Strip Pooling: Rethinking Spatial Pooling for Scene Parsing
当前方法的不足之处
提高CNNs中远程依赖的建模能力的一种方法是采用self-attention机制或者non-local模块。但是他们会耗费内存去计算每个空间位置的相似度矩阵。
其他的远程上下文建模方法还有:
1、空洞卷积
空洞卷积主要是在没有改变参数量的基础上,扩大了卷积核的感受野。
2、全局/金字塔池化
全局/金字塔池化可以总结图像的全局信息。
然而,空洞卷积、全局/金字塔池化都只是探测方形窗口内的输入特征映射。 这限制了它们在捕捉普遍存在于现实场景中的上下文异向性的灵活性。 在某些情况下,目标对象可能具有远距离带状或分布离散的结构。 使用方性窗口不能很好地解决问题,因为它将不可避免地包含来自无关区域的污染信息。
为了更有效地捕获长依赖关系,本文在空间池化层扩大卷积神经网络感受野和捕获上下文信息的基础上,提出了条形池化(strip pooling)的概念。条形池有两个优点:
1、它沿一个空间维度部署一个长条的池化形状,能够捕获孤立区域的远程关系。
2、它沿其他空间维度保持一个狭窄的池化形状,有利于捕获上下文,并防止无关区域的污染信息干扰预测。
这种条形池化可以使语义分割网络能够同时聚合全局和局部上下文信息。作者提出了两种模块结构,SPM、MPM。
Strip Pooling Module(SPM)
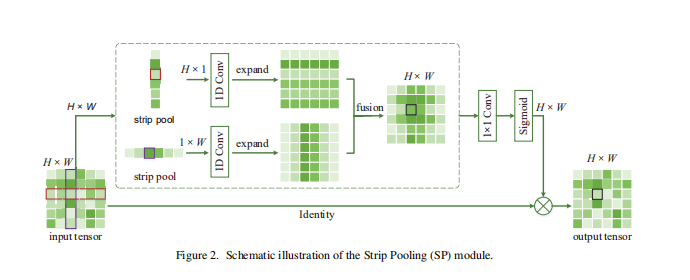
SPM有俩个分支,一个沿着竖直方向池化,另一个沿着水平方向池化。
1、输入的特征图经过水平和竖直条纹池化后变为H×1和1×W。
2、经过卷积核为3的1D卷积对两个输出feature map进行扩充,使扩充后两个分支的特征图维度一致,然后两个特征图对应位置求和。
3、然后经过1×1的卷积与sigmoid,得到一个权重矩阵,原始输入同权重矩阵对应位置相乘得到最终输出结果。
Mixed Pooling Module(MPM)
金字塔池模型(PPM)被证明是很有效方法。d但PPM严重依赖于标准的池化操作。作者提出了混合池模块(MPM),将条形池化与PPM相结合,兼顾了标准池化和条纹池化的优点。
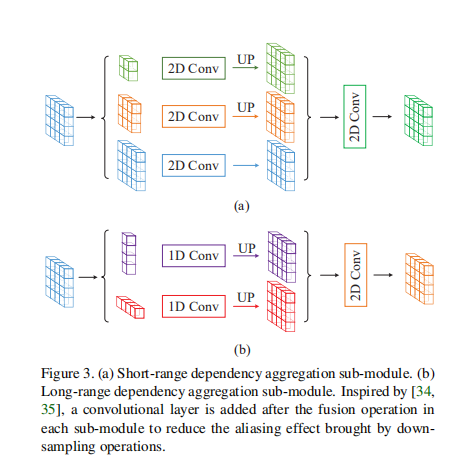
MPM由两个子模块组成,可以看到上面的模块类似于金字塔池模型,它具有两个空间池化层,然后是用于多尺度特征提取的卷积层,以及用于原始空间信息保留的2D卷积层。每次合并后的特征图的大小分别为20×20和12×12,然后通过求和将所有三个子路径合并。下面的就是前面提到的条形池化,最终结果是将两个分节结果拼接。
在每个子模块之前,首先使用1×1卷积层进行通道缩减。两个子模块的输出连接在一起,然后馈入另一个1×1卷积层,以进行通道扩展。请注意,除了用于通道缩小和扩展的卷积层之外,所有卷积层的内核大小均为3×3或3(对于一维卷积层)。
MPM其实包含了SPM这种结构,根据官方代码,自己写了一遍MPM,加了一些注释(官方代码):
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 15 15:39:10 2020
@author: xzj
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class MPMBlock(nn.Module):
def __init__(self,in_channels,pool_size):
'''
Parameters
----------
in_channels : TYPE
输入通道.
pool_size : TYPE
第一个分支中前两个通路进行池化后的尺寸.
Returns
-------
None.
'''
super(MPMBlock,self).__init__()
hide_channels = round(in_channels/4)
#数据进入两个分支前先用1x1卷积降维
self.redu_conv1 = nn.Sequential(nn.Conv2d(in_channels,hide_channels,1,bias=False),
nn.BatchNorm2d(hide_channels),
nn.ReLU(inplace=True))
self.redu_conv2 = nn.Sequential(nn.Conv2d(in_channels,hide_channels,1,bias=False),
nn.BatchNorm2d(hide_channels),
nn.ReLU(inplace=True))
#定义第一个分支的操作
#可以注意到有三个分路,其中最下面的并没有进行池化,所以我们定义两个池化层
self.pool1_1 = nn.AdaptiveAvgPool2d(pool_size[0])
self.pool1_2 = nn.AdaptiveAvgPool2d(pool_size[1])
#接着定义这三个分路的卷积层
self.conv1_1 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,3,1,1,bias=False),
nn.BatchNorm2d(hide_channels))
self.conv1_2 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,3,1,1,bias=False),
nn.BatchNorm2d(hide_channels))
self.conv1_3 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,3,1,1,bias=False),
nn.BatchNorm2d(hide_channels))
#接着定义将上面三个卷积层输出相加后,再进行的卷积操作
self.conv1_4 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,3,1,1, bias=False),
nn.BatchNorm2d(hide_channels),
nn.ReLU(True))
#定义第二个分支的操作
#首先是两个条形池化,这里用的是1x3和3x1
self.pool2_1 = nn.AdaptiveAvgPool2d([1,None])#例如32x3x64x64的输入经过这一步操作,得到输出32x3x1x64
self.pool2_2 = nn.AdaptiveAvgPool2d([None,1])
#接着是两个卷积层扩充条形池化的结果
#注意此处使用的卷积核也是条形的
self.conv2_1 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,(1,3),1,(0,1),bias=False),
nn.BatchNorm2d(hide_channels))
self.conv2_2 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,(3,1),1,(1,0),bias=False),
nn.BatchNorm2d(hide_channels))
#接着定义将上面两个卷积层输出相加后,再进行的卷积操作
self.conv2_3 = nn.Sequential(nn.Conv2d(hide_channels,hide_channels,(3,1),1,(1,0),bias=False),
nn.BatchNorm2d(hide_channels),
nn.ReLU(inplace=True))
#最后将两个分支的结果拼接起来,进行卷积升维,使维度同原始输入一致
self.conv3 = nn.Sequential(nn.Conv2d(hide_channels*2,in_channels,1,bias=False),
nn.BatchNorm2d(in_channels))
def forward(self,x):
#F.interpolate是将输入数据上采样或者下采样到你输入的维度,可以指定采样方法等,有些复杂,并未深入研究
#通过F.interpolate就可以使多个分支的输出维度保持一致,方便后面操作
_,_,h,w = x.shape
x1 = self.redu_conv1(x)
x2 = self.redu_conv2(x)
x1_1 = F.interpolate(self.conv1_1(self.pool1_1(x1)),(h,w))
x1_2 = F.interpolate(self.conv1_2(self.pool1_2(x1)),(h,w))
x1_3 = self.conv1_3(x1)
x1 = self.conv1_4(F.relu(x1_1 + x1_2 + x1_3))
print(x1.shape)
x2_1 = F.interpolate(self.conv2_1(self.pool2_1(x2)),(h,w))
x2_2 = F.interpolate(self.conv2_2(self.pool2_2(x2)),(h,w))
x2 = self.conv2_3(F.relu(x2_1+x2_2))
out = F.relu(self.conv3(torch.cat([x1,x2],dim=1))) #在channel维度拼接
return out + x