今天和搜索部门一起做了一下MQ的迁移,顺便交流一下业务和技术。发现现在90后小伙都挺不错。我是指能力和探究心。我家男孩,不招女婿。
在前面的文章中也提到,我们有媒资库(乐视视频音频本身内容)和全网作品库(外部视频音频内容),数据量级都在千万级。我们UV,PV,CV,VV都是保密的。所以作为一个合格的员工来说………………数值我也不知道。总之,这些数据作为最终数据源,要走一个跨多个部门的工作流才最终出现在用户点击搜索按钮出现的搜索框里。大体流程图如下:
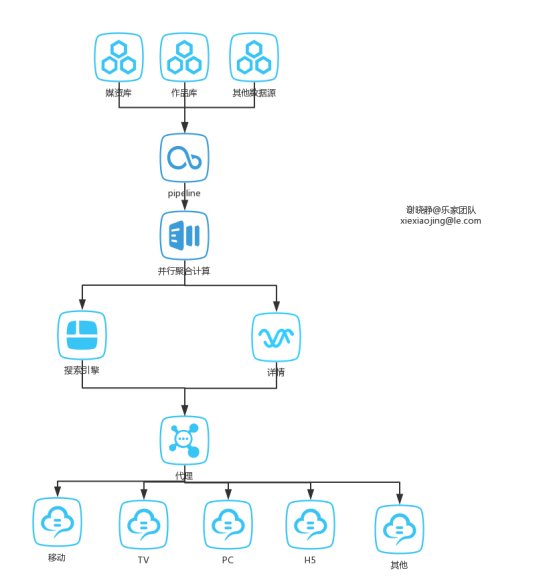
这个流程图之所以没像以往一样手绘,嗯,那是因为:钢笔放在公司了。
这里面除了两个库都在我们这边之外,其他的一个框是一个部门。我们这边给pipeline的数据交付使用的是我开发的离线服务。pipeline将各个来源的数据做重复归并处理。就是一些视频内容是一样的,但是可能来源不同或者名称有相似但可能不完全相同,而实际上是一个视频。打个比方,大学时看过一个电影叫<a Cinderella story>翻译成中文有的翻译成《灰姑娘的故事》也有翻译成《灰姑娘的玻璃手机》,但是可以根据其导演和演员表等判断其实是同一个视频。这些相同的视频要聚合成一个专辑。推举最优质的描述作为专辑的描述。展开详情有各个来源的排序后视频列表。

正常全网搜索也会将自家的视频放在前面:
这个归并处理大家可能也猜到了,并行计算嘛,用的是mapreduce。因为是视频数的组合操作,数量级是蛮大的。搜索引擎返回的是数据都是ID,真正的数据从详情部门返回。加个代理是啥意思?对调用端透明嘛,有修改只要改代理端。
搜索引擎是独立的部门,没打过交道。但是我在上家公司的公司主要负责全公司的垂直搜索,数据来源都是关系型数据库,数据量不大,当时用的是搜索引擎用的是solr。分词器用的是开源的IK分词器。因为当时公司做的是面向企业家的高端人脉,搜索对人名,公司名等的检索结果的排序有很多特殊的要求,所以当时研究过分词器的源码,也对分词器进行了一些更加切合项目的改造。比如有个需求是过滤输入的html标签。但是在Solr中对索引读入后的第一个操作就是分词,使用Solr自带的或者外部的分词器。然后再对分好的词进行更细节的过滤或者近义词之类的。但是这第一步就直接破坏了文档的结构,变成了一个个单词,而不是html文档形式。再去除很麻烦而且效率低。所以我当时的做法是直接修改了IK分词器的源码,读入数据第一个操作先过滤标签。apache有现成的工具类。这样避免了读入读出带来的性能损耗。当时也做过测试,循环跑10w次用我改造后的分词器和不改造分词器用solr过滤器过滤正则表达式的方式比的话,执行效率大约高出20倍。当时的还发现不管是solr还是ES,都是基于lucene的嘛,更适用于西文的一些检索。像中文检索不需要像西文那样需要语言处理器变小写然后再基于算法或匹配进行词根化。反而需要更多基于词典的,包括同义词,近义词这些。所以从分词这方面也是有很多的优化空间的。
个人觉得做搜索数据分析很重要。比如从日志分析中可以发现有些用户输入搜索关键词:贾跃亭,那么他很有可能对包含“乐视”关键词的信息也很有兴趣。发现了这个问题之后,我就对这类数据做了一个词库,进行了搜索和索引上一些词的双向绑定。就是相当于一个同义词的功能。建议将本文的题目放到几个搜索引擎里搜索一下,对比看看结果,挺有意思。
详情数据也是存在文档型数据库里,其实用mongoDB挺合适的。但是公司有统一的cbase集群,就直接放到cbase里了。我经常需要跟人家解释半天:cbase,couchbase,memcached都是啥关系。memcached大家都很熟悉。但是memcached不支持持久化。如果使用单纯的memcached集群,节点失效时没有任何的容错。应对措施需要交由用户处理。所以就产生了一个加强版的memcached集群:couchbase。数据层以memcached API对数据进行交互,系统在memcached程序中嵌入持久化引擎代码对数据进行缓存,复制,持久化等操作,异步队列的形式将数据同步到CouchDB中。由于它实现了数据自动在多个节点本分,单节点失效不影响业务。支持自动分片,很容易在线维护集群。cbase又是啥东西呢?这是我司对couchbase进行了一个二次开发,主要的改进点是对value的最大值进行了强行扩容:本来memcached最大Value设定是1M。我们给扩容到4M。但是慎用大的value。value值从1K到不超过1M平均分布时,实际使用容量不超过50%时性能较好。如果大value很多,达不到这个值性能就会急剧下降。
早在08年,09年的时候。facebook,mixi等国外知名互联网公司为了减少数据库访问次数,提高动态网页的访问速度,提高可扩展性,开始使用memcached。作为以facebook为标杆的人人网,这种技术也很快在其内部各个部门得到了普及。因为memcached集群采用的是服务器间互不通信的分布式方式。客户端和服务器端的通信采用的是分布式算法。这就是所说的节点失效时没有任何的容错。
这里提一个概念,就是常见的容错机制。我知道的,主要是6种。
☆ failover:失败自动切换
当出现失败,重试其他服务器,通常用于读操作,重试会带来更长延迟。
像我们的MQ客户端配置,采用是failover为roundrobin。采用轮询调度算法来容错。
☆ failfast:快速失败
只发起一次调用,失败立即报错,通常用于非幂等性的写操作。如果有机器正在重启,可能会出现调用失败。
我们的一个数据库虽然升级成了mariaDB。但是还是一主多从。这时候写入主库失败采用的就是failfast方式。
☆ failsafe:失败安全
出现异常时,直接忽略,通常用于写入日志等操作。
☆ failback:失败自动恢复
后台记录失败请求,定时重发。通常用于消息通知操作。不可靠,重启丢失。
☆ forking:并行调用多个服务器
只要一个成功即返回,通常用于实时性要求较高的读操作。需要浪费更多服务资源。
☆ broadcast
广播调用,所有提供逐个调用,任意一台报错则报错。通常用于更新提供方本地状态,速度慢,任意一台报错则报错。
读过《java并发编程实践》的朋友看到容错机制很容易会联想到java的fail-fast和fail-safe。周五和90后小伙子交流技术也正好聊到集合类的相关问题。有一个问题是在AbstractList的迭代器中,set操作做了expectedModCount = modCount。按理说不需要改变长度,为啥也要做这个操作。而实现它的子类set中都没有实现这个操作。我的想法是有一些实现set的方法有可能是通过添加删除来变相实现的。总之,继续于这个AbstractList的实现类都会检查这个expectedModCount 和 modCount的一致性。不一样会即可抛出并发修改异常,这就是failfast。而像CopyOnWriteArrayList这种的,写操作是在复制的集合上进行修改,不会抛出并发修改异常是failsafe的。