计算机设计师致力于提升他们设计的机器的性能。提升时钟速度是让运行芯片更快的一种方法,但是任何新的设计都不得不受限于当时的历史环境。因此,大部分计算机体系结构在给定时钟速度的情况下,依靠并行(同时处理两件或以上的事务)来获得更多性能。
并行分为指令级并行和处理器级并行两种。前者的并行指的是运用内部独立指令来获取更多的指令输出。后者的并行指的是多个CPU同时运行来解决相同的问题。两种方案各有优势。在本节我们将研究指令级并行;下一节我们研究处理器级并行。
流水线
众所周知,从内存中读取指令这一过程是影响指令执行速度的一大瓶颈。为了缓和这个问题,老古董IBM Stretch(1959)能提前从内存中读取指令,这样当用到这些指令时,它们已经被读取过了。这些指令被存在一组特殊的寄存器中,它就是预取缓冲器。这样,当需要一个指令时,通常从缓冲器中取出而不是等待内存读取完成。
实际上,预取指令的执行可以分为两部分:读取和实际执行。流水线得概念更加深入的执行了这个策略。相比于仅仅被分成两部分,指令的执行通常被分为许多部分(十几个或更多),每个部分由专门的一块硬件处理,所有部分可以并行执行。
图2-4(a)表示一个五单元流水线。第一步从内存读取指令,然后把它放入缓冲区直到被取出。第二步对指令解码,获取指令类型和它需要的操作子。第三步定位并获取操作子,每个操作子都是从内存或寄存器中读取。第四步才实际上执行指令,典型的就是通过图2-2的数据路径执行操作数。最后的第五步把结果写回到合适的寄存器中。

在图2.4(b),我们看到流水线怎样以函数时间执行。在时钟循环1中,S1正在执行指令1,从内存中读取指令。在循环2中,S2对指令1解码,与此同时S1在读取指令2。在循环3中,S3读取指令1的操作数,S2解码指令2,S1请求第三条指令。在循环4,S4执行指令1,S3读取指令2的操作数,S2解码指令3,S1请求指令4。最后,在循环5,S5写回指令1的结果,同时其他阶段执行后面的指令。
为了搞清楚流水线的概念,我们作个类比。设想一个蛋糕工厂,对蛋糕的烘焙和打包是分开做的。假设打包部分由5个工人和一条传送带完成。每10秒(就是时钟周期啦),工人1在传送带上放置一个空的蛋糕盒子。盒子被传送带送到工人2那里,工人2网盒子里放了一个蛋糕。过一会,盒子送到了工人3那里,工人3把盒子关上,系好带子。然后到工人4在盒子上贴标签。最后,工人5把蛋糕从传送带上拿下来,把它放到了更大的容器里,这个容器会被送到超市。基本上,这也是计算机流水线的工作方式:每个指令(蛋糕)在完成之前都要经过若干处理步骤。
让我们回到图2-4的流水线,假设某台机器的时钟周期是2纳秒。然后一路执行完这个5阶段流水线花费10纳秒。乍一看,一个指令花费10纳秒,显得机器可以运行到100MIPS的样子,但是实际上它运行的要快得多。在每个时钟周期(2纳秒),一个新指令就完成了,所以处理过程的实际速度是500MIPS,不是100MIPS。
流水线可以在延迟(执行一条指令要花费多长时间)和处理器带宽(CPU有多少MIPS)之间做权衡。有一个时钟周期为T纳秒,阶段数为n的流水线,延迟是nT纳秒,因为每个指令经过n个阶段,每个阶段花费T纳秒。
由于每个时钟周期执行一条指令,且每秒有10的9次方/T个时钟周期,那每秒执行的指令数就是10的9次方/T个。比如说,如果T等于2纳秒,那每秒能执行5亿条指令。为了获取MIPS的数量,我们以百万为单位来拆分指令的执行率,比如(10的9次方/T)/10的6次方等于1000/T MIPS。理论上我们可以用BIPS来代替MIPS来衡量指令的执行速率,但是没人那样干,所以我们也不会讨论了。
超标量结构
一个流水线已经很好,两个岂不是更好?有两个流水线的CPU可能会按照图2-5来设计。这里是一个简单的指令请求单元,成对的请求指令并把每个指令放到对应的流水线上,连同算术逻辑单元一起做并行操作。为了确保能并行执行,这两条指令在资源使用(比如寄存器)上不能有冲突,一个也不能依赖另一个的结果。正如单个流水线,编译器要么必须维持(比如,硬件不会检查指令的兼容性,对不兼容的指令会给出错误的结果)这种不冲突状态,要么能使用额外的硬件检测并消除冲突。
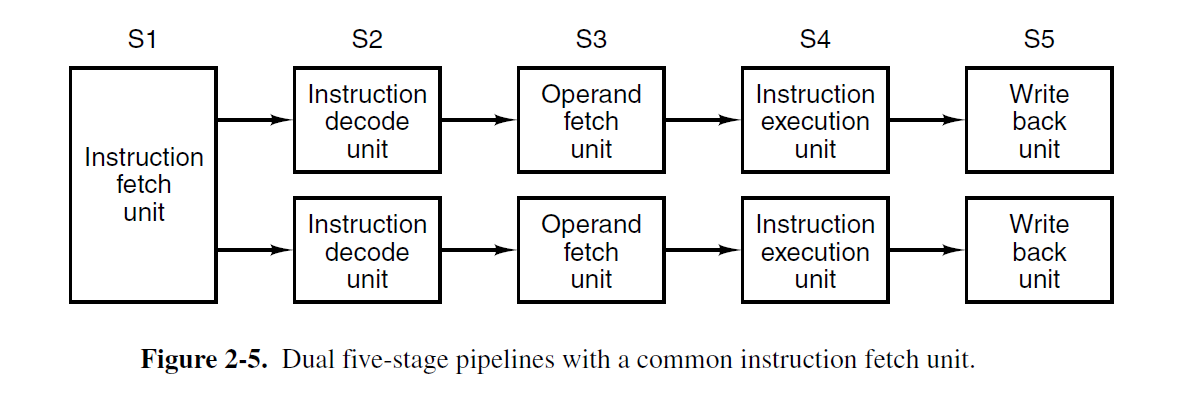
无论单个还是一对流水线,起初都是用在RISC机器上(386和它的前任并没有),从486开始,英特尔开始在CPU里引进流水线。486有一个流水线,最早的奔腾有两条五阶段流水线,和图2-5相仿,虽然阶段2和阶段3(称作解码1和解码2)工作内容的准确划分和我们的例子相比有些许不同。主流水线,也称作u流水线,可以执行任意的奔腾指令。次流水线,又称作v流水线,能执行简单的整数指令(还有一个简单的浮点指令FXCH)。
由固定规则来判断一对指令是否互相兼容,兼容的话可以并行执行。如果这对指令不是足够简单或者不能互相兼容,那么只有第一条会被执行(在u流水线)。次流水线上的指令会保留下来,然后和下一条指令结成一对。指令总是按顺序执行。因此奔腾特有的编译器通过生产兼容的指令对,可以获得比老式编译器更好的执行速度。据度量,运行充分的崩腾处理器的执行速度是相同时钟周期的486处理器的两倍(Pountain,1993)。这个功劳可以全部算在次流水线头上。
4流水线齐上不是无法想象的场景,只是这样做要复制太多的硬件(计算机科学家并不像民间百姓那样笃信数字3)。在高端CPU上用了替代方法。基本思想是只有一条流水线,但是给它多个功能单元,如图2-6所示。比如Intel Core体系有一个和2-6很相似的结构。我们会在第四章讨论该内容。术语超标量体系结构就是为了描述该方法而产生的(Agerwala和Cocke,1987)。它的根源可以追溯到40年前的CDC 6600。6600每100纳秒请求一条指令,然后转移到10个功能单元中的一个去并行执行,同时CPU获取下一条指令。
“超标量”的定义是慢慢形成的。它现在表示处理器能在一个时钟周期内能输出多条指令(通常四或六个)。当然,一个超标量CPU必须有多个功能单元来处理这些指令。因为超标量处理器通常有一个流水线,他们看起来像图2-6。
根据这个定义,6600在技术上并不是超标量的,因为它每个时钟周期只能输出一条指令。然而效果是一样的:指令在以比原本更快的速度执行着。一个有着100-纳秒时钟,每个周期输出一条指令给功能单元的的CPU和一个有着400-纳秒时钟,每个时钟周期输出一条指令给功能单元的CPU在概念上的区别是很小的。关键点是指令的输出速率比执行速度要快的多。
超标量处理器思想中隐藏的含义是,S3阶段能输出大量指令,超过了S4阶段消化指令的能力。如果S3阶段每10纳秒输出一条指令,并且所有的的功能单元都能在10毫秒内完成它们的工作,同一时刻不会有两个功能单元在忙,那么整个想法就不能生效了。实际上,大部分位于阶段4的功能单元的执行时间都明显超过一个时钟周期,那些读取内存或做浮点计算的功能单元肯定会。如图所示,阶段4可能有多个算术逻辑单元。
