Multiple Features
之前学的是“单变量线性回归”,明显一个问题不可能只有一个特征,现在增加特征数量变成“多变量线性回归”。
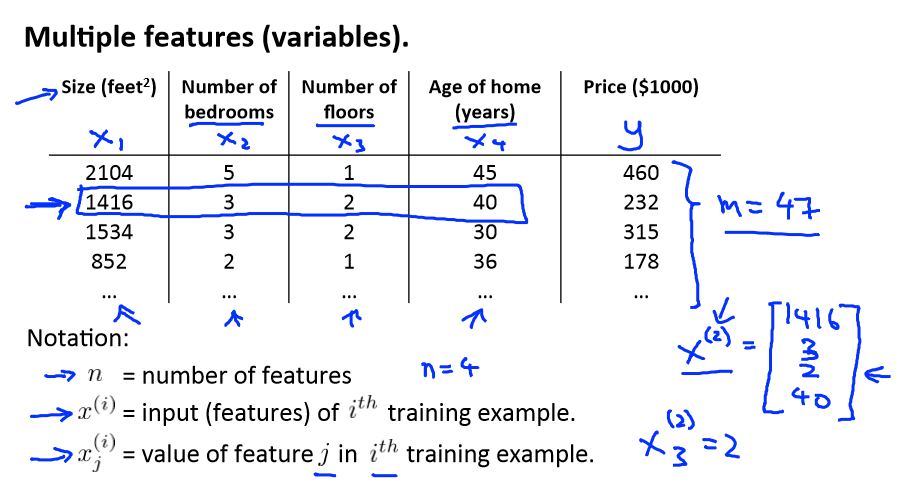
下面对一些符号进行定义:
n:特征的数量
m:训练数据的数量
x(i):训练集中的第i的数据
x(i)j:第i个数据的第j个特征
y(i):第i个数据的标签(输出结果)
y^(i):第i个数据的预测结果
h(x):预测模型
那和假设函数hθ(x)=θ0+θ1x变成了hθ(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4....θnxn
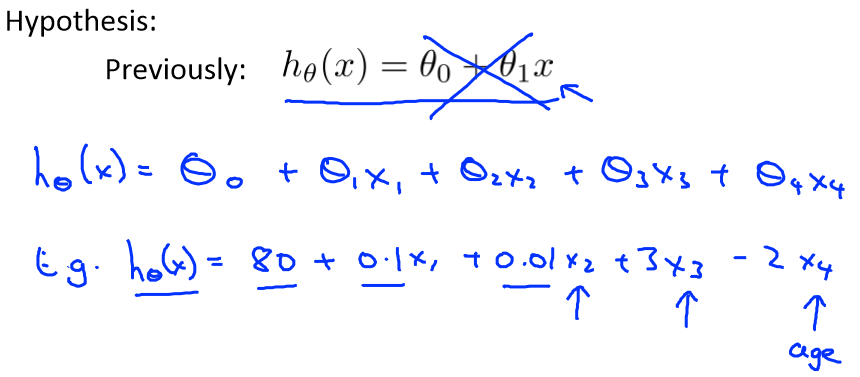
令θ=(θ0;θ1;θ2;θ3;θ4;θ5;...θn), X=(x0;x1;x2;x3;x4...xn),那么hθ(x)=θTX
代价函数也和之前的类似
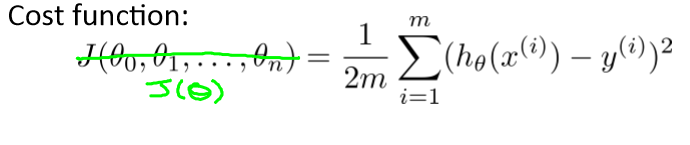
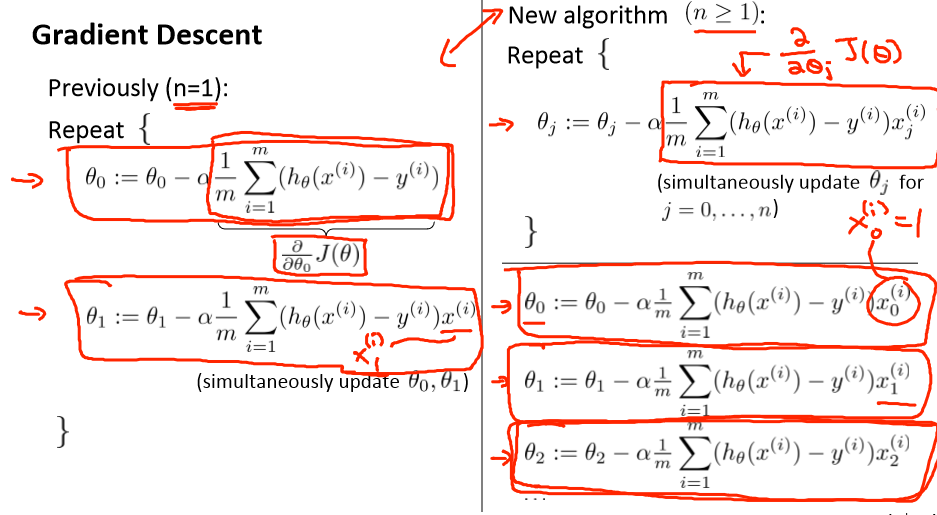
梯度下降也类似
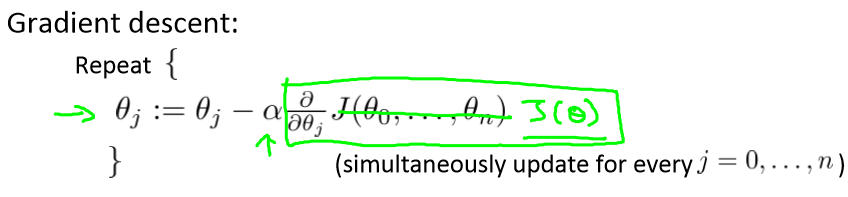
由于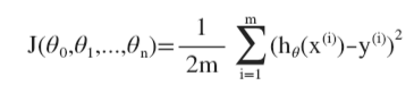
所以J(θ)对 θj 的导数是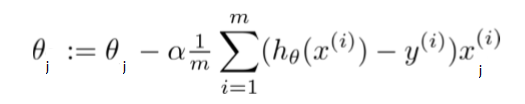
Feature Scaling(特征缩放)
在面对多维特征问题的时候,我们要确定这些特征具有相似的尺度,这样能帮助梯度更快地收敛。
以两个特征为例,一个尺度在0-2000,一个尺度在0-5,明显相差很大
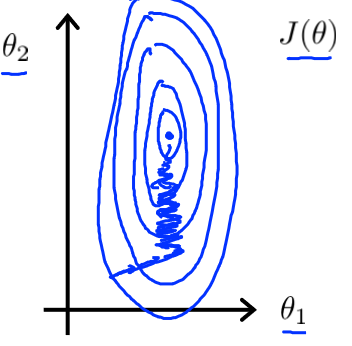
当用梯度下降法时,所需要跌打的数量明显很大,那么当两个特征都缩放到0-1时就很快了,跌打的

普遍使用这种
Learning rate(学习率)

梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。

也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如 0.001)进行比较,但通常看上面这样的图表更好
梯度下降算法每次迭代受到α的影响
如果α过小,则达到收敛所需的跌打次数将很大;
如果α过大,每次迭代可能不会减小代价函数的值,反而会远离局部最小值导致无法收敛。
通常可以考虑的下面这些学习率
α = 0.01,0.03,0.1,0.3,1,3,10

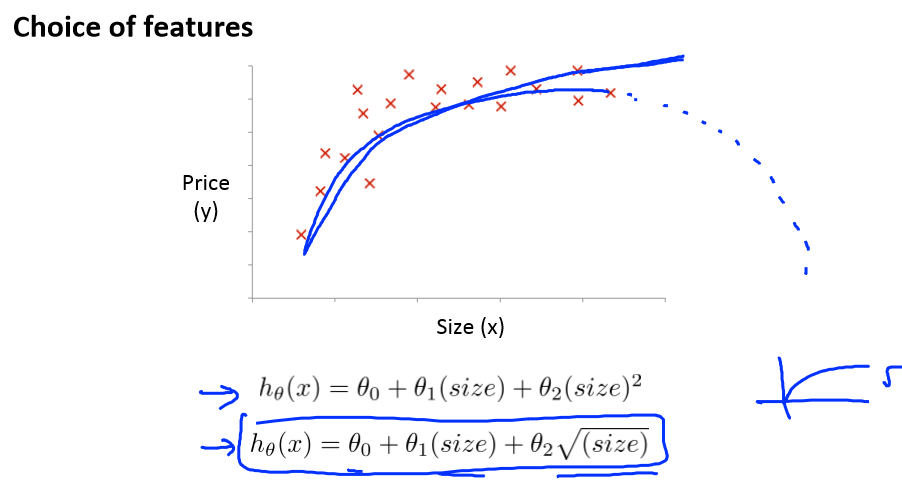
Features and polynomial regression(特征和多项式回归 )
线性回归并不适用所有数据,有时候我们需要曲线来适应我们的数据,比如二次方模型或二次方模型
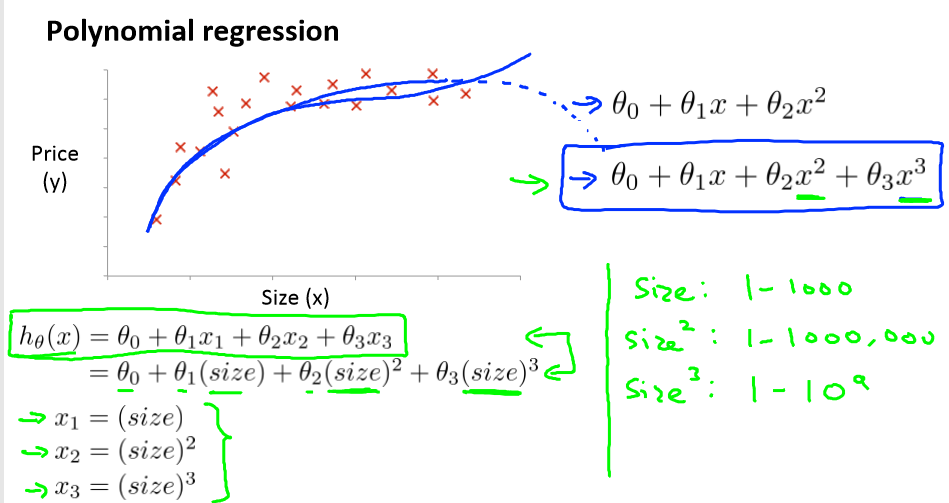
我们可以令x2 = x22 x3 = x33从而将模型转化为线性回归模型
即hθ(x) = θ0+θ1(size)+θ2(size)2或者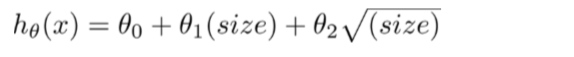
Normal Equation(正规方程)
对于某些线性回归问题,正规方程方法是更好的解决方案,如:

正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:
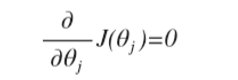
对于多项式也类似:
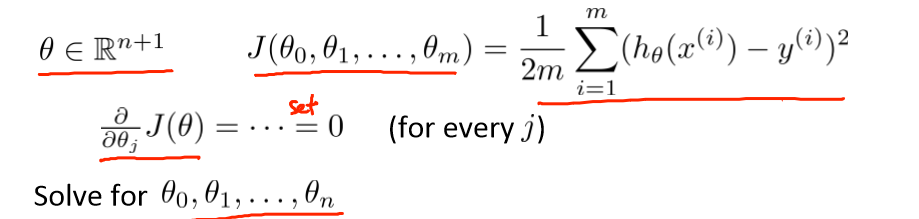
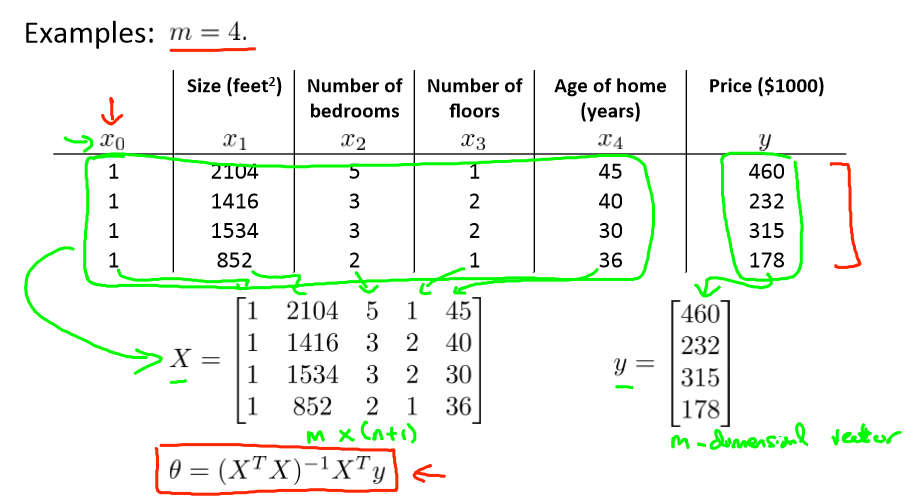
当m = 4时
梯度下降与正规方程的比较:
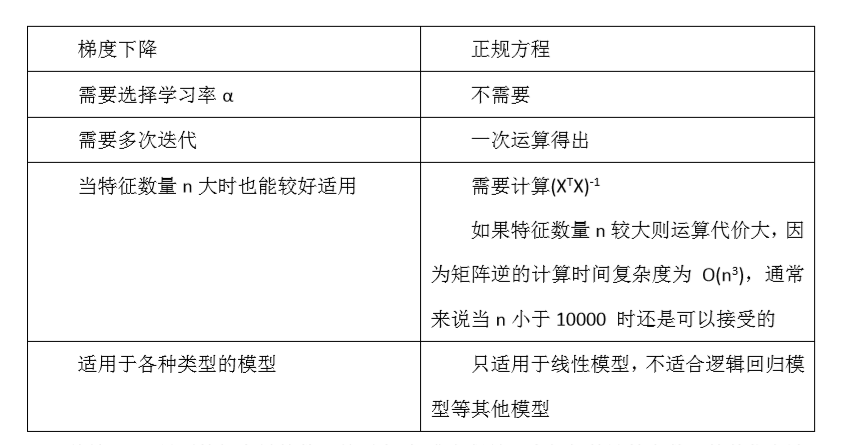
只要特征变量的数目并不大,标准方程是一个很好的计算参数θ的代替方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法,我们会看到, 实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。