一、分片策略
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sharding/
Sharding-JDBC 中的分片策略有两个维度:分库(数据源分片)策略和分表策略。分库策略表示数据路由到的物理目标数据源,分表分片策略表示数据被路由到的目标表。分表策略是依赖于分库策略的,也就是说要先分库再分表,当然也可以不分库只分表。跟 Mycat 不一样,Sharding-JDBC 没有提供内置的分片算法,而是通过抽象成接口,让开发者自行实现,这样可以根据业务实际情况灵活地实现分片。
1.1、分片策略
包含分片键和分片算法,分片算法是需要自定义的。可以用于分库,也可以用于分表。由于分片算法和业务实现紧密相关,因此Sharding-JDBC并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。Sharding-JDBC 提供了 5 种分片策略(接口),策略全部继承自 ShardingStrategy,可以根据情况选择实现相应的接口。
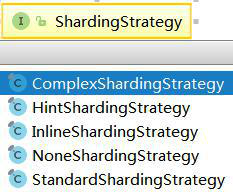
StandardShardingStrategy
标准分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
-
- PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
- RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
ComplexShardingStrategy
复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此Sharding-JDBC并未做过多的封装,而是直接将分片键值组合以及分片操作符交于算法接口,完全由应用开发者实现,提供最大的灵活度。
InlineShardingStrategy
Inline表达式分片策略。使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持。
InlineShardingStrategy只支持单分片键,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: tuser${user_id % 8} 表示t_user表按照user_id按8取模分成8个表,表名称为t_user_0到t_user_7。
HintShardingStrategy
通过Hint而非SQL解析的方式分片的策略。
NoneShardingStrategy
不分片的策略。
1.1.1 、行表达式分片策略
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/inline-expression/
对应 InlineShardingStrategy 类。只支持单分片键,提供对=和 IN 操作的支持。行内表达式的配置比较简单。
例如:
${begin..end}表示范围区间
${[unit1, unit2, unit_x]}表示枚举值
t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7。
行表达式中如果出现连续多个${ expression }或$->{ expression }表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
例如,以下行表达式:
${['db1', 'db2']}_table${1..3}
最终会解析为:
db1_table1, db1_table2, db1_table3,
db2_table1, db2_table2, db2_table3
1.1.2 、标准分片策略(StandardShardingStrategy)
对应 StandardShardingStrategy 类。
标准分片策略只支持单分片键,提供了提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法,分别对应于 SQL 语句中的=, IN 和 BETWEEN AND。
如果要使用标准分片策略,必须要实现 PreciseShardingAlgorithm,用来处理=和 IN 的分片。RangeShardingAlgorithm 是可选的。如果没有实现,SQL 语句会发到所有的数据节点上执行。
玩起来也特别简单
测试类
mybatis.mapper-locations=classpath:mapper/*.xml mybatis.config-location=classpath:mybatis-config.xml
@RunWith(SpringRunner.class) @SpringBootTest @Slf4j public class test { @Resource UserService userService; /** * 先执行插入 */ @Test public void insert(){ userService.insert(); } @Test public void select(){ UserInfo userInfo1= userService.getUserInfoByUserId(532299550304501761L); System.out.println("------userInfo1:"+userInfo1); UserInfo userInfo2= userService.getUserInfoByUserId(532299547905359872L); System.out.println("------userInfo2:"+userInfo2); } }
@Configuration @MapperScan(basePackages = "com.ghy.shardingjdbccostom.mapper", sqlSessionFactoryRef = "sqlSessionFactory") public class DataSourceConfig { @Bean @Primary public DataSource shardingDataSource() throws SQLException { // 配置真实数据源 Map<String, DataSource> dataSourceMap = new HashMap<>(); // 配置第一个数据源 DruidDataSource dataSource1 = new DruidDataSource(); dataSource1.setDriverClassName("com.mysql.cj.jdbc.Driver"); dataSource1.setUrl("jdbc:mysql://localhost:3306/ds0?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8"); dataSource1.setUsername("root"); dataSource1.setPassword("root"); dataSourceMap.put("ds0", dataSource1); // 配置第二个数据源 DruidDataSource dataSource2 = new DruidDataSource(); dataSource2.setDriverClassName("com.mysql.cj.jdbc.Driver"); dataSource2.setUrl("jdbc:mysql://localhost:3306/ds1?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8"); dataSource2.setUsername("root"); dataSource2.setPassword("root"); dataSourceMap.put("ds1", dataSource2); // 配置Order表规则 TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("user_info", "ds${0..1}.user_info"); // 分表策略,使用 Standard 自定义实现,这里没有分表,表名固定为user_info StandardShardingStrategyConfiguration tableInlineStrategy = new StandardShardingStrategyConfiguration("user_id", new TblPreShardAlgo(),new TblRangeShardAlgo()); orderTableRuleConfig.setTableShardingStrategyConfig(tableInlineStrategy); // 分库策略,使用 Standard 自定义实现 StandardShardingStrategyConfiguration dataBaseInlineStrategy =new StandardShardingStrategyConfiguration("user_id", new DBShardAlgo()); orderTableRuleConfig.setDatabaseShardingStrategyConfig(dataBaseInlineStrategy); // 添加表配置 ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig); // 获取数据源对象 DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties()); return dataSource; } // 事务管理器 @Bean public DataSourceTransactionManager transactitonManager(DataSource shardingDataSource) { return new DataSourceTransactionManager(shardingDataSource); } }
public class DBShardAlgo implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) { String db_name="ds"; Long num = preciseShardingValue.getValue()%2; db_name = db_name + num; for (String each : collection) { if (each.equals(db_name)) { return each; } } throw new IllegalArgumentException(); } }
public class TblPreShardAlgo implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingColumn) { // 不分表 for (String tbname : availableTargetNames) { return tbname ; } throw new IllegalArgumentException(); } }
public class TblRangeShardAlgo implements RangeShardingAlgorithm<Long> { @Override public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> rangeShardingValue) { System.out.println("范围-*-*-*-*-*-*-*-*-*-*-*---------------"+availableTargetNames); System.out.println("范围-*-*-*-*-*-*-*-*-*-*-*---------------"+rangeShardingValue); Collection<String> collect = new LinkedHashSet<>(); Range<Long> valueRange = rangeShardingValue.getValueRange(); for (Long i = valueRange.lowerEndpoint(); i <= valueRange.upperEndpoint(); i++) { for (String each : availableTargetNames) { if (each.endsWith(i % availableTargetNames.size() + "")) { collect.add(each); } } } // return collect; } }
其它业务层和数据库层代码和以前写法一样,后面代码会发布,就不一一搞了
1.1.3 、复合分片策略
比如:根据日期和 ID 两个字段分片,每个月 3 张表,先根据日期,再根据 ID 取模。对应 ComplexShardingStrategy 类。可以支持等值查询和范围查询。复合分片策略支持多分片键,提供了 ComplexKeysShardingAlgorithm,分片算法需要自己实现。由于多分片键之间的关系复杂,因此Sharding-JDBC并未做过多的封装,而是直接将分片键值组合以及分片操作符交于算法接口,完全由应用开发者实现,提供最大的灵活度
Sharding -jdbc 在使用分片策略的时候,与分片算法是成对出现的,每种策略都对应一到两种分片算法(不分片策略NoneShardingStrategy除外)
分库分表最核心的两点SQL 路由 、 SQL 改写 :
SQL 路由:解析原生SQL,确定需要使用哪些数据库,哪些数据表Route (路由)引擎:为什么要用Route 引擎呢?在实际查询当中,数据可能不只是存在一台MYSQL服务器上,
SELECT * FROM t_order WHERE order _id IN(1,3,6)
数据分布:
ds0.t_order0 (1,3,5,7) ds1.t_order0(2,4,6)
这个SELECT 查询就需要走2个database,如果这个SQL原封不动的执行,肯定会报错(表不存在),Sharding-jdbc 必须要对这个sql进行改写,将库名和表名 2个路由加上
SELECT * FROM ds0.t_order0 WHERE order _id IN(1,3) SELECT * FROM ds0.t_order1 WHERE order _id IN(6)
SQL 改写:将SQL 按照一定规则,重写FROM 的数据库和表名(Route 返回路由决定需要去哪些库表中执行SQL)

application.properties 配置
配置主要分为三个部分
- 配置数据源
- 分库配置
- 分表配置
# 复合分片 sharding.jdbc.datasource.names=ds0,ds1 sharding.jdbc.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds0.url=jdbc:mysql://127.0.0.1:5306/ds0?useUnicode=yes&characterEncoding=utf8 sharding.jdbc.datasource.ds0.username=root sharding.jdbc.datasource.ds0.password=root sharding.jdbc.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds1.url=jdbc:mysql://127.0.0.1:5306/ds1?useUnicode=yes&characterEncoding=utf8 sharding.jdbc.datasource.ds1.username=root sharding.jdbc.datasource.ds1.password=root # 分库配置 (行表达式分片策略 + 行表达式分片算法) sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2} sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item # t_order分表配置 (复合分片策略) sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}_$->{0..1} sharding.jdbc.config.sharding.tables.t_order.table-strategy.complex.sharding-columns=user_id,order_id sharding.jdbc.config.sharding.tables.t_order.table-strategy.complex.algorithm-class-name=ai.yunxi.sharding.config.ComplexShardingAlgorithm # t_order_item分表配置 (复合分片策略) sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}_$->{0..1} # 标准 和 inline 都是单分片键 ,复合分片策略可以配置则多分片键 sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.complex.sharding-columns=user_id,order_id # 自定义算法,让使用者根据业务自定义实现(开发性接口更灵活方便) sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.complex.algorithm-class-name=ai.yunxi.sharding.config.ComplexShardingAlgorithm # 定义广播表 sharding.jdbc.config.sharding.broadcast-tables=t_province sharding.jdbc.config.props.sql.show=true
自定义ComplexShardingAlgorithm
import io.shardingsphere.api.algorithm.sharding.ListShardingValue; import io.shardingsphere.api.algorithm.sharding.ShardingValue; import io.shardingsphere.api.algorithm.sharding.complex.ComplexKeysShardingAlgorithm; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; import java.util.List; public class ComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm { /** * * @param collection 在加载配置文件时,会解析表分片规则。将结果存储到 collection中,doSharding()参数使用 * @param shardingValues SQL中对应的 * @return */ @Override public Collection<String> doSharding(Collection<String> collection, Collection<ShardingValue> shardingValues) { System.out.println("collection:" + collection + ",shardingValues:" + shardingValues); Collection<Integer> orderIdValues = getShardingValue(shardingValues, "order_id"); Collection<Integer> userIdValues = getShardingValue(shardingValues, "user_id"); List<String> shardingSuffix = new ArrayList<>(); // user_id,order_id分片键进行分表 for (Integer userId : userIdValues) { for (Integer orderId : orderIdValues) { String suffix = userId % 2 + "_" + orderId % 2; for (String s : collection) { if (s.endsWith(suffix)) { shardingSuffix.add(s); } } } } return shardingSuffix; } /** * 例如: SELECT * FROM T_ORDER user_id = 100000 AND order_id = 1000009 * 循环 获取SQL 中 分片键列对应的value值 * @param shardingValues sql 中分片键的value值 -> 1000009 * @param key 分片键列名 -> user_id * @return shardingValues 集合 -> [1000009] */ private Collection<Integer> getShardingValue(Collection<ShardingValue> shardingValues, final String key) { Collection<Integer> valueSet = new ArrayList<>(); Iterator<ShardingValue> iterator = shardingValues.iterator(); while (iterator.hasNext()) { ShardingValue next = iterator.next(); if (next instanceof ListShardingValue) { ListShardingValue value = (ListShardingValue) next; // user_id,order_id分片键进行分表 if (value.getColumnName().equals(key)) { return value.getValues(); } } } return valueSet; } }
1.1.4、 Hint 分片策略
Hint分片策略(HintShardingStrategy)相比于上面几种分片策略稍有不同,这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。ShardingSphere 通过 Hint API实现指定操作,实际上就是把分片规则tablerule 、databaserule由集中配置变成了个性化配置。
举个例子,如果我们希望订单表t_order用 user_id 做分片健进行分库分表,但是 t_order 表中却没有 user_id 这个字段,这时可以通过 Hint API 在外部手动指定分片健或分片库。
下边我们这边给一条无分片条件的SQL,看如何指定分片健让它路由到指定库表。
SELECT * FROM t_order;
使用 Hint分片策略同样需要自定义,实现 HintShardingAlgorithm 接口并重写 doSharding()方法。
/** * @author xinzhifu * @description hit分表算法 * @date 2020/11/2 12:06 */ public class MyTableHintShardingAlgorithm implements HintShardingAlgorithm<String> { @Override public Collection<String> doSharding(Collection<String> tableNames, HintShardingValue<String> hintShardingValue) { Collection<String> result = new ArrayList<>(); for (String tableName : tableNames) { for (String shardingValue : hintShardingValue.getValues()) { if (tableName.endsWith(String.valueOf(Long.valueOf(shardingValue) % tableNames.size()))) { result.add(tableName); } } } return result; } }
自定义完算法只实现了一部分,还需要在调用 SQL 前通过 HintManager 指定分库、分表信息。由于每次添加的规则都放在 ThreadLocal 内,所以要先执行 clear() 清除掉上一次的规则,否则会报错;addDatabaseShardingValue 设置分库分片健键值,addTableShardingValue设置分表分片健键值。setMasterRouteOnly 读写分离强制读主库,避免造成主从复制导致的延迟。
// 清除掉上一次的规则,否则会报错 HintManager.clear(); // HintManager API 工具类实例 HintManager hintManager = HintManager.getInstance(); // 直接指定对应具体的数据库 hintManager.addDatabaseShardingValue("ds",0); // 设置表的分片健 hintManager.addTableShardingValue("t_order" , 0); hintManager.addTableShardingValue("t_order" , 1); hintManager.addTableShardingValue("t_order" , 2); // 在读写分离数据库中,Hint 可以强制读主库 hintManager.setMasterRouteOnly();
debug 调试看到,我们对 t_order 表设置分表分片健键值,可以在自定义的算法 HintShardingValue 参数中成功拿到。
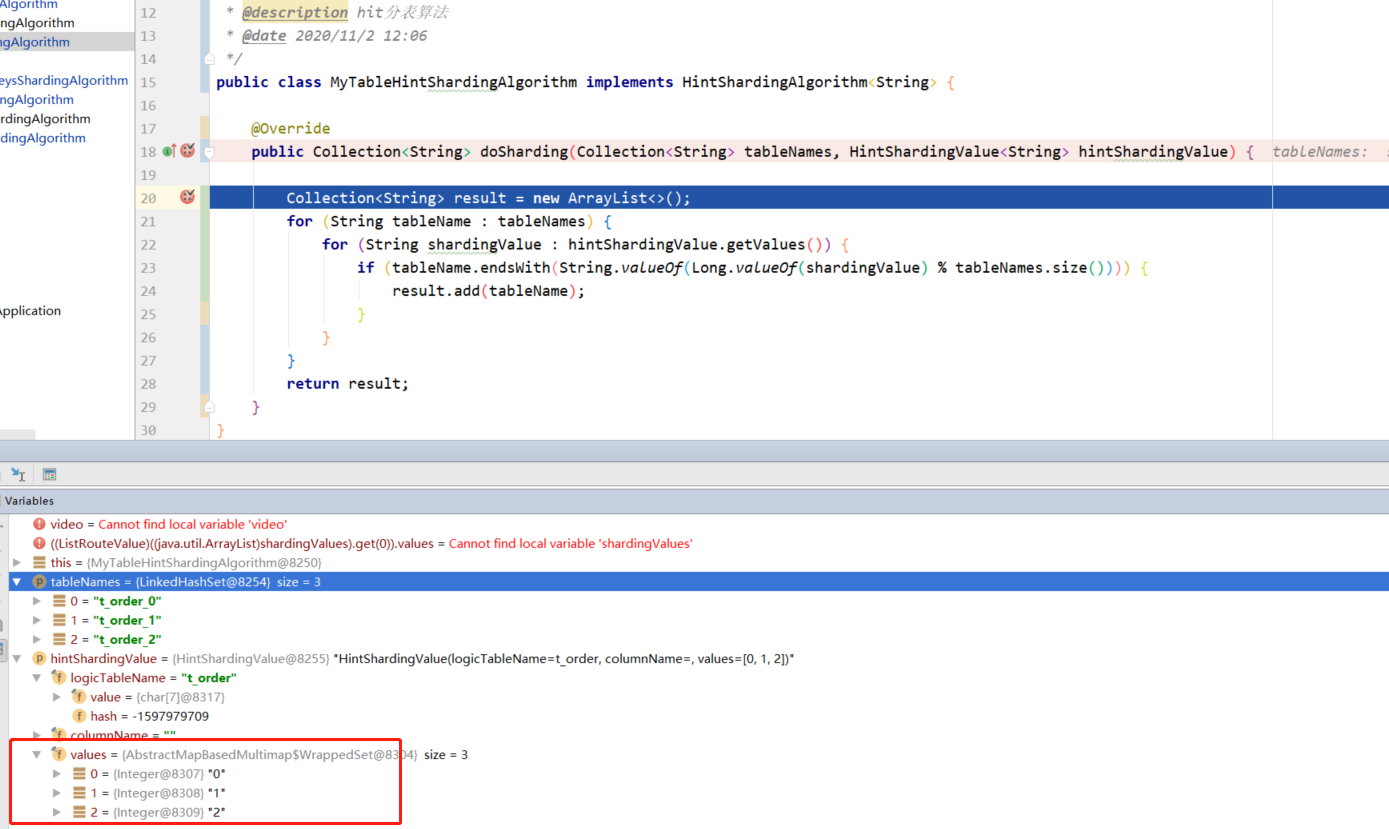
properties 文件中配置无需再指定分片健,只需自定义的 Hint分片算法类路径即可。
# Hint分片算法 spring.shardingsphere.sharding.tables.t_order.table-strategy.hint.algorithm-class-name=com.ghy.shardingjdbccostom.config.MyTableHintShardingAlgorithm
1.1.5、 不分片策略
对应 NoneShardingStrategy。不分片的策略(只在一个节点存储)。
1.2、分片算法
创建了分片策略之后,需要进一步实现分片算法,作为参数传递给分片策略。Sharding-JDBC 目前提供 4 种分片算法。
1.2.1 、精确分片算法
对应 PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与 IN 进行分片的场景。需要配合 StandardShardingStrategy 使用。
1.2.2、 范围分片算法
对应 RangeShardingAlgorithm,用于处理使用单一键作为分片键的 BETWEEN AND 进行分片的场景。需要配合 StandardShardingStrategy 使用。如果不配置范围分片算法,范围查询默认会路由到所有节点。
1.2.3 、复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。
1.2.4 、Hint 分片算法
对应 HintShardingAlgorithm ,用于处理使用 Hint 行分片的场景。 需要配合 HintShardingStrategy 使用。
二、Sharding-JDBC 总结
https://github.com/apache/shardingsphere
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/overview/
2.1、数据源选择的解决方案层次
DAO:AbstractRoutingDataSource
ORM:MyBatis 插件
JDBC:Sharding-JDBC
Proxy:Mycat、Sharding-Proxy
Server:特定数据库或者版本
2.2、基本特性
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。也就是说,在 maven 的工程里面,我们使用它的方式是引入依赖,然后进行配置就可以了,不用像 Mycat 一样独立运行一个服务,客户端不需要修改任何一行代码,原来是 SSM 连接数据库,还是 SSM,因为它是支持 MyBatis 的。跟 mycat 一样,因为数据源有多个,所以要配置数据源,而且分片规则是定义在客户端的。
2.3、架构
我们在项目内引入 Sharding-JDBC 的依赖,我们的业务代码在操作数据库的时候,就会通过 Sharding-JDBC 的代码连接到数据库。也就是分库分表的一些核心动作,比如 SQL 解析,路由,执行,结果处理,都是由它来完成的。它工作在客户端。
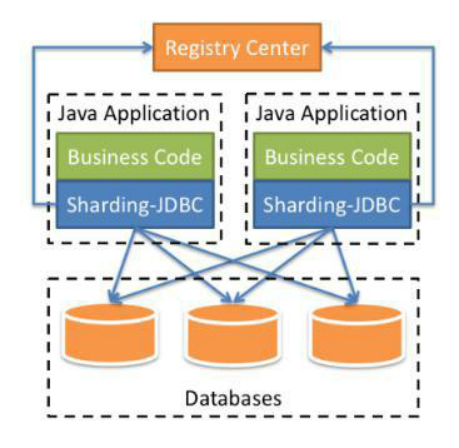
当然,在 Sharding-Sphere 里面同样提供了代理 Proxy 的版本,跟 Mycat 的作用是一样的。Sharding-Sidecar 是一个 Kubernetes 的云原生数据库代理,正在开发中

2.4、功能
分库分表后的几大问题,Sharding-JDBC 全部解决了:跨库关联查询(ER 表)、排序翻页计算、分布式事务、全局主键
2.4.1、 全局 ID
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/key-generator/
无中心化分布式主键(包括 UUID 雪花 SNOWFLAKE)使用 key-generator-column-name 配置,生成了一个 18 位的 ID。
Properties 配置:
spring.shardingsphere.sharding.tables.user_info.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user_info.key-generator.type=SNOWFLAKE
keyGeneratorColumnName:指定需要生成 ID 的列
KeyGenerotorClass:指定生成器类,默认是 DefaultKeyGenerator.java,里面使用了雪花算法。
注意:ID 要用 BIGINT。Mapper.xml insert 语句里面不能出现主键。否则会报错:Sharding value must implements Comparable
三、分布式事务
我们用到分布式事务的场景有两种,一种是跨应用(比如微服务场景),一种是单应用多个数据库(分库分表的场景),对于代码层的使用来说的一样的。
3.1、事务概述
https://shardingsphere.apache.org/document/current/cn/features/transaction/
XA 模型的不足:需要锁定资源
SEATA:支持 AT、XA、TCC、SAGA
SEATA 是一种全局事务的框架。
3.2、两阶段事务-XA
玩起来也特别容易首先添加依赖
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-transaction-xa-core</artifactId> <version>4.1.1</version> </dependency>
然后在业务层上加入下面注解就可以了
@ShardingTransactionType(TransactionType.XA) @Transactional(rollbackFor = Exception.class)
3.3 、柔性事务 Seata
https://seata.io/zh-cn/docs/overview/what-is-seata.html
https://github.com/seata/seata
https://github.com/seata/seata-workshop(官网推荐的搭建例子教程)
https://github.com/seata/seata-samples(官网推荐的搭建例子教程)
四、 Sharding-JDBC 工作流程
https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的。 核心由 SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并的流程组成。
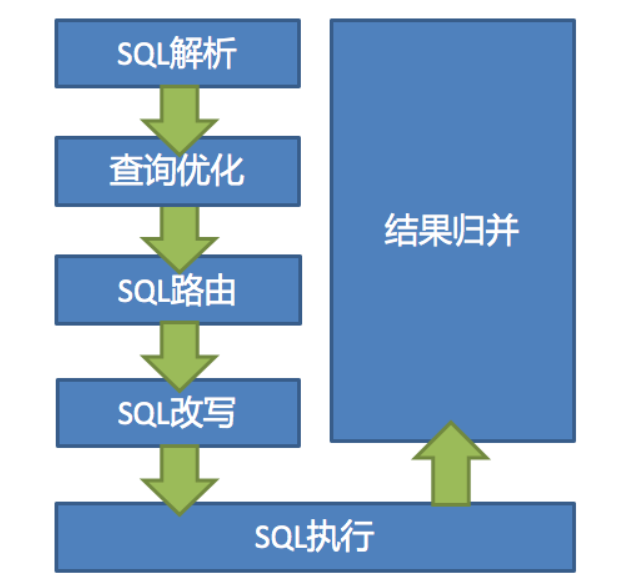
4.1、SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。目前常见的 SQL 解析器主要有 fdb,jsqlparser和 Druid。Sharding-JDBC1.4.x 之前的版本使用 Druid 作为 SQL 解析器。从 1.5.x 版本开始,Sharding-JDBC 采用完全自研的 SQL 解析引擎。
4.2、执行器优化
合并和优化分片条件,如 OR 等。
4.3、SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
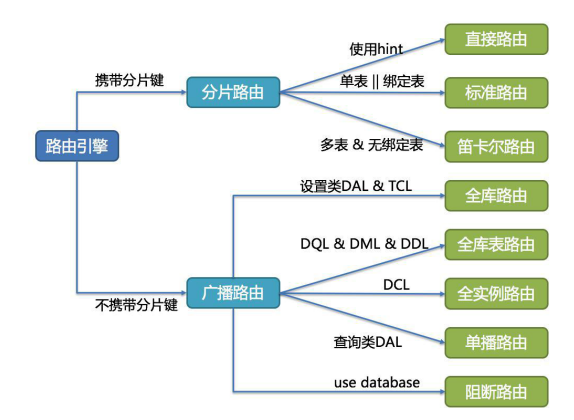
SQL 路由是根据分片规则配置以及解析上下文中的分片条件,将 SQL 定位至真正的数据源。它又分为直接路由、简单路由和笛卡尔积路由。
直接路由,使用 Hint 方式。
Binding 表是指使用同样的分片键和分片规则的一组表,也就是说任何情况下, Binding 表的分片结果应与主表一致。例如:order 表和 order_item 表,都根据 order_id 分片,结果应是 order_1 与 order_item_1 成对出现。这样的关联查询和单表查询复杂度和性能相当。如果分片条件不是等于,而是 BETWEEN 或 IN,则路由结果不一定落入单库(表),因此一条逻辑 SQL 最终可能拆分为多条 SQL 语句。
笛卡尔积查询最为复杂,因为无法根据 Binding 关系定位分片规则的一致性,所以非 Binding 表的关联查询需要拆解为笛卡尔积组合执行。查询性能较低,而且数据库连接数较高,需谨慎使用。
4.4、SQL 改写
例如:将逻辑表名称改成真实表名称,优化分页查询等。
4.5 、SQL 执行
因为可能链接到多个真实数据源, Sharding -JDBC 将采用多线程并发执行 SQL。
4.6、结果归并
例如数据的组装、分页、排序等等。
Sharding-JDBC中所有的代码:https://github.com/ljx958720/springSphere.git