志的方案如下:
-
mysql服务器安装Filebeat作为agent收集slowLog
-
Filebeat读取mysql慢日志文件做简单过滤传给Kafka集群
-
Logstash读取Kafka集群数据并按字段拆分后转成JSON格式存入ES集群
-
Kibana读取ES集群数据展示到web页面上
慢日志分类
目前主要使用的mysql版本有5.5、5.6和5.7,经过仔细对比发现每个版本的慢查询日志都稍有不同,如下:
5.5版本慢查询日志
# Time: 180810 8:45:12
# User@Host: select[select] @ [10.63.253.59]
# Query_time: 1.064555 Lock_time: 0.000054 Rows_sent: 1 Rows_examined: 319707
SET timestamp=1533861912;
SELECT COUNT(*) FROM hs_forum_thread t WHERE t.`fid`='50' AND t.`displayorder`>='0';
5.6版本慢查询日志
# Time: 160928 18:36:08
# User@Host: root[root] @ localhost [] Id: 4922
# Query_time: 5.207662 Lock_time: 0.000085 Rows_sent: 1 Rows_examined: 526068
use db_name;
SET timestamp=1475058968;
select count(*) from redeem_item_consume where id<=526083;
5.7版本慢查询日志
# Time: 2018-07-09T10:04:14.666231Z
# User@Host: bbs_code[bbs_code] @ [10.82.9.220] Id: 9304381
# Query_time: 5.274805 Lock_time: 0.000052 Rows_sent: 0 Rows_examined: 2
SET timestamp=1531130654;
SELECT * FROM pre_common_session WHERE sid='Ba1cSC' OR lastactivity<1531129749;
慢查询日志异同点:
-
每个版本的Time字段格式都不一样
-
相较于5.6、5.7版本,5.5版本少了Id字段
-
use db语句不是每条慢日志都有的 -
可能会出现像下边这样的情况,慢查询块
# Time:下可能跟了多个慢查询语句
# Time: 160918 2:00:03
# User@Host: dba_monitor[dba_monitor] @ [10.63.144.82] Id: 968
# Query_time: 0.007479 Lock_time: 0.000181 Rows_sent: 172 Rows_examined: 344
SET timestamp=1474135203;
SELECT table_schema as 'DB',table_name as 'TABLE',CONCAT(ROUND(( data_length + index_length ) / ( 1024 * 1024 *1024 ), 2), '') as 'TOTAL',TABLE_COMMENT FROM information_schema.TABLES ORDER BY data_length + index_length DESC;
# User@Host: dba_monitor[dba_monitor] @ [10.63.144.82] Id: 969
# Query_time: 0.003303 Lock_time: 0.000395 Rows_sent: 233 Rows_examined: 233
SET timestamp=1474135203;
select TABLE_SCHEMA,TABLE_NAME,COLUMN_NAME,ORDINAL_POSITION,COLUMN_TYPE,ifnull(COLUMN_COMMENT,0) from COLUMNS where table_schema not in ('mysql','information_schema','performance_schema','test');
处理思路
上边我们已经分析了各个版本慢查询语句的构成,接下来我们就要开始收集这些数据了,究竟应该怎么收集呢?
-
拼装日志行:mysql的慢查询日志多行构成了一条完整的日志,日志收集时要把这些行拼装成一条日志传输与存储。
-
Time行处理:
# Time:开头的行可能不存在,且我们可以通过SET timestamp这个值来确定SQL执行时间,所以选择过滤丢弃Time行 -
一条完整的日志:最终将以
# User@Host:开始的行,和以SQL语句结尾的行合并为一条完整的慢日志语句 -
确定SQL对应的DB:
use db这一行不是所有慢日志SQL都存在的,所以不能通过这个来确定SQL对应的DB,慢日志中也没有字段记录DB,所以这里建议为DB创建账号时添加db name标识,例如我们的账号命名方式为:projectName_dbName,这样看到账号名就知道是哪个DB了 -
确定SQL对应的主机:我想通过日志知道这条SQL对应的是哪台数据库服务器怎么办?慢日志中同样没有字段记录主机,可以通过filebeat注入字段来解决,例如我们给filebeat的name字段设置为服务器IP,这样最终通过
beat.name这个字段就可以确定SQL对应的主机了
Filebeat配置
filebeat完整的配置文件如下:
filebeat.prospectors:
- input_type: log
paths:
- /home/opt/data/slow/mysql_slow.log
exclude_lines: ['^# Time']
multiline.pattern: '^# Time|^# User'
multiline.negate: true
multiline.match: after
tail_files: true
name: 10.82.9.89
output.kafka:
hosts: ["10.82.9.202:9092","10.82.9.203:9092","10.82.9.204:9092"]
topic: mysql_slowlog_v2
重要参数解释:
-
input_type:指定输入的类型是log或者是stdin
-
paths:慢日志路径,支持正则比如/data/*.log
-
exclude_lines:过滤掉
# Time开头的行 -
multiline.pattern:匹配多行时指定正则表达式,这里匹配以
# Time或者# User开头的行,Time行要先匹配再过滤 -
multiline.negate:定义上边pattern匹配到的行是否用于多行合并,也就是定义是不是作为日志的一部分
-
multiline.match:定义如何将皮排行组合成时间,在之前或者之后
-
tail_files:定义是从文件开头读取日志还是结尾,这里定义为true,从现在开始收集,之前已存在的不管
-
name:设置filebeat的名字,如果为空则为服务器的主机名,这里我们定义为服务器IP
-
output.kafka:配置要接收日志的kafka集群地址可topic名称
Kafka接收到的日志格式:
{"@timestamp":"2018-08-07T09:36:00.140Z","beat":{"hostname":"db-7eb166d3","name":"10.63.144.71","version":"5.4.0"},"input_type":"log","message":"# User@Host: select[select] @ [10.63.144.16] Id: 23460596
# Query_time: 0.155956 Lock_time: 0.000079 Rows_sent: 112 Rows_examined: 366458
SET timestamp=1533634557;
SELECT DISTINCT(uid) FROM common_member WHERE hideforum=-1 AND uid != 0;","offset":1753219021,"source":"/data/slow/mysql_slow.log","type":"log"}
Logstash配置
logstash完整的配置文件如下:
input {
kafka {
bootstrap_servers => "10.82.9.202:9092,10.82.9.203:9092,10.82.9.204:9092"
topics => ["mysql_slowlog_v2"]
}
}
filter {
json {
source => "message"
}
grok {
# 有ID有use
match => [ "message", "(?m)^# User@Host: %{USER:user}[[^]]+] @ (?:(?<clienthost>S*) )?[(?:%{IP:clientip})?]s+Id:s%{NUMBER:id:int}
# Query_time: %{NUMBER:query_time:float}s+Lock_time: %{NUMBER:lock_time:float}s+Rows_sent: %{NUMBER:rows_sent:int}s+Rows_examined: %{NUMBER:rows_examined:int}
uses(?<dbname>w+);
SETs+timestamp=%{NUMBER:timestamp_mysql:int};
(?<query>.*)" ]
# 有ID无use
match => [ "message", "(?m)^# User@Host: %{USER:user}[[^]]+] @ (?:(?<clienthost>S*) )?[(?:%{IP:clientip})?]s+Id:s%{NUMBER:id:int}
# Query_time: %{NUMBER:query_time:float}s+Lock_time: %{NUMBER:lock_time:float}s+Rows_sent: %{NUMBER:rows_sent:int}s+Rows_examined: %{NUMBER:rows_examined:int}
SETs+timestamp=%{NUMBER:timestamp_mysql:int};
(?<query>.*)" ]
# 无ID有use
match => [ "message", "(?m)^# User@Host: %{USER:user}[[^]]+] @ (?:(?<clienthost>S*) )?[(?:%{IP:clientip})?]
# Query_time: %{NUMBER:query_time:float}s+Lock_time: %{NUMBER:lock_time:float}s+Rows_sent: %{NUMBER:rows_sent:int}s+Rows_examined: %{NUMBER:rows_examined:int}
uses(?<dbname>w+);
SETs+timestamp=%{NUMBER:timestamp_mysql:int};
(?<query>.*)" ]
# 无ID无use
match => [ "message", "(?m)^# User@Host: %{USER:user}[[^]]+] @ (?:(?<clienthost>S*) )?[(?:%{IP:clientip})?]
# Query_time: %{NUMBER:query_time:float}s+Lock_time: %{NUMBER:lock_time:float}s+Rows_sent: %{NUMBER:rows_sent:int}s+Rows_examined: %{NUMBER:rows_examined:int}
SETs+timestamp=%{NUMBER:timestamp_mysql:int};
(?<query>.*)" ]
}
date {
match => ["timestamp_mysql","UNIX"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["10.82.9.208:9200","10.82.9.217:9200"]
index => "mysql-slowlog-%{+YYYY.MM.dd}"
}
}
重要参数解释:
-
input:配置kafka的集群地址和topic名字
-
filter:过滤日志文件,主要是对message信息(看前文kafka接收到的日志格式)进行拆分,拆分成一个一个易读的字段,例如
User、Host、Query_time、Lock_time、timestamp等。grok段根据我们前文对mysql慢日志的分类分别写不通的正则表达式去匹配,当有多条正则表达式存在时,logstash会从上到下依次匹配,匹配到一条后边的则不再匹配。date字段定义了让SQL中的timestamp_mysql字段作为这条日志的时间字段,kibana上看到的实践排序的数据依赖的就是这个时间 -
output:配置ES服务器集群的地址和index,index自动按天分割
kibana查询展示
-
打开Kibana添加
mysql-slowlog-*的Index,并选择timestamp,创建Index Pattern 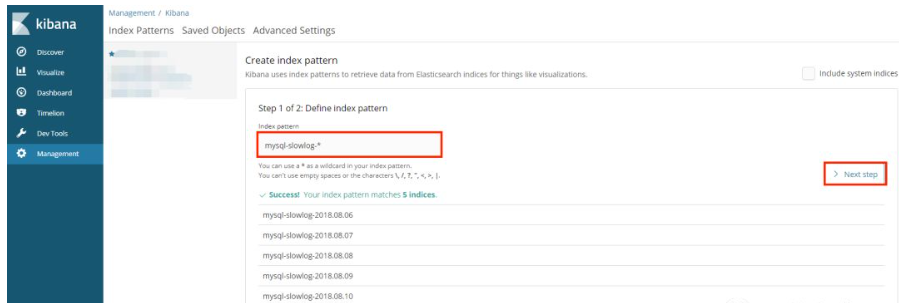
-
进入Discover页面,可以很直观的看到各个时间点慢日志的数量变化,可以根据左侧Field实现简单过滤,搜索框也方便搜索慢日志,例如我要找查询时间大于2s的慢日志,直接在搜索框输入
query_time: > 2回车即可 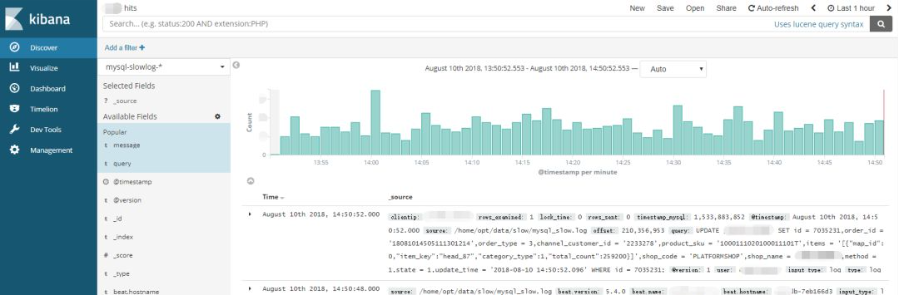
-
点击每一条日志起边的很色箭头能查看具体某一条日志的详情
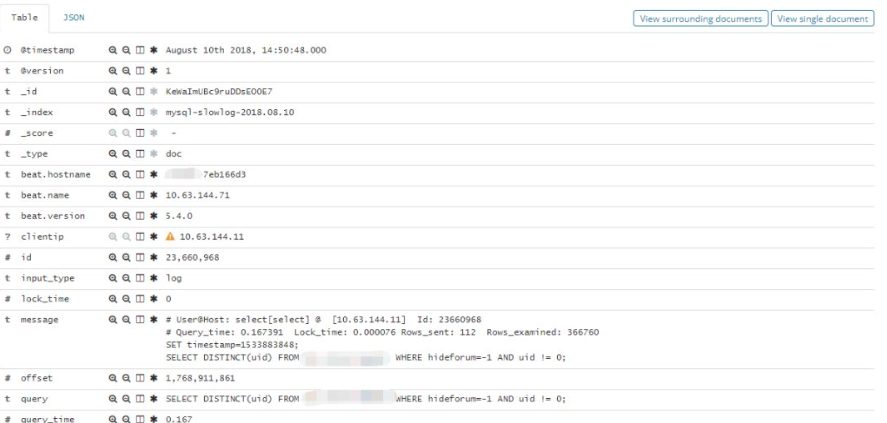
-
如果你想做个大盘统计慢日志的整体情况,例如top 10 SQL等,也可以很方便的通过web界面配置
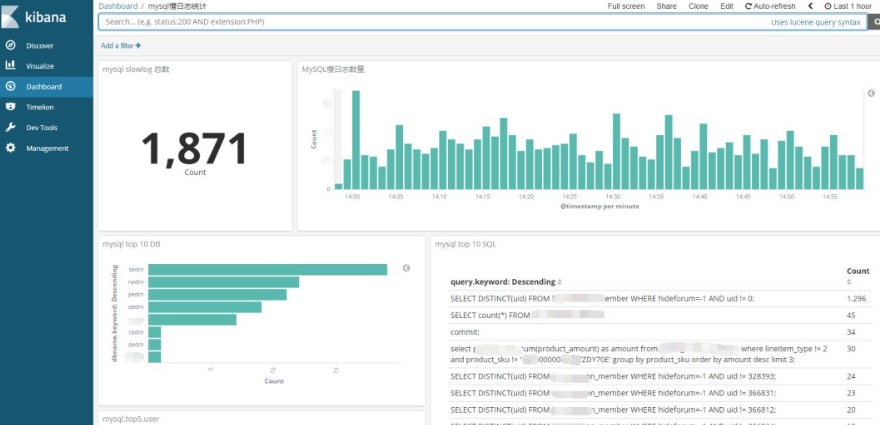
总结
-
不要望而却步,当你开始去做已经成功一半了
-
本篇文章详细介绍了关于mysql慢日志的收集,收集之后的处理呢?我们目前是DBA每天花时间去Kibana上查看分析,有优化的空间就跟开发一起沟通优化,后边达成默契之后考虑做成自动报警或处理
-
关于报警ELK生态的xpark已经提供,且最新版本也开源了,感兴趣的可以先研究起来,欢迎一起交流