本文属于系列文章【数据结构和算法:简单方法】
- 【数据结构之顺序表】用图和代码让你搞懂顺序结构线性表
- 【数据结构之链表】看完这篇文章我终于搞懂链表了
- 【数据结构之栈】用详细图文把「栈」搞明白(原理篇)
- 【数据结构之队列】详细图解!在学习队列?看这一篇就够了!
- 【数据结构之链表】详细图文教你花样玩链表
- 【数据结构之二叉树】一文看懂二叉树的概念和原理
- 【数据结构之二叉树】二叉树的创建及遍历实现
- 【数据结构之线索二叉树】线索二叉树的原理及创建
- 【数据结构之二叉堆】二叉堆的原理及操作
1. 何为查找?
我们平常做很多事情,都会涉及到大量的增删改查操作。比如一个用户管理系统,会涉及用户注册(增)、用户注销(删)、修改用户信息(改)、查找用户(查),其中“删”和“改”要依赖“查”操作。
下面重点来介绍一下查找这个重要的操作。
现给你一个点名册,让你查找一个学生。我们的做法是:根据这个学生的姓名或者学号,在点名册中一个个的比对,直到找到一个学号或姓名符合条件的学生为止,否则就可以说点名册中没有该学生。
| 学号 | 姓名 | 专业 |
|---|---|---|
| 101 | 张三 | 键盘清洁与维修 |
| 102 | 李四 | 母猪产后护理与保养 |
| 103 | 李四 | 计算机开关机专业操作员 |
点名册是一个集合,也可称之为查找表,其中有大量同一类型的元素,也可称之为记录——学生。学生中可能有重名的,但不会有重学号的,也即,一个学号唯一对应一个学生,一个姓名可能对应多个学生。如果我们根据学号找,只要点名册中有,那么就可以找到唯一一个符合条件的学生。如果我们根据姓名找,那么我们就可能找到多个符合条件的学生。
像学号和姓名这种可以标识一个学生的值,我们称之为关键字,学号这种唯一标识一个元素的值为主关键字,姓名这种可能标识若干元素的值为次关键字。当集合中的元素只有一个数据项时,其关键字即为该数据元素的值。
比如数组[1, 2, 3, 4, 5, 6, 7, 8, 9],其元素只有一个数据项,关键字即元素值本身;而点名册中的元素——学生,却有三个数据项——学号、姓名、专业,其中学号、姓名为关键字。
如果你学过数据库,那么以上概念很容易理解。
所谓查找,通俗点说就是在一大群元素(集合 / 查找表)中,依照某个查找依据,找一个特定的、符合要求的元素(记录)。
-
如果找到了,即查找成功,返回元素的信息;
-
如果找遍所有元素还没找到,说明这群元素中没有符合要求的元素,即查找失败,返回一个可以明显标记失败的值,比如“空记录”或“空指针”。
所谓查找依据,就是给定一个目标值,比较该目标值和关键字是否相等。这就要求目标值和关键字的类型要相同。
2. 顺序查找(Sequential Search)
顺序查找是我们最容易想到的查找方式,上面的点名册例子中,查找一个学生就是用的就是顺序查找。
顺序查找思想:
从集合中的第一个元素开始至最后一个元素,逐个比较其关键字和目标值。
- 若某个关键字和目标值相等,则查找成功,返回所查元素的信息;
- 若没有一个关键字和目标值相等,则查找失败,返回失败标识值。
比如,给定一个数组[11, 8, 4, 6, 9, 1, 16, 22, 14, 10],给定目标值 key,若找到,则返回其数组下标;否则,返回 -1:

只需从下标 0 开始遍历整个数组进行比较即可:
/**
* @description: 从头到尾遍历整个数组,查找目标值 key,返回其下标 index
* @param {int} *array 数组 为了说明问题简单,这里的数组元素不重复
* @param {int} length 数组长度
* @param {int} key 目标值
* @return {int} 如果找到,返回目标值下标;否则返回 -1
*/
int sequential_search(int *array, int length, int key)
{
for (int index = 0; index < length; index++) {
if (array[index] == key) {
return index;
}
}
return -1;
}
以上代码存在可优化的地方,因为每次比较之前要判断数组是否越界:index < length,增加哨兵则可以避免这一步比较。
所谓哨兵,是一种形象的说法,将其放在数组头或尾,用来标记结束,当遍历到“哨兵”时,就说明数组中没有目标值,查找失败。
为此,我们要特意在数组中留出一个位置给“哨兵”,并且把哨兵的值设置为目标值:

像这样,从另一侧往“哨兵”一侧遍历。如果数组中有目标值,则一定能找到;如果数组中没有目标值,那么就会遍历至“哨兵”而停下,因为“哨兵”的值就是目标值,所以返回下标为 0 时,意味着查找失败。
/**
* @description: 顺序查找改进,增加哨兵
* @param {int} *array array[0] 不存放数据元素,充当哨兵
* @param {int} length 数组长度
* @param {int} key 目标值
* @return {int} 返回0,即哨兵下标,则查找失败;否则成功
*/
int sequential_search_pro(int *array, int length, int key)
{
array[0] = key; // 哨兵
int index = length - 1;
while (array[index] != key) {
index--;
}
return index;
}
在一侧放置“哨兵”的做法避免了每次遍历进行的数组越界检查,这样能提高效率。你可能会问就一句比较能提高多少效率?蚊子腿再小也是肉,而且当数据量很多时,这些“蚊子腿”就会积累成“大象腿”了。
以上就是顺序查找的基本内容,虽然加了“哨兵”可以小小地优化一下,但当数据量极大时,仍然改变不了这种查找方法效率低下的事实。
因为我们是从一头到另一头“顺序遍历”,所以有时候可能目标值就在第一个位置,只查找一次就找到了,仿佛是天选之子;但有时候可能目标值在最后一个位置,那就需要把所有元素都查找一遍才行,当有千万、亿条数据时,这种就太可怕了。
当然,优点也有:算法简单好理解、适合数据量小的情况使用(使用时尽量把常用数据排在前面,这样可以提高效率)。
3. 二分查找(Binary Search)
回到上面举得那个点名册的例子,那样一个个地找学号或姓名实在是太慢了,有没有什么更快的方法呢?
其实,在日常生活中的点名册更多的是已排序的,比如按姓氏首字母、按学号大小排序,这样一来,在找名字或找学号的时候就能有一个大致的区域了,而不必从头到尾一个个地找。
所以,排好序的集合是便于查找的。下面介绍一种利用已排序的查找——二分查找(或折半查找)。
所谓二分查找,关键在“二分”“折半”上,顾名思义,不断将集合进行二分(折半)拆分,以此将集合拆分几个区域,然后在某个区域中查找。前提条件是集合中的元素是有序的,元素必须采用顺序表(数组)存储。
二分查找思想:
在有序顺序表中,取中间元素,将有序顺序表分为左半区和右半区,比较中间元素的关键字和目标值 key 是否相等:
- 如果相等,则查找成功,返回中间元素的信息;
- 如果不相等,说明目标值
key在左半区或右半区:- 若目标值
key小于中间元素的关键字,则来到左半区; - 若目标值
key大于中间元素的关键字,则来到右半区;
- 若目标值
不断在各半区中重复上述过程,直到查找成功;否则,则集合中无目标值,查找失败。
下面结合实例,看一下具体过程。
这是一个有序的数组,我们要查找 33:
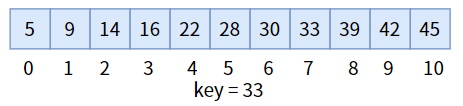
要想将数组分为左右半区,需要三个标致:最左标志位 left、最右标志位 right 和中间标志位 mid。其中 mid = (left + right) / 2,确定了 mid 的值之后,与目标值 key进行比较:

中间值 28 小于目标值key,说明目标值在右半区,所以更新三个标志位,进入右半区,然后继续比较:
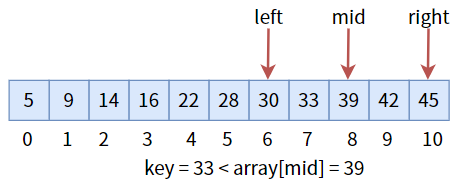
中间值 39 大于目标值key,更新三个标志位,进入左半区:

中间值 30 小于目标值key,更新三个标志位,进入右半区:
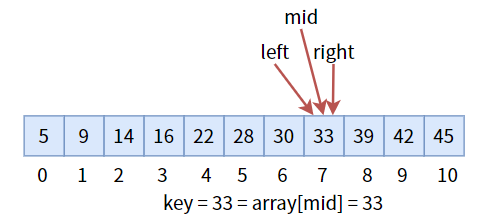
中间值 33 等于目标值key,返回其下标,即 mid。
具体代码如下:
/**
* @description: 二分查找
* @param {int} *array 有序数组
* @param {int} length 数组长度
* @param {int} key 目标值,和关键字比较
* @return {int} 返回目标值下标;若查找失败,则返回 -1
*/
int binary_search(int *array, int length, int key)
{
int left, mid, right;
left = 0;
right = length - 1;
while (left <= right) {
mid = (left + right) / 2; // 中间下标
if (key < array[mid]) { // key 比中间值小
right = mid - 1; // 更新最右下标,进入左半区
} else if (key > array[mid]) { // key 比中间值大
left = mid + 1; // 更新最左下标,进入右半区
} else {
return mid; // key 等于中间值,返回其下标
}
}
return -1; //未找到,返回 -1
}
二分查找的精髓在于中间标志位 mid 把有序顺序表一分为二,通过比较中间值和目标值的大小关系,能够筛选掉一半的数据,相当于减少了一半的工作量。
上例只比较了四次,就找到了目标值,如果使用顺序查找,则需要八次。
可以看出,二分查找的效率相较于顺序查找有了很大提高,但美中不足的是二分查找必须要求元素有序。在元素的有序状态不变化或不经常变化的情景下,二分查找非常合适;但是如果涉及到频繁的插入和删除操作,就意味着元素的有序状态会被频繁破坏,这样一来,我们就不得不花精力去维护元素的有序状态,自然又会降低效率,所以要根据实际情况灵活取舍。
以上就是顺序查找和二分查找的内容。
如有错误,还请指正。
如果觉得写的不错,可以点个赞和关注。后续会有更多数据结构和算法相关文章。
