官网说明:http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization
一、JVM调优
1.1、Java虚拟机垃圾回收调优的背景
- 如果在持久化RDD的时候,持久化了大量的数据,那么Java虚拟机的垃圾回收就可能成为一个性能瓶颈。因为Java虚拟机会定期进行垃圾回收,此时就会追踪所有的java对象,并且在垃圾回收时,找到那些已经不在使用的对象,然后清理旧的对象,来给新的对象腾出内存空间。
- 垃圾回收的性能开销,是跟内存中的对象的数量,成正比的。所以,对于垃圾回收的性能问题:
- 首先要做的就是,使用更高效的数据结构,比如array和string;
- 其次就是在持久化rdd时,使用序列化的持久化级别,而且用Kryo序列化类库,这样,每个partition就只是一个对象——一个字节数组。

1.2、监测垃圾回收
- 我们可以对垃圾回收进行监测,包括多久进行一次垃圾回收,以及每次垃圾回收耗费的时间。只要在spark-submit脚本中,增加一个配置即可,
- --conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"。
- 注意:这里虽然会打印出Java虚拟机的垃圾回收的相关信息,但是是输出到了worker上的日志中(集群),而不是driver的日志中。
- 也完全可以通过SparkUI(4040端口)来观察每个stage的垃圾回收的情况。
- spark.executor.extraJavaOptions是配置executor的jvm参数
- spark.driver.extraJavaOptions是配置driver的jvm参数
1.3、优化executor内存比例
- 对于垃圾回收来说,最重要的就是调节RDD缓存占用的内存空间,与算子执行时创建的对象占用的内存空间的比例。默认情况下,Spark使用每个executor 60%的内存空间来缓存RDD,那么在task执行期间创建的对象,只有40%的内存空间来存放。
- 在这种情况下,很有可能因为你的内存空间的不足,task创建的对象过大,那么一旦发现40%的内存空间不够用了,就会触发Java虚拟机的垃圾回收操作。因此在极端情况下,垃圾回收操作可能会被频繁触发。
- 在上述情况下,如果发现垃圾回收频繁发生。那么就需要对那个比例进行调优,使用new SparkConf().set("spark.storage.memoryFraction", "0.5")即可,可以将RDD缓存占用空间的比例降低,从而给更多的空间让task创建的对象进行使用。
- 因此,对于RDD持久化,完全可以使用Kryo序列化,加上降低其executor内存占比的方式,来减少其内存消耗。给task提供更多的内存,从而避免task的执行频繁触发垃圾回收。

1.4、高级垃圾回收调优
- Java堆空间被划分成了两块空间,一个是年轻代,一个是老年代。年轻代放的是短时间存活的对象,老年代放的是长时间存活的对象。年轻代又被划分了三块空间,Eden、Survivor1、Survivor2。
- 首先,Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。创建的对象,首先放入Eden区域和Survivor1区域,如果Eden区域满了,那么就会触发一次Minor GC,进行年轻代的垃圾回收。Eden和Survivor1区域中存活的对象,会被移动到Survivor2区域中。然后Survivor1和Survivor2的角色调换,Survivor1变成了备用。
- 如果一个对象,在年轻代中,撑过了多次垃圾回收,都没有被回收掉,那么会被认为是长时间存活的,此时就会被移入老年代。此外,如果在将Eden和Survivor1中的存活对象,尝试放入Survivor2中时,发现Survivor2放满了,那么会直接放入老年代。此时就出现了,短时间存活的对象,进入老年代的问题。
- 如果老年代的空间满了,那么就会触发Full GC,进行老年代的垃圾回收操作。
在Spark中进行GC调整的目的是确保在老年代中仅存储长寿命的RDD,而在年轻代中,其大小足以存储短寿命的对象。这将有助于避免完整的GC收集任务执行期间创建的临时对象
- 通过收集GC统计信息检查是否有太多垃圾回收。如果在任务完成之前多次调用Full GC,则意味着没有足够的内存来执行任务。
- Spark如果发现,在task执行期间,大量full gc发生了,那么说明,年轻代的Eden区域,给的空间不够大。此时可以执行一些操作来优化垃圾回收行为:
- 包括降低spark.storage.memoryFraction的比例,给年轻代更多的空间,来存放短时间存活的对象;
- 给Eden区域分配更大的空间,使用-Xmn即可,通常建议给Eden区域,预计大小的4/3;
- 如果使用的是HDFS文件,那么很好估计Eden区域大小,如果每个executor有4个task,然后每个hdfs压缩块解压缩后是该压缩块大小的2~3倍,此外每个hdfs块的大小是64M,那么Eden区域的预计大小就是:4 * 3 * 64MB,然后呢,再通过-Xmn参数,将Eden区域大小设置为4 * 3 * 64 * 4/3。

总结来看,对于垃圾回收的调优,充其量就是调节executor内存的比例就可以了。因为jvm的调优是非常复杂和敏感的。除非是,真的到了万不得已的地方,然后呢,自己本身又对jvm相关的技术很了解,那么此时进行eden区域的调节,调优,是可以的。
一些高级的参数:
- -XX:SurvivorRatio=6 ,设置的是Eden区与每一个Survivor区的比值,可以反推出占新生代的比值,Eden为6, 两个Survivor为2, Eden占新生代的3/4, 每个Survivor占1/8,两个占1/4。所以,可以尝试调大Survivor区域的大小;
- -XX:NewRatio=4:调节新生代和老年代的比例,即年轻代为老年代的1/4;
- -XX:Newsize : 设置Yong Generation的初始值大小
- -XX:Maxnewsize:设置Yong Generation的最大值大小
- -Xms:初始Heap大小
- -Xmx:java heap最大值
- -Xmn:年轻代的heap大小
- -Xss:每个线程的Stack大小
二、常用shuffle优化参数
new SparkConf().set("spark.shuffle.consolidateFiles", "true")
spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false

常见参数设置:
- spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m
- spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k
- spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
- spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s
- spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,默认0.2,超过比例就会溢出到磁盘上

举个例子:
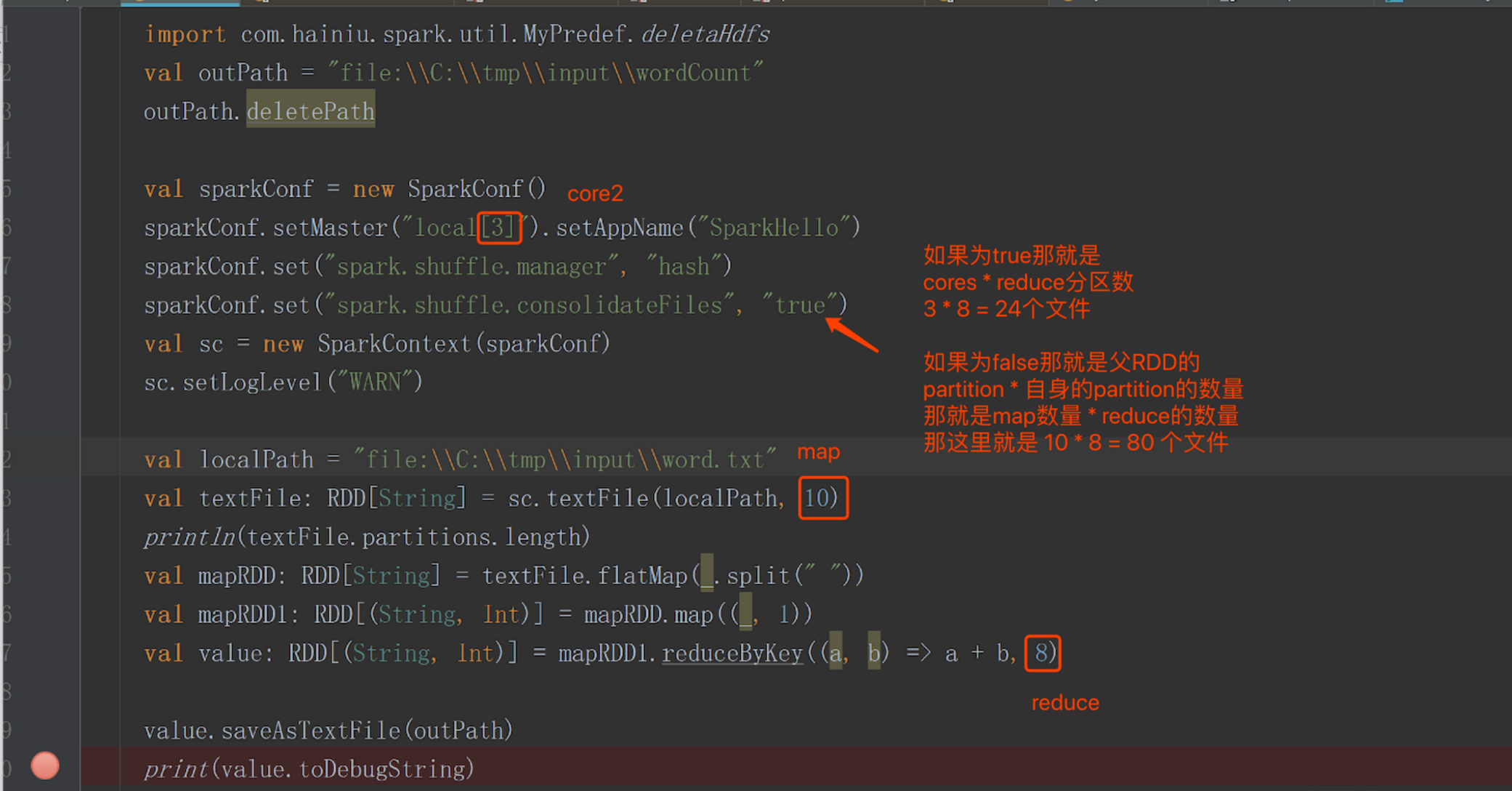
补充说明:
- 能不shuffle的时候尽量不要shuffle数据,比如使用mapjoin
- 能用reducerByKey就不要用groupByKey,因为reducerByKey会在shuffle前进行本地聚合(combiner),可以使在shuffle过程中减少磁盘IO,实在做不了情况就用groupByKey().map()
- 现在的版本是使用sortShuffleManager磁盘文件会合并排序,以前版本是每一个task都会为下一个stage的每一个task刷新一个磁盘文件。可以自己选择排序模式比如 tungsten-sort(https://www.jianshu.com/p/db3fea9c124c)
三、内存都花费在哪里了
- 每个Java对象,都有一个对象头,会占用16个字节,主要是包括了一些对象的元信息,比如指向它的类的指针。如果一个对象本身很小,比如就包括了一个int类型的field,那么它的对象头实际上比对象自己还要大。
- Java的String对象,会比它内部的原始数据,要多出40个字节。因为它内部使用char数组来保存内部的字符序列的,并且还得保存诸如数组长度之类的信息。而且因为String使用的是UTF-16编码,所以每个字符会占用2个字节。比如,包含10个字符的String,会占用60个字节。
- Java中的集合类型,比如HashMap和LinkedList,内部使用的是链表数据结构,所以对链表中的每一个数据,都使用了Entry对象来包装。Entry对象不仅有对象头,还有指向下一个Entry的指针,通常占用8个字节。
- 元素类型为原始数据类型(比如int)的集合,内部通常会使用原始数据类型的包装类型,比如Integer,来存储元素。
判断你的spark程序消耗了多少内存:
- 首先,自己设置RDD的并行度,有两种方式:在parallelize()、textFile()等方法中,传入第二个参数,设置RDD的task 或 partition的数量;要不然,用SparkConf.set()方法,设置一个参数,spark.default.parallelism,可以统一设置这个application所有RDD的partition数量。
- 其次,在程序中将RDD cache到内存中,调用RDD.cache()方法即可。
- 最后,观察web UI
-
将这个内存信息乘以partition数量,即可得出RDD的内存占用量。

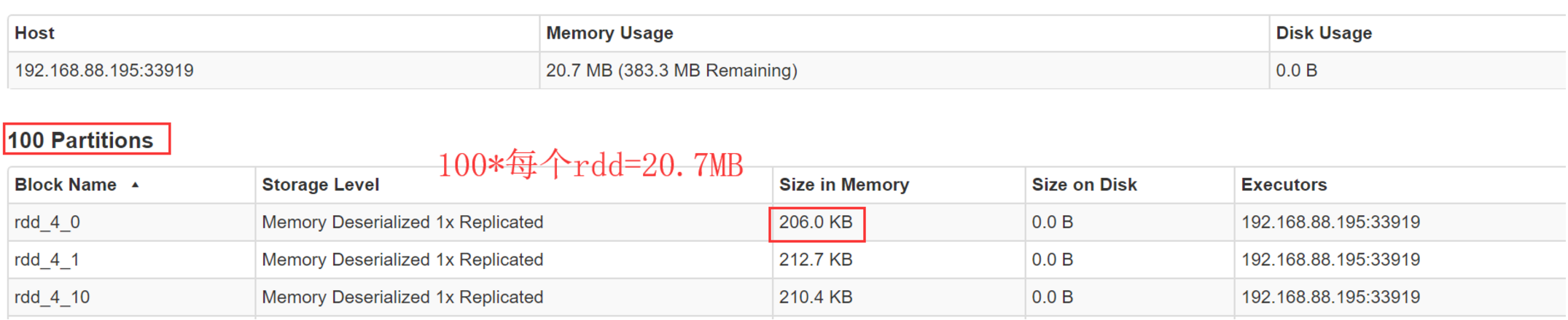
- 注意:如果你的每个分区数据大小差不多,我们选取平均值*分区数就是RDD的内存占用量,如果分区数据大小分布不均衡那就是产生了数据倾斜,先解决数据倾斜的问题,如果数据量比较大 不能全部cache就抽取部分数据cache
四、优化数据结构
要减少内存的消耗,除了使用高效的序列化类库以外,还有一个很重要的事情,就是优化数据结构。从而避免Java语法特性中所导致的额外内存的开销,比如基于指针的Java数据结构,以及包装类型。
有一个关键的问题,就是优化什么数据结构?其实主要就是优化你的算子函数,内部使用到的局部数据,或者是算子函数外部的数据。都可以进行数据结构的优化。优化之后,都会减少其对内存的消耗和占用。
- 优先使用数组以及字符串,而不是集合类。也就是说,优先用array,而不是ArrayList、LinkedList、HashMap等集合。
- 比如,有个List<Integer> list = new ArrayList<Integer>(),将其替换为int[] arr = new int[]。这样的话,array既比List少了额外信息的存储开销,还能使用原始数据类型(int)来存储数据,比List中用Integer这种包装类型存储数据,要节省内存的多。
- 还比如,通常企业级应用中的做法是,对于HashMap、List这种数据,统一用String拼接成特殊格式的字符串,比如Map<Integer, Person> persons = new HashMap<Integer, Person>()。可以优化为,特殊的字符串格式:1-id:value|address:value,2-id:value|address:value
- 避免使用多层嵌套的对象结构。比如说,public class Teacher { private List<Student> students = new ArrayList<Student>() }。就是非常不好的例子。因为Teacher类的内部又嵌套了大量的小Student对象。
- 比如说,对于上述例子,也完全可以使用特殊的字符串来进行数据的存储。比如,用json字符串来存储数据,就是一个很好的选择。
- {"teacherId": 1, "teacherName": "leo", students:[{"studentId": 1, "studentName": "tom"},{"studentId":2, "studentName":"marry"}]}
- 对于有些能够避免的场景,尽量使用int替代String。因为String虽然比ArrayList、HashMap等数据结构高效多了,占用内存量少多了,但是之前分析过,还是有额外信息的消耗。比如之前用String表示id,那么现在完全可以用数字类型的int,来进行替代。
五、对多次使用的RDD进行持久化或Checkpoint
sc.setCheckpointDir("file:/home/hadoop/checkpoint")
val file = sc.textFile("file:/home/hadoop/part-00199-143ce23d-7af4-4e89-b54a-4fe28bda429b.txt")
val fm = file.flatMap(f=>{f.split(" ")})
val pair=fm.map((_,1))
val reduce = pair.reduceByKey(_ + _)
val cache = reduce.cache()
cache.checkpoint()
cache.count()
六、数据序列化 & 使用序列化的持久化级别
数据序列化:
- spark提供了两种序列化方法,其中使用kryo序列化比较高效,具体参考:https://www.cnblogs.com/xiexiandong/p/12820457.html
使用序列化的持久化级别:
- 除了对多次使用的RDD进行持久化操作之外,还可以进一步优化其性能。因为很有可能,RDD的数据是持久化到内存,或者磁盘中的。那么,此时,如果内存大小不是特别充足,完全可以使用序列化的持久化级别,比如MEMORY_ONLY_SER、MEMORY_AND_DISK_SER等。使用RDD.persist(StorageLevel.MEMORY_ONLY_SER)这样的语法即可。
- 这样的话,将数据序列化之后,再持久化,可以大大减小对内存的消耗。此外,数据量小了之后,如果要写入磁盘,那么磁盘io性能消耗也比较小。
- 对RDD持久化序列化后,RDD的每个partition的数据,都是序列化为一个巨大的字节数组。这样,对于内存的消耗就小的多了。但是唯一的缺点就是,获取RDD数据时,需要对其进行反序列化,会增大其CPU性能开销。
- 因此,对于序列化的持久化级别,还可以进一步优化,也就是说,使用Kryo序列化类库,这样,可以获得更快的序列化速度,并且占用更小的内存空间。但是要记住,如果RDD的元素(RDD<T>的泛型类型),是自定义类型的话,在Kryo中提前注册自定义类型。
七、提高并行度
- 实际上Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源。才能充分提高Spark应用程序的性能。
- Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle的操作,就使用并行度最大的父RDD的并行度即可。
- 可以手动使用textFile()、parallelize()等方法的第二个参数来设置并行度;也可以使用spark.default.parallelism参数,来设置统一的并行度。Spark官方的推荐是,给集群中的每个cpu core设置2~3个task。
- 比如说,spark-submit设置了executor数量是10个,每个executor要求分配2个core,那么application总共会有20个core。此时可以设置new SparkConf().set("spark.default.parallelism", "60")来设置合理的并行度,从而充分利用资源。

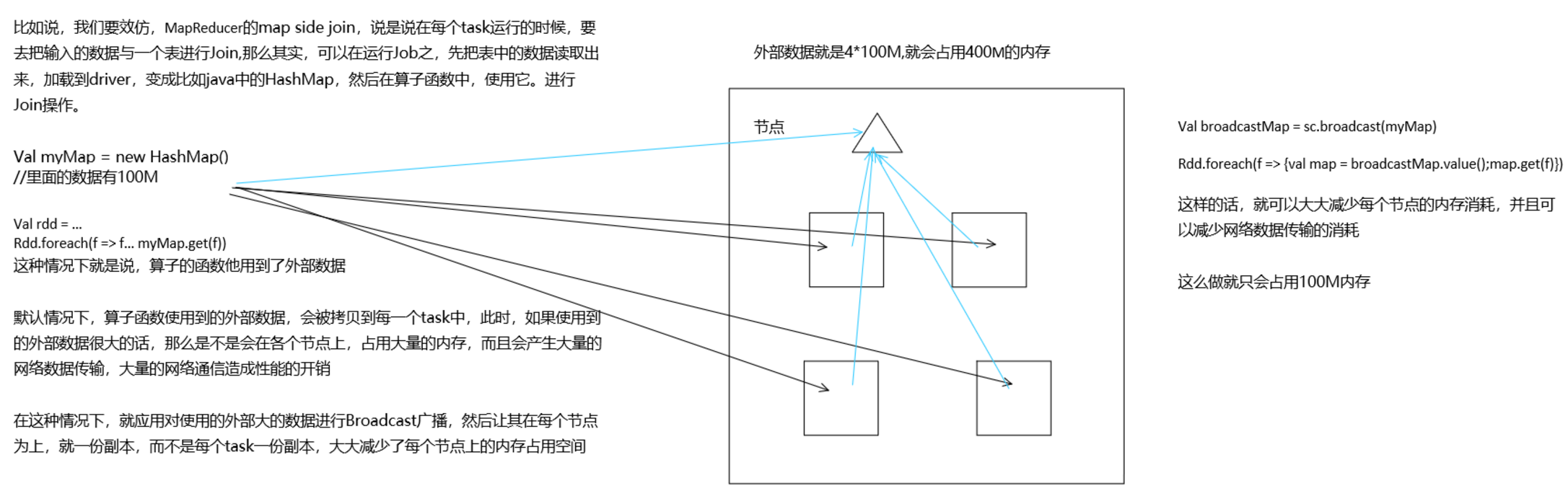
八、广播共享数据
如果你的算子函数中,使用到了特别大的数据,那么,这个时候,推荐将该数据进行广播。这样的话,就不至于将一个大数据拷贝到每一个task上去。而是给每个节点拷贝一份,然后节点上的task共享该数据。
这样的话,就可以减少大数据在节点上的内存消耗。并且可以减少数据到节点的网络传输消耗。
九、数据本地化背景(移动计算 不移动数据)
数据本地化对于Spark Job性能有着巨大的影响。如果数据以及要计算它的代码是在一起的,那么性能当然会非常高。但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上。通常来说,移动代码到其他节点,会比移动数据到代码所在的节点上去,速度要快得多,因为代码比较小。Spark也正是基于这个数据本地化的原则来构建task调度算法的。
数据本地化,指的是,数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别:
- PROCESS_LOCAL:数据和计算它的代码在同一个JVM进程中。这是最优的。
- NODE_LOCAL:数据和计算它的代码在一个节点上,但是不在一个进程中,比如在不同的executor进程中,但是尽量在读取文件(HDFS文件的block)所在的机器上
- NO_PREF:数据从哪里过来,性能都是一样的。
- RACK_LOCAL:数据和计算它的代码在一个机架上,而不再同一台机器上,因此通常需要通过单个交换机通过网络发送。
- ANY:数据可能在任意地方,比如其他网络环境内,或者其他机架上。
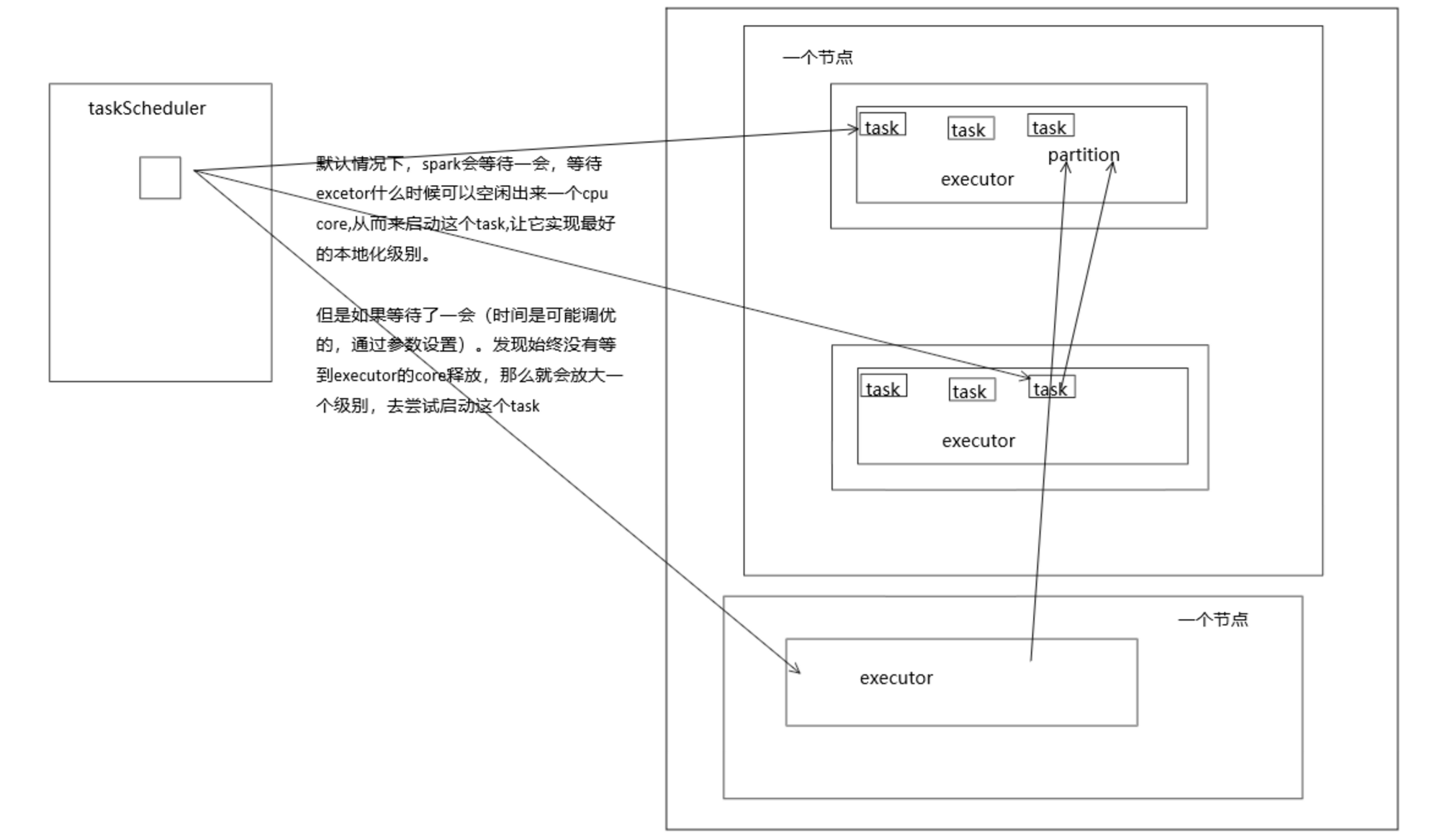
数据本地化优化
- Spark倾向于使用最好的本地化级别来调度task,但是这是不可能的。如果有任何未处理的数据在最优的executor上,那么Spark就会放低本地化级别。这时有两个选择:
- 第一,等待,直到executor上的cpu释放出来,那么就分配task过去;
- 第二,立即在任意一个executor上启动一个task。
- Spark默认会等待一会儿,来期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去。只要超过了时间,那么Spark就会将task分配到其他任意一个空闲的executor上。
- 可以设置参数,spark.locality系列参数,来调节Spark等待task可以进行数据本地化的时间。
- spark.locality.wait(3000毫秒)、spark.locality.wait.node、spark.locality.wait.process、spark.locality.wait.rack。
十、数据倾斜
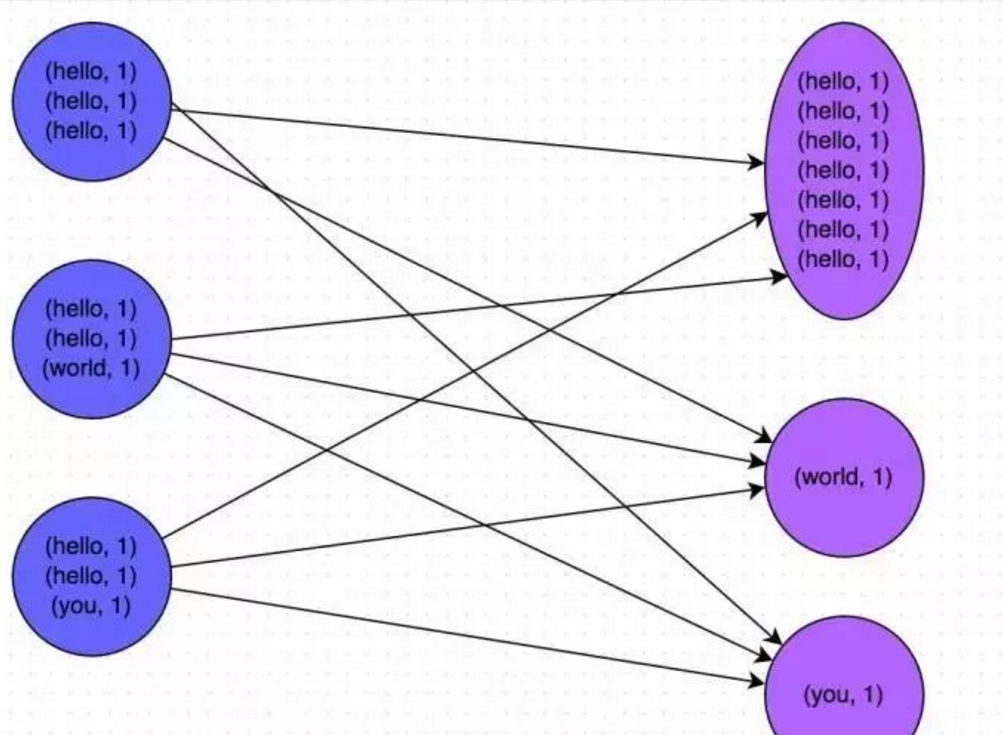
- 数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。
- 某个task执行特别慢的情况 首先要看的,就是数据倾斜发生在第几个stage中,根据stage定位到具体的算子中
10.1、可以用hive进行发生倾斜的key做聚合

10.2、进行数据的清洗,把发生倾斜的刨除,用单独的程序去算倾斜的key

10.3、提高shuffle的并行度,用随机前缀,方法是打上随机前缀先聚合一次,然后去掉随机前缀再聚合一次。适用场景groupby

10.4、指定“倍数”的数据扩容(小表的数据)加上随机“倍数”值前缀。适用场景join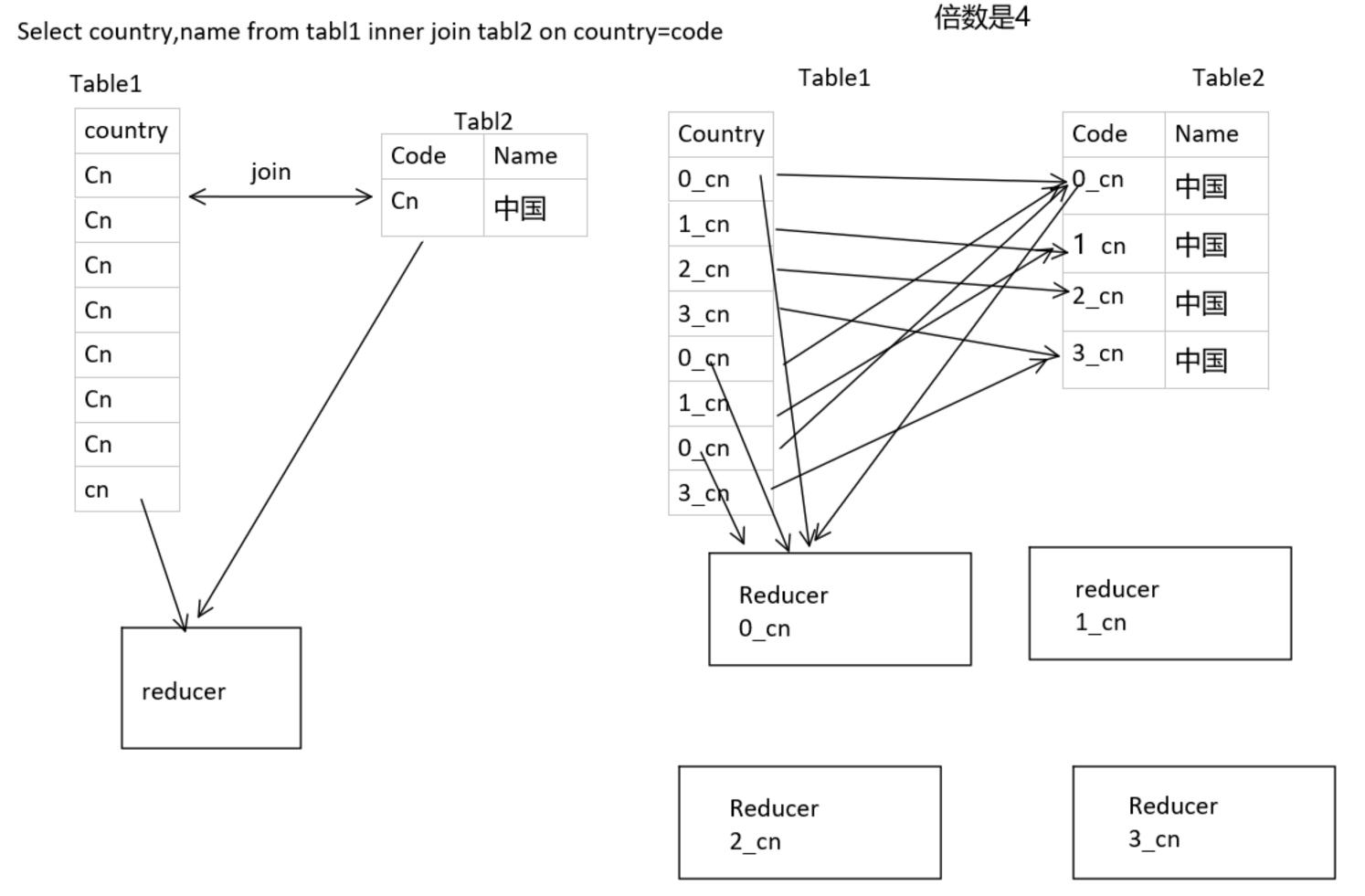
10.5、其他
- 过滤少数导致倾斜的key
- 如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
- 方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
- 将reduce join转为map join
十一、其他
- 避免创建重复的RDD
- 尽可能复用同一个RDD
- 对多次使用的RDD进行持久化,并选择合适的持久化级别。
- 减少shuffle
-
因为Spark作业运行过程中,最消耗性能的地方就是shuffle过程。shuffle过程,简单来说,就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join等操作。比如reduceByKey、join等算子,都会触发shuffle操作。
- shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,进而溢写到磁盘文件中。因此在shuffle过程中,可能会发生大量的磁盘文件读写的IO操作,以及数据的网络传输操作。磁盘IO和网络数据传输也是shuffle性能较差的主要原因。
-
因此在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销。
-
// 传统的join操作会导致shuffle操作。 // 因为两个RDD中,相同的key都需要通过网络拉取到一个节点上,由一个task进行join操作。 val rdd3 = rdd1.join(rdd2) // Broadcast+map的join操作,不会导致shuffle操作。 // 使用Broadcast将一个数据量较小的RDD作为广播变量。 val rdd2Data = rdd2.collect() val rdd2DataBroadcast = sc.broadcast(rdd2Data) // 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。 // 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的, //那么就判定可以进行join。 // 此时就可以根据自己需要的方式,将rdd1当前数据与rdd2中可以连接的数据, //拼接在一起(String或Tuple)。 val rdd3 = rdd1.map(rdd2DataBroadcast...) // 注意,以上操作,建议仅仅在rdd2的数据量比较少(比如几百M,或者一两G)的情况下使用。 // 因为每个Executor的内存中,都会驻留一份rdd2的全量数据。
-
- 使用map-side预聚合的shuffle操作
- 如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。
- 所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
- 合理选用算子:
- mappartitions和map
- foeachPartition和foreach
- 使用repartitionAndSortWithinPartitions替代repartition与sort类操作
- repartitionAndSortWithinPartitions是Spark官网推荐的一个算子,官方建议,如果需要在repartition重分区之后,还要进行排序,建议直接使用
- repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高的。
- join时,小数据join大数据,就用mapjoin(小数据放内存)
- 提交任务时设置合理的参数
-
spark-submit --master yarn --queue hadoop --num-executors 21 --executor-cores 5 --executor-memory 7G --driver-memory 6g --driver-cores 2 /home/***.jar jobName --driver-memory 6g:由于数据要汇总到driver端,同时使用了比较大的广播变量,所以driver的内存设置大一点 --driver-cores 2:由于任务比较多,而driver需要对任务进行管理,所以driver的cpu设置为2 --executor-cores:设置为5,也就是说一个executor可以同时运行5个task,每个CPU core同一时间只能执行一个task线程 --executor-memory:设置为7G,由于中间计算过程会产生大量的数据,会占用大量的内存, 所以executor的内存在集群条件允许的情况下尽量设置大一些 --num-executors:一共运行21个executor,因为默认并行度为280,所以每个rdd会同时运行280个任务 根据计算公式(2 ~ 3) * cpu = partitions,那cpu的个数为93到140之间 所以 num-executors * executor-cores = 93 ~ 140 也就是 (19 ~ 28) * 5 = 93 ~ 140 由于集群的可用计算资源为180G,所以整个任务使用的资源不能大于180G 而每个executor-memory为7G,driver-memory为6G,所以21 * 7 + 6 = 153G
-
- https://mp.weixin.qq.com/s/5Ypt-NSGs331xFSi_fMYsg