一、开闭原则
1.1、定义
1.2、问题由来
凡事的产生都有缘由。我们来看看,开闭原则的产生缘由。在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。这就对我们的整个系统的影响特别大,这也充分展现出了系统的耦合性如果太高,会大大的增加后期的扩展,维护。为了解决这个问题,故人们总结出了开闭原则。解决开闭原则的根本其实还是在解耦合。所以,我们面向对象的开发,我们最根本的任务就是解耦合。
1.3、解决方法
当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
1.4、案例
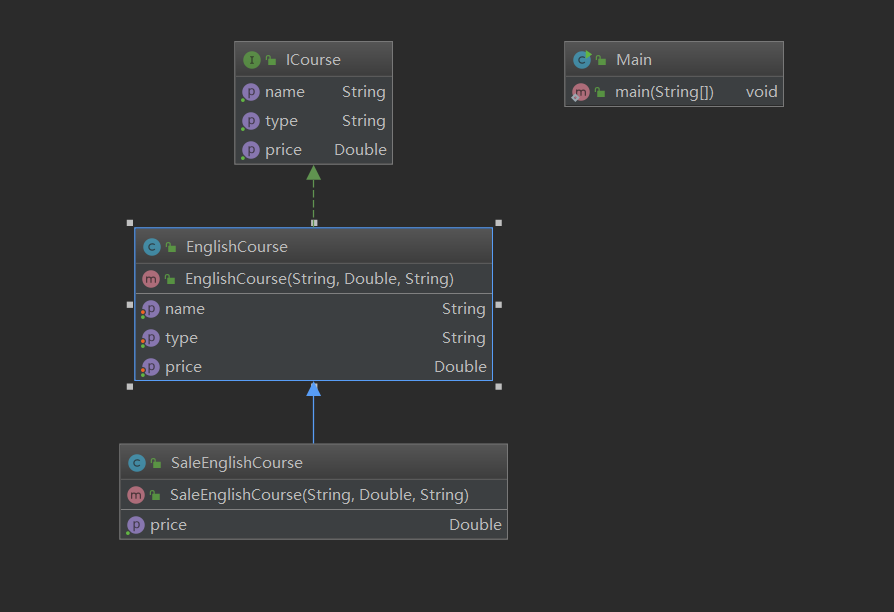
/** * 定义课程接口 */ public interface ICourse { String getName(); // 获取课程名称 Double getPrice(); // 获取课程价格 String getType(); // 获取课程类型 }
/** * 英语课程接口实现 */ public class EnglishCourse implements ICourse { private String name; private Double price; private String type; public EnglishCourse(String name, Double price, String type) { this.name = name; this.price = price; this.type = type; } @Override public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public Double getPrice() { return price; } public void setPrice(Double price) { this.price = price; } @Override public String getType() { return type; } public void setType(String type) { this.type = type; } }
// 测试 public class Main { public static void main(String[] args) { ICourse course = new EnglishCourse("小学英语", 199D, "必修"); System.out.println( "课程名字:"+course.getName() + " " + "课程价格:"+course.getPrice() + " " + "课程类型:"+course.getType() ); } }
项目上线,课程正常销售,但是产品需要做些活动来促进销售,比如:打折。那么问题来了:打折这一动作就是一个变化,而我们要做的就是拥抱变化,现在开始考虑如何解决这个问题,可以考虑下面三种方案
1.4.1、修改接口
在之前的课程接口中添加一个方法 getSalePrice() 专门用来获取打折后的价格;如果这样修改就会产生两个问题,所以此方案否定
-
- ICourse 接口不应该被经常修改,否则接口作为契约的作用就失去了
- 并不是所有的课程都需要打折,加入还有语文课,数学课等都实现了这一接口,但是只有英语课打折,与实际业务不符
- 这样一发动后,它的所有实现类都要改动,这样的代码扩展性不好
/** * 定义课程接口 */ public interface ICourse { String getName(); // 获取课程名称 Double getPrice(); // 获取课程价格 String getType(); // 获取课程类型 Double getSalePrice();// 新增:打折接口 }
1.4.2、修改实现类
在接口实现里直接修改 getPrice()方法,此方法会导致获取原价出问题;或添加获取打折的接口 getSalePrice(),这样就会导致获取价格的方法存在两个,所以这个方案也否定。
1.4.3、通过扩展实现变化
直接添加一个子类 SaleEnglishCourse ,重写 getPrice()方法,这个方案对源代码没有影响,符合开闭原则,所以是可执行的方案,代码如下,代码如下:
public class SaleEnglishCourse extends EnglishCourse { public SaleEnglishCourse(String name, Double price, String author) { super(name, price, author); } @Override public Double getPrice() { return super.getPrice() * 0.85; } }
public class Main { public static void main(String[] args) { ICourse course = new EnglishCourse("小学英语", 199D, "必修"); System.out.println( "课程名字:"+course.getName() + " " + "课程价格:"+course.getPrice() + " " + "课程类型:"+course.getType() ); ICourse saleEnglishCourse = new SaleEnglishCourse ("小学英语", 199D, "必修"); System.out.println( "课程名字:"+saleEnglishCourse.getName() + " " + "课程价格:"+saleEnglishCourse.getPrice() + " " + "课程类型:"+saleEnglishCourse.getType() ); } }
1.5、小结
开闭原则具有理想主义的色彩,说的很抽象,它是面向对象设计的终极目标。其他几条原则,则可以看做是开闭原则的实现。我们要用抽象构建框架,用实现扩展细节。
二、依赖倒置原则
2.1、定义
2.2、问题由来
类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
2.3、解决方法
将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。 在实际编程中,我们一般需要做到如下3点:
1). 低层模块尽量都要有抽象类或接口,或者两者都有。
2). 变量的声明类型尽量是抽象类或接口。
3). 使用继承时遵循里氏替换原则。
采用依赖倒置原则尤其给多人合作开发带来了极大的便利,参与协作开发的人越多、项目越庞大,采用依赖导致原则的意义就越重大。
2.4、案例
写一个关于司机开车的示例,假设我们现在有个司机,可以开车,然后有一辆奔驰,于是就可以让车跑起来。
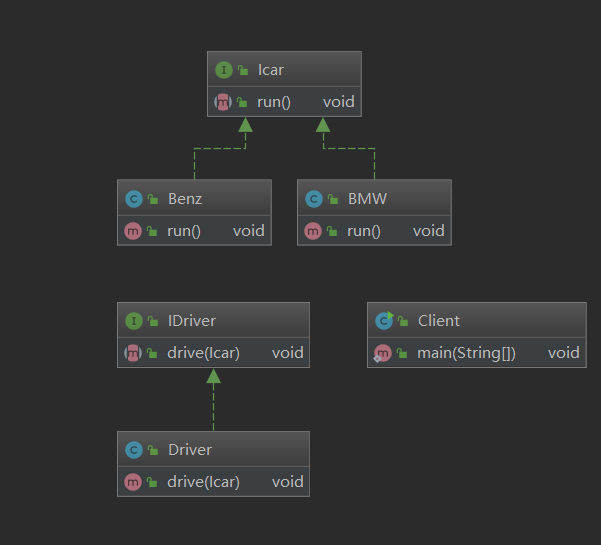
public class Driver { // 司机职责就是驾驶汽车 public void drive(Benz benz) { benz.run(); } } public class Benz { // 车的作用就是跑 public void run() { System.out.println("奔驰车跑起来了"); } } public class Client { public static void main(String[] args) { Driver zhangsan = new Driver(); Benz benz = new Benz(); // 张三开车 zhangsan.drive(benz); } }
以上代码就可以让张三把奔驰车开起来,可是这样子就有一个问题,如果现在有一辆宝马:
public class BMW { // 车的作用就是跑 public void run() { System.out.println("宝马车跑起来了"); } }
我们发现张三并不能让宝马车跑起来,因为Driver依赖Benz太紧,当多了BMW后无法扩展。因此针对接口编程,依赖于抽象而不依赖于具体。如下代码所示:
public interface IDriver { // 司机职责就是驾驶汽车 public void drive(Icar car); } public class Driver implements IDriver{ // 司机职责就是驾驶汽车 public void drive(Icar car) { car.run(); } } public interface Icar { // 车的作用就是跑 public void run(); } public class Benz implements Icar { // 车的作用就是跑 public void run() { System.out.println("奔驰车跑起来了"); } } public class BMW implements Icar { // 车的作用就是跑 public void run() { System.out.println("宝马车跑起来了"); } } public class Client { public static void main(String[] args) { IDriver zhangsan = new Driver(); Benz benz = new Benz(); zhangsan.drive(benz); BMW bmw = new BMW(); zhangsan.drive(bmw); } }
这样张三就直接开走了奔驰和宝马,要是接下来再来一辆奥迪,那么原有的所有代码都无需改动,只用添加一辆奥迪的车即可。
2.5、小结
依赖倒置原则就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒置。
三、单一职责原则
3.1、定义
3.2、问题由来
类T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。
3.3、解决方法
分别建立两个类T1、T2,使T1完成职责P1功能,T2完成职责P2功能。这样,当修改类T1时,不会使职责P2发生故障风险;同理,当修改T2时,也不会使职责P1发生故障风险。
3.4、案例
最近一直陪媳妇去医院检查,下面就医院举例,医院体检会分为不同类别的科室,例如一般检查室(身高,体重,视力等),抽血室,内科,外科,五官科,妇科,眼科等等,这些科室单一的检查人体的某一部位或者某几个部位,那么,为什么不将检查的所有内容分到一个科室,一次性检查完,其实这样会造成大家排队时间长,不能交替的进行体检,当 检查者一个项目没有完成的时候,还不能较好的进行其他项目的体检。并且每个体检科室一般不具有紧密的联系,把每个人体所需检查的部位划分为若干单元,每个单元的医师做自己份内的事情,还有助于体检高效的进行。
public interface Iexamine{ //检查身高 void setHeight(double height); double getHeight(); //检查体重 void setWeight(double weight); double getWeight(); //心率是否正常 boolean testHeartRate(int number); }
以上的例子身高和体重本应该在一般体检科检查,而心率检查一般在内科,但是这就会给人一种不知道这个接口到底是做什么的感觉,职责不清晰,到底是一般检查科还是内科,后期维护的时候也会造成各种各样的问题。因此,解决办法是:单一职责原则,将这个接口分解成两个职责不同的接口即可。
public interface IGerExamine { //检查身高 void setHeight(double height); double getHeight(); //检查体重 void setWeight(double weight); double getWeight(); }
public interface IHeartRateExamine { //心率是否正常 boolean testHeartRate(int number); }
3.5、小结
这样就实现了接口的单一职责。那么实现接口的时候,就需要有两个不同的类。
四、接口隔离原则
4.1、定义
4.2、问题由来
4.3、解决方法
4.4、案例
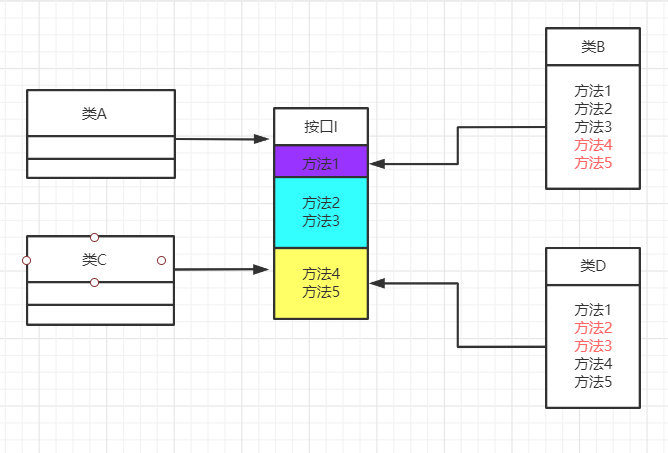
这个图的意思是:类A依赖接口I中的方法1、方法2、方法3,类B是对类A依赖的实现。类C依赖接口I中的方法1、方法4、方法5,类D是对类C依赖的实现。对于类B和类D来说,虽然他们都存在着用不到的方法(也就是图中红色字体标记的方法),但由于实现了接口I,所以也必须要实现这些用不到的方法
修改后:

如果接口过于臃肿,只要接口中出现的方法,不管对依赖于它的类有没有用处,实现类中都必须去实现这些方法,这显然不是好的设计。如果将这个设计修改为符合接口隔离原则,就必须对接口I进行拆分。在这里我们将原有的接口I拆分为三个接口
4.5、小结
我们在代码编写过程中,运用接口隔离原则,一定要适度,接口设计的过大或过小都不好。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。设计接口的时候,只有多花些时间去思考和筹划,就能准确地实践这一原则。
五、迪米特法则
5.1、定义
5.2、问题由来
类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。最早是在1987年由美国Northeastern University的Ian Holland提出。通俗的来讲,就是一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类来说,无论逻辑多么复杂,都尽量地的将逻辑封装在类的内部,对外除了提供的public方法,不对外泄漏任何信息。迪米特法则还有一个更简单的定义:只与直接的朋友通信。
5.3、解决方法
尽量降低类与类之间的耦合。 自从我们接触编程开始,就知道了软件编程的总的原则:低耦合,高内聚。无论是面向过程编程还是面向对象编程,只有使各个模块之间的耦合尽量的低,才能提高代码的复用率。
迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。但是凡事都有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系。故过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
5.4、案例
如一个明星与经纪人的关系实例。明星由于全身心投入艺术,所以许多日常事务由经纪人负责处理,如与粉丝的见面会,与媒体公司的业务洽淡等。这里的经纪人是明星的朋友,而粉丝和媒体公司是陌生人,所以适合使用迪米特法则,其类图如图所示。
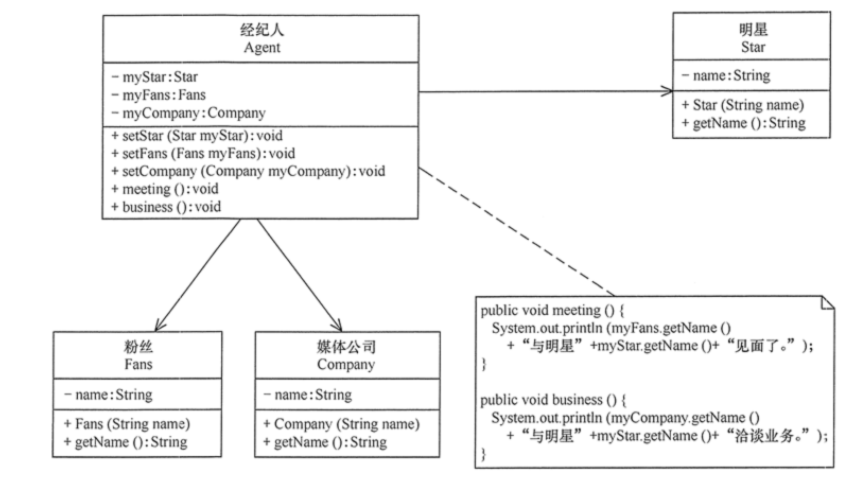
复制代码 public class LoDtest { public static void main(String[] args) { Agent agent=new Agent(); agent.setStar(new Star("林心如")); agent.setFans(new Fans("粉丝")); agent.setCompany(new Company("中国传媒有限公司")); agent.meeting(); agent.business(); } } //经纪人 class Agent { private Star myStar; private Fans myFans; private Company myCompany; public void setStar(Star myStar) { this.myStar=myStar; } public void setFans(Fans myFans) { this.myFans=myFans; } public void setCompany(Company myCompany) { this.myCompany=myCompany; } public void meeting() { System.out.println(myFans.getName()+"与明星"+myStar.getName()+"见面了。"); } public void business() { System.out.println(myCompany.getName()+"与明星"+myStar.getName()+"洽淡业务。"); } } //明星 class Star { private String name; Star(String name) { this.name=name; } public String getName() { return name; } } //粉丝 class Fans { private String name; Fans(String name) { this.name=name; } public String getName() { return name; } } //媒体公司 class Company { private String name; Company(String name) { this.name=name; } public String getName() { return name; } }
5.5、总结
核心是只与直接的朋友通信
六、里氏替换原则
6.1、定义
6.2、问题由来
有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
6.3、解决方法
类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法
6.4、案例
6.4.1、子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法
子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法,父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。举例:
public class C { public int func(int a, int b){ return a+b; } } public class C1 extends C{ @Override public int func(int a, int b) { return a-b; } } public class Client{ public static void main(String[] args) { C c = new C1(); System.out.println("2+1=" + c.func(2, 1)); } }
上面的运行结果明显是错误的。类C1继承C,后来需要增加新功能,类C1并没有新写一个方法,而是直接重写了父类C的func方法,违背里氏替换原则,引用父类的地方并不能透明的使用子类的对象,导致运行结果出错。
6.4.2、子类可以有自己的个性
在继承父类属性和方法的同时,每个子类也都可以有自己的个性,在父类的基础上扩展自己的功能。前面其实已经提到,当功能扩展时,子类尽量不要重写父类的方法,而是另写一个方法,所以对上面的代码加以更改,使其符合里氏替换原则,代码如下:
public class C { public int func(int a, int b){ return a+b; } } public class C1 extends C{ public int func2(int a, int b) { return a-b; } } public class Client{ public static void main(String[] args) { C1 c = new C1(); System.out.println("2-1=" + c.func2(2, 1)); } }
6.4.3、覆盖或实现父类的方法时输入参数可以被放大
当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松,通过代码来讲解一下:
public class ParentClazz { public void say(CharSequence str) { System.out.println("parent execute say " + str); } public static void main(String[] args) { ArrayList list = new ArrayList(); ParentClazz parent = new ParentClazz(); parent.say("hello1"); ChildClazz child = new ChildClazz(); child.say("hello"); } } class ChildClazz extends ParentClazz { public void say(String str) { System.out.println("child execute say " + str); } }
以上代码中我们并没有重写父类的方法,只是重载了同名方法,具体的区别是:子类的参数 String 实现了父类的参数 CharSequence。此时执行了子类方法,在实际开发中,通常这不是我们希望的,父类一般是抽象类,子类才是具体的实现类,如果在方法调用时传递一个实现的子类可能就会产生非预期的结果,引起逻辑错误,根据里氏替换的子类的输入参数要宽于或者等于父类的输入参数,我们可以修改父类参数为String,子类采用更宽松的 CharSequence,如果你想让子类的方法运行,就必须覆写父类的方法。代码如下:
public class ParentClazz { public void say(String str) { System.out.println("parent execute say " + str); } public static void main(String[] args) { ArrayList list = new ArrayList(); ParentClazz parent = new ParentClazz(); parent.say("hello1"); ChildClazz child = new ChildClazz(); child.say("hello"); } } class ChildClazz extends ParentClazz { public void say(Object str) { System.out.println("child execute say " + str); } }
6.4.4、覆写或实现父类的方法时输出结果可以被缩小
当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。代码实现案例如下:
public abstract class Father { public abstract Map hello(); public static void main(String[] args) { Father father = new Son(); father.hello(); } } class Son extends Father { @Override public Map hello() { HashMap map = new HashMap(); System.out.println("son execute"); return map; } }
6.5、总结
保证了父类的复用性,同时也能够降低系统出错误的故障,防止误操作,同时也不会破坏继承的机制,这样继承才显得更有意义。增强程序的健壮性,版本升级是也可以保持非常好的兼容性.即使增加子类,原有的子类还可以继续运行.在实际项目中,每个子类对应不同的业务含义,使用父类作为参数,传递不同的子类完成不同的业务逻辑,完美!
继承作为面向对象三大特性之一,在给程序设计带来巨大便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低,增加了对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能会产生故障。里氏替换原则的目的就是增强程序健壮性,版本升级时也可以保持非常好的兼容性。有人会说我们在日常工作中,会发现在自己编程中常常会违反里氏替换原则,程序照样跑的好好的。所以大家都会产生这样的疑问,假如我非要不遵循里氏替换原则会有什么后果?后果就是:你写的代码出问题的几率将会大大增加。
七、合成复用原则
7.1、定义
7.2、为什么要尽量使用合成/聚合而不使用类继承?
1. 对象的继承关系在编译时就定义好了,所以无法在运行时改变从父类继承的子类的实现
2. 子类的实现和它的父类有非常紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化
3. 当你复用子类的时候,如果继承下来的实现不适合解决新的问题,则父类必须重写或者被其它更适合的类所替换,这种依赖关系限制了灵活性,并最终限制了复用性。
7.3、案例
以汽车分类管理程序为例来介绍合成复用原则的应用。
分析:汽车按“动力源”划分可分为汽油汽车、电动汽车等;按“颜色”划分可分为白色汽车、黑色汽车和红色汽车等。如果同时考虑这两种分类,其组合就很多。如图所示是用继淨:关系实现的汽车分类的类图。

从图中可以看出用继承关系实现会产生很多子类,而且增加新的“动力源”或者增加新的“颜色”都要修改源代码,这违背了开闭原则,显然不可取。但如果改用组合关系实现就能很好地解决以上问题,其类图如下图所示。

7.4、总结
这些原则在设计模式中体现的淋淋尽致,设计模式就是实现了这些原则,从而达到了代码复用、增强了系统的扩展性。所以设计模式被很多人奉为经典。我们可以通过好好的研究设计模式,来慢慢的体会这些设计原则。
八、七大原则总结
| 设计原则 | 归纳 | 目的 |
| 开闭原则 | 对扩展开放,对修改关闭 | 降低维护带来的风险 |
| 依赖倒置原则 | 高层不应该依赖于低层 | 更利于代码结构的升级扩展 |
| 单一职责原则 | 一个类只做一件事 | 便于理解,提高代码的可读性 |
| 接口隔离原则 | 一个接口只做一件事 | 功能解耦,高聚合,低耦合 |
| 迪米特法则 | 不和陌生人做朋友 | 只和朋友交流,不和陌生人做朋友,减少代码臃肿 |
| 里氏替换原则 | 子类重写 方法功能发生改变,不应该影响父类方法 | 防止继承泛滥 |
| 合成复用原则 | 尽量使用组合实现代码复用,而不使用继承 | 降低代码耦合 |