一、定义
面向对象技术可以很好地解决一些灵活性或可扩展性问题,但在很多情况下需要在系统中增加类和对象的个数。当对象数量太多时,将导致运行代价过高,带来性能下降等问题。享元模式正是为解决这一类问题而诞生的。享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能。这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式。例如线程池,线程池的创建可以避免不停的创建和销毁多个对象,消耗性能。
在享元模式中可以共享的相同内容称为 内部状态(Intrinsic State),而那些需要外部环境来设置的不能共享的内容称为 外部状态(Extrinsic State),其中外部状态和内部状态是相互独立的,外部状态的变化不会引起内部状态的变化。由于区分了内部状态和外部状态,因此可以通过设置不同的外部状态使得相同的对象可以具有一些不同的特征,而相同的内部状态是可以共享的。也就是说,享元模式的本质是分离与共享 : 分离变与不变,并且共享不变。把一个对象的状态分成内部状态和外部状态,内部状态即是不变的,外部状态是变化的;然后通过共享不变的部分,达到减少对象数量并节约内存的目的。
在享元模式中通常会出现工厂模式,需要创建一个享元工厂来负责维护一个享元池(Flyweight Pool)(用于存储具有相同内部状态的享元对象)。在享元模式中,共享的是享元对象的内部状态,外部状态需要通过环境来设置。在实际使用中,能够共享的内部状态是有限的,因此享元对象一般都设计为较小的对象,它所包含的内部状态较少,这种对象也称为 细粒度对象。
享元模式的目的就是使用共享技术来实现大量细粒度对象的复用。说了这么多归其本质就一句话缓存共享对象,降低内存消耗。
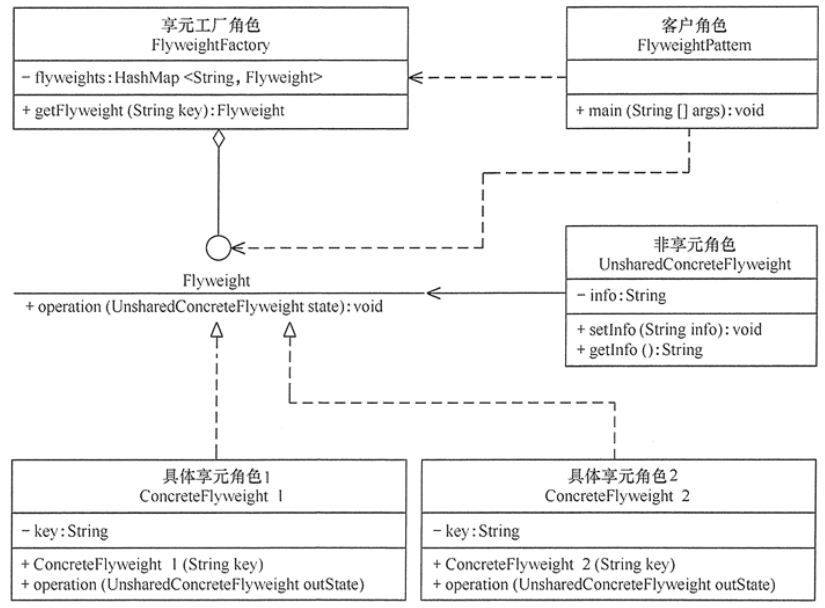
模式所涉及的角色
Flyweight: 享元接口,通过这个接口传入外部状态并作用于外部状态;
ConcreteFlyweight: 具体的享元实现对象,必须是可共享的,需要封装享元对象的内部状态;
UnsharedConcreteFlyweight: 非共享的享元实现对象,并不是所有的享元对象都可以共享,非共享的享元对象通常是享元对象的组合对象;
FlyweightFactory: 享元工厂,主要用来创建并管理共享的享元对象,并对外提供访问共享享元的接口;
二、享元模式的应用场景
业务场景:现在某公司要求大家做一个年度总结报告,如果这些报告已经生成过了,就不用在生成了。
//非享元角色 class UnsharedConcreteFlyweight { private String info; UnsharedConcreteFlyweight(String info) { this.info = info; } public String getInfo() { return info; } public void setInfo(String info) { this.info = info; } }
//抽象享元角色 interface Flyweight { public void operation(UnsharedConcreteFlyweight state); }
//具体享元角色 class ConcreteFlyweight implements Flyweight { private String key; ConcreteFlyweight(String key) { this.key = key; System.out.println("具体享元" + key + "被创建!"); } public void operation(UnsharedConcreteFlyweight outState) { System.out.print("具体享元" + key + "被经理调用,"); System.out.println("非享元信息是:" + outState.getInfo()); } }
//享元工厂角色 class FlyweightFactory { private HashMap<String, Flyweight> flyweights = new HashMap<String, Flyweight>(); public Flyweight getFlyweight(String key) { Flyweight flyweight = (Flyweight) flyweights.get(key); if (flyweight != null) { System.out.println("具体享元" + key + "已经存在,不用重复创建!"); } else { flyweight = new ConcreteFlyweight(key); flyweights.put(key, flyweight); } return flyweight; } }
public class FlyweightPattern { public static void main(String[] args) { FlyweightFactory factory = new FlyweightFactory(); Flyweight f01 = factory.getFlyweight("报告1"); Flyweight f02 = factory.getFlyweight("报告1"); Flyweight f03 = factory.getFlyweight("报告1"); Flyweight f11 = factory.getFlyweight("报告2"); Flyweight f12 = factory.getFlyweight("报告2"); f01.operation(new UnsharedConcreteFlyweight("第1次调用报告1。")); f02.operation(new UnsharedConcreteFlyweight("第2次调用报告1。")); f03.operation(new UnsharedConcreteFlyweight("第3次调用报告1。")); f11.operation(new UnsharedConcreteFlyweight("第1次调用报告2。")); f12.operation(new UnsharedConcreteFlyweight("第2次调用报告2。")); } }
再说一个比较贴切的例子,一样是在上一篇幅中说过的数据库连接池,在连接时使用Connection对象时主要性能消耗在建立连接和关闭连接的时候,为了提高Connection在调用时的性能,那么最好的做法就是将Connection对象在调用前创建好缓存起来,用的时候从缓存中取值,用完后再放回去,达到资源重复利用的目的
public class ConnectionPool { private Vector<Connection> pool; private String url = "jdbc:mysql://localhost:3306/ds1"; private String username = "root"; private String password = "root"; private String driverClassName = "com.mysql.jdbc.Driver"; private int poolSize = 100; public ConnectionPool() { pool = new Vector<Connection>(poolSize); try{ Class.forName(driverClassName); for (int i = 0; i < poolSize; i++) { Connection conn = DriverManager.getConnection(url,username,password); pool.add(conn); } }catch (Exception e){ e.printStackTrace(); } } public synchronized Connection getConnection(){ System.out.println("数量:"+pool.size()); if(pool.size() > 0){ Connection conn = pool.get(0); pool.remove(conn); return conn; } return null; } public synchronized void release(Connection conn){ pool.add(conn); } }
public class Test { public static void main(String[] args) { ConnectionPool connection=new ConnectionPool(); Connection connection1=connection.getConnection(); System.out.println(connection1); } }
三、享元模式在源码中的应用
1、String中的享元模式
Java 中 String 类由 final 修饰,即不可改变的。在 JVM 中,字符串一般被保存在字符串常量池中,且 Java 会确保一个字符串在常量池中只有一个“复制”。字符串常量池在 JDK6 之前位于永久代,而在 JDK7 中,JVM 将其放置于堆中。这里我们不谈堆栈,只简单引入了常量池这个简单的概念。常量池(Constant Pool)指的是在编译期被确定,并被保存在已编译的 .class 文件中的一些数据。它包括了关于类、方法、接口、字符串等常量。字符串常量池指对应常量池中存储 String 常量的区域。
public class Test { public static void main(String[] args) { String s1 = "hello"; String s2 = "hello"; String s3 = "he" + "1lo"; String s4 = "hel" + new String("lo"); String s5 = new String("hello"); String s6 = s5.intern(); String s7 = "h"; String s8 = "ello"; String s9 = s7 + s8; System.out.println(s1 == s2); //true System.out.println(s1 == s3); //true System.out.println(s1 == s4); //false System.out.println(s1 == s9); //false System.out.println(s4 == s5); //false System.out.println(s1 == s6); //true } }
String类的final修饰的,以字面量的形式创建String变量时,JVM 会在编译期间就把该字面量的值“hello”放到字符串常量池中,这样 Java 启动的时候就已经加载到内存中了。而用 new String() 创建的字符串不是常量,不能在编译期就确定,所以 new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
字符串常量池的特点就是有且只有一个相同的字面量。如果有其他相同的字面量,则 JVM 返回这个字面量的引用;如果没有相同的字面量,则在字符串常量池中创建这个字面量并返回它的引用。
由于 s2 指向的字面量“hello”在常量池中已经存在(s1 先于 s2),所以 JVM 返回的是这个字面量绑定的引用,即 s1==s2。
s3 中字面量的拼接其实就是“hello”,JVM 在编译期间就已经对它进行了优化,所以 s1 和 s3 也是相等的。
s4 中的 new String("lo")生成了两个对象:hel 和 new String("lo")。hel 存在于字符串常量池中,new String("lo")存在于堆中。String s4 = "hel" + new String("lo")实质上是两个对象的相加,编译器不会进行优化,相加的结果存在于堆中,而 s1 存在于字符串常量池中,当然不相等。同样,s1==s9 的原理也一样。
s4 和 s5 的结果都在堆中,不用说,肯定不相等。
存在于 .class 文件中的常量池在运行期被 JVM 装载,并且可以扩充。而 String 的 intern() 方法就是扩充常量池的一个方法。intern() 方法能使一个位于堆中的字符串在运行期间动态地加入字符串常量池(字符串常量池的内容是在程序启动的时候就已经加载好了的)。
调用 intern() 方法时,Java 会查找字符串常量池中是否有该对象对应的字面量,如果有,则返回该字面量在字符串常量池中的引用;如果没有,则复制一份该字面量到字符串常量池并返回它的引用,因此 s1==s6 输出 true。
2、interger享元模式
对象 Integer 也用到了享元模式,其中暗藏玄机,来看代码。
public static void main(String[] args) { Integer a = Integer.valueOf(105); Integer b = 105; Integer c = Integer.valueOf(1000); Integer d = 1000; System.out.println("a==b:" + (a == b)); System.out.println("c==d:" + (c == d)); }
在运行完程序后,我们才发现有些不对,得到了一个意想不到的运行结果,如下图所示。
a==b:true
c==d:false
之所以得到这样的结果,是因为 Integer 用到了享元模式,来看 Integer 的源码。
public final class Integer extends Number implements Comparable { ... public static Integer valueOf(int i) { assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } ... }
由上可知,Integer 源码中的 valueOf() 方法做了一个条件判断。在通过 valueof 方法创建 Integer 对象的时候,如果目标值在 -128~127 之间,则直接从缓存中取值,返回 IntegerCache.cache 中已经存在的对象的引用,否则新建 Integer 对象。
那么 JDK 为何要这么做呢?因为 -128~127 之间的数据在 int 范围内是使用最频繁的,为了减少频繁创建对象带来的内存消耗,这里就用到了享元模式,以提高性能。
上述例子中 a 和 b 的值为 100,因此会直接从 cache 中取已经存在的对象,所以 a 和 b 指向的是同一个对象,而 c 和 d 是分别指向不同的对象。
同理,Integer、Short、Byte、Character、Long 这几个类的 valueOf 方法的实现是类似的,而 Double、Float 的 valueOf 方法的实现是类似的,因为浮点数在某个范围内的个数不是有限的。
拓展
和 Integer 类似,Long 源码也用到了享元模式,将 -128~127 的值缓存起来,源码如下:
public final class Long extends Number implements Comparable { public static Long valueOf(long l) { final int offset = 128; if (l >= -128 && l <= 127) { // will cache return LongCache.cache[(int)l + offset]; } return new Long(l); } private static class LongCache { private LongCache(){} static final Long cache[] = new Long[-(-128) + 127 + 1]; static { for(int i = 0; i < cache.length; i++) cache[i] = new Long(i - 128); } } ... }
同理,Long 中也有缓存,但是不能指定缓存最大值。
3、享元模式在Apache Pool源码中的应用
Commons Pool2本质上是”对象池”,即通过一定的规则来维护对象集合的容器;commos-pool2在很多场景中,用来实现”连接池”/”任务worker池”等,大家常用的Jedis pool数据库连接池,也是基于commons-pool2实现.commons-pool2实现思想非常简单,它主要的作用就是将"对象集合"池化,任何通过pool进行对象存取的操作,都会严格按照"pool配置"(比如池的大小)实时的"建对象"、"阻塞控制"、"销毁对象"等.它在一定程度上,实现了对象集合的管理以及对象的分发.
对象池化的基本思路是:将用过的对象保存起来,等下一次需要这种对象的时候,再拿出来重复使用,从而在一定程度上减少频繁创建对象所造成的开销。用于充当保存对象的“容器”的对象,被称为“对象池”(Object Pool,或简称Pool)
Apache Commons Pool实现了对象池的功能。定义了对象的生成、销毁、激活、钝化等操作及其状态转换,并提供几个默认的对象池实现。先提一下其中有几个重要的对象:
- PooledObject(池对象):用于封装对象(如:线程、数据库连接、TCP连接),将其包裹成可被池管理的对象
- PooledObjectFactory(池对象工厂):定义了操作PooleObject实例生命周期的一些方法,PooledObjectFactory必须实现线程安全
- Object Pool(对象池):ObjectPool负责管理PooledObject,如:借出对象,返回对象,核验对象,有多少激活对象,有多少空闲对象
四、总结
优点:
1、减少对象的创建,降低内存中对象的数量,降低系统的内存,提高效率。
2、减少内存之外的其他资源占用
缺点:
1、关注内外部状态,关注线程安全问题
2、系统复杂度提高
补充:享元模式和代理模式有一点区别,代理模式出发点是功能的加强,而享元模式出发点是资源的共享;享元模式和工厂模式是配合使用的,享元模式中的享元工厂一般会设置成单例来进行使用,所以享元模式一般和单例模式是配合使用