计算机内存偶尔会因为电线上的电压电流,宇宙射线或其他因素而犯错。为了防止这些错误,一些内存使用了侦错码或纠错码。当使用这些编码时,额外的位会以特殊的方式附加到每个内存字上。当从内存读出一个字时,通过检查这些额外的位来确认是否有错误发生。
为了理解怎样处理错误,有必要近距离看看错误到底是什么样子的。假设一个内存字包括m位数据,我们会加上r位的冗余或校验。假设总长度是n(n=m + r)。一个包括m位数据和r位校验的n位单元通常被称作n位码字。
任意给出两个码字,比如,10001001和10110001,找出有几个对应位不同是可能的。上面的例子有3位不同。为了找出几位不同,只要按位计算两个码字的异或,然后统计结果中1的数量就好了。两个码字中不同的比特位数称作汉明距离(Hamming,1950)。意思是,如果两个码字的汉明距离是d,它们的互相转化需要d位错误。比如,码字11110001和00110000的汉明距离是3,因为把一个转化成另一个需要有3位的错误。
有一个m位的内存字,所有2^m个位图都是合法的,考虑到位校验时的计算方式,只有2^n个码字是可用的。如果读取内存时出现了未验证的码字,计算机就知道发生了内存错误。给出计算校验位的算法,构建一个完整的合法码字列表是可能的,然后从这个列表中找出汉明距离最小的两个码字。这个距离就是整组编码的汉明距离。
编码作为侦错码和纠错码的能力取决于它们的汉明距离。为了检查出d比特的错误,需要距离d+1位的编码,因为有了这样一个编码,d位错不可能把一个合法的码字变成另一个合法码字。类似地,为了纠正d位错,需要距离为2d+1的编码,那样的话,合法的码字距离那些只有d位变化的码字还很远(汉明距离是d+1),源码字与其他码字相比仍然近一些(汉明距离是d),所以它就是唯一确定的。
作为纠错码的简单例子,考虑在数据后插入一个校验位形成的编码。校验位是可选的,所以码字中1的数量可以是偶数(或者基数)。这样一个编码的汉明距离是2,因为任意一位错都会产生奇偶错误的码字。换句话说,从一个合法的码字变成另一个合法码字需要2位错。它可以用于检测错误。无论何时,从内存读出的字如果有奇偶错误,说明错误已经发生。虽然程序无法继续执行,但至少不会产生错误结果。
作为纠错码的简单例子,考虑只有四个合法码字的一组编码。
0000000000, 0000011111,1111100000, 1111111111
这组编码的汉明距离是5,意味着它能纠正两位错误。如果接收方收到0000000111,他知道初始数据一定是0000011111(假设不超过两位错)。然而,三位错能把0000000000变成0000000111,这个错误就无法纠正了。
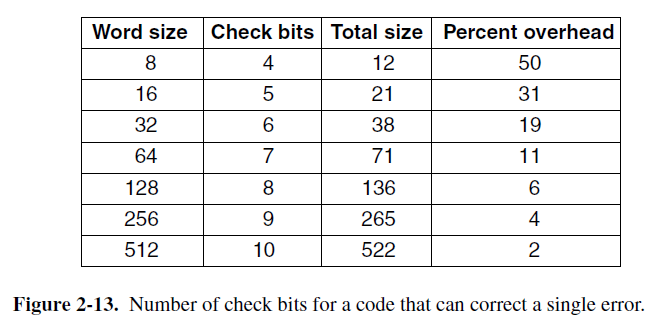
假设我们设计了一组编码,有m位数据和r位校验,该编码允许纠正所有的一位错。2^m个合法内存字中的每一个都有n个汉明距离为1的非法码字。这些码字是由n位码字变化n位中的任意一位所产生的。因此2^m个合法内存字中的每一个都需要n+1个位模式(n个错误模式和1个正确模式)。既然位模式的总数是2^n,我们有(n+1)2^m<=2^n。若n=m+r成立,则(m+r+1)<=2^r。给定m,它给出了纠正一位错所需校验位数的限制。图2-13展示了几种不同大小的内存字所需的校验位数。
这种理论上的限制可以用Richard Hamming(1950)的一个方法来实现。在介绍Hamming的方法之前,让我们看一个简单的图形,清楚地表明了四位字纠错码的概念。图2-14(a)的韦恩图包括三个圆,A,B和C,总共形成了七个区域。举个例子,让我们在区域AB,ABC,AC和BC中编码4位内存字(按字母排序)。编码如图2-14(a)所示。

接下来我们给每个空白区域增加校验位,如图2-14(b)。按定义,A,B,C三个圆中的每一个的区域位和都是偶数。在圆A中,我们有四个数0,0,1和1,加在一起是2,一个偶数。在圆B中,数字是1,1,0和0,加在一起是2,偶数。最后,在圆C,是一样的结果。在这个例子中所有的圆都一样,在其他例子中0和4也是可能的。这个数字相当于4个数据位和3个校验位的码字。
现在假设AC区域中的位坏掉,从0变成1,如图2-14(c)。计算机现在能知道圆A和C校验错误(偶数)。把AC区域重设为0,仅仅一位变化就可纠正这个错误。这样,计算机能自动地修复一位内存错误。
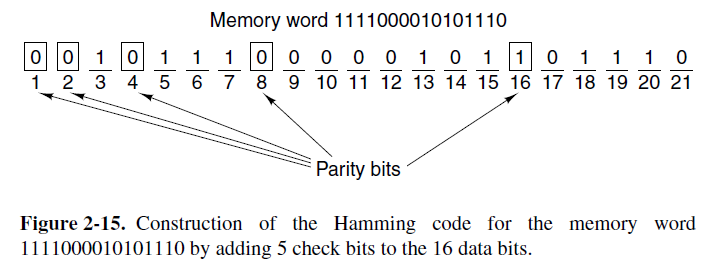
现在让我们看下怎样使用汉明算法给任意大小的内存字构建纠错码。在汉明码中,r位校验位被穿插在m位字中,形成了一个长度为m+r的新字。位编号从1开始,不是0,从最左边的位开始。所有位编号为2的乘幂的位都是校验位;剩下的是数据位。比如,有一个16位的字,添加了5个校验位。位1,2,4,8和16是校验位,剩下的位是数据位。这个内存字共有21位(16位数据和5位校验)。在这个例子中我们将用(任意地)偶校验。
每个校验位检查特定的位编号;由于设置了校验位,所以已检查的位中1的总数是偶数。被校验位检查的位编号是:
位1检查位1,3,5,7,9,11,13,15,17,19,21
位2检查位2,3,6,7,10,11,14,15,18,19
位4检查位4,5,6,7,12,13,14,15,20,21
位8检查位8,9,10,11,12,13,14,15
位16检查位16,17,18,19,20,21
一般说来,位b被b1,b2,…,bj这些位检查,如此b1+b2+…+bj=b。比如位5被位1和位4检查因为1+4=5。位6被位2和位4检查因为2+4=6,如此等等。
图2-15展示了16位内存字1111000010101110怎样构建汉明码。21位的码字是001011100000101101110。为了搞清纠错码是怎样工作的,考虑如果位5由于电线上电流激增而发生变化。新的码字就是001001100000101101110而不是001011100000101101110。5个校验位会被检查,结果如下:
校验位1错误(1,3,5,7,9,11,13,15,17,19,21这些位包含5个1)
校验位2正确(2,3,6,7,10,11,14,15,18,19这些位包含6个1)
校验位4错误(4,5,6,7,12,13,14,15,20,21这些位包含5个1)
校验位8正确(8,9,10,11,12,13,14,15这些位包含2个1)
校验位16正确(16,17,18,19,20,21包含4个1)
在位1,3,5,7,9,11,13,15,17,19和21中,1的总数应当是偶数,一位用的是偶校验。不正确的位一定在校验位1所校验的位中,也就是位1,3,5,7,9,11,13,15,17,19或21。校验位4不正确,意味着位4,5,6,7,12,13,14,15,20或21中有一位不正确。错误位一定同时在两个列表中,也就是5,7,13,15或21。然而,校验位2是正确的,排除7和15。同理,校验位8是正确的,排除13。最后,校验位16是正确的,排除21。仅仅剩下位5,就是那个错误位。既然它现在是1,那它本该是0。如此,错误可以被纠正。
有一个简单的方法来找出错误位:首先计算出所有的校验位。如果校验位都是正确的,就没有错(或超过一位错)。然后把不正确的校验位相加,位1就是1,位2就是2,位4就是4,等等。和就是不正确位的编号。比如,如果检验位1和4不正确但2,8,16正确,则位5(1+4)被修改了。