引言
在介绍布隆过滤器之前我们首先引入几个场景。
场景一
在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0,但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?
有人说, 将这个key的值置为0存入缓存不就行了吗?确实,这是一个好的方案。大部分情况我们都是这样做的,当访问一个不存在的key的时候,设置一个带有过期时间的标志,然后放入缓存。不过这样做的缺点也很明显,浪费内存和无法抵御随机key攻击。
场景二
在一个黑名单系统中,我们需要设置很多黑名单内容。比如一个邮件系统,我们需要设置黑名单用户,当判断垃圾邮件的时候,要怎么去做。比如爬虫系统,我们要记录下来已经访问过的链接避免下次访问重复的链接。
在邮件很少或者用户很少的情况下,我们用普通数据库自带的查询就能完成。在数据量太多的时候,为了保证速度,通常情况下我们会将结果缓存到内存中,数据结构用hash表。这种查找的速度是O(1),但是内存消耗也是惊人的。打个比方,假如我们要存10亿条数据,每条数据平均占据32个字节,那么需要的内存是64G,这已经是一个惊人的大小了。
一种解决思路
能不能有一种思路,查询的速度是O(1),消耗内存特别小呢?前辈门早就想出了一个很好的解决方案。由于上面说的场景判断的结果只有两种状态(是或者不是,存在或者不存在),那么对于所存的数据完全可以用位来表示!数据本身则可以通过一个hash函数计算出一个key,这个key是一个位置,而这个key所对的值就是0或者1(因为只有两种状态),如下图:
布隆过滤器原理
上面的思路其实就是布隆过滤器的思想,只不过因为hash函数的限制,多个字符串很可能会hash成一个值。为了解决这个问题,布隆过滤器引入多个hash函数来降低误判率。
下图表示有三个hash函数,比如一个集合中有x,y,z三个元素,分别用三个hash函数映射到二进制序列的某些位上,假设我们判断w是否在集合中,同样用三个hash函数来映射,结果发现取得的结果不全为1,则表示w不在集合里面。
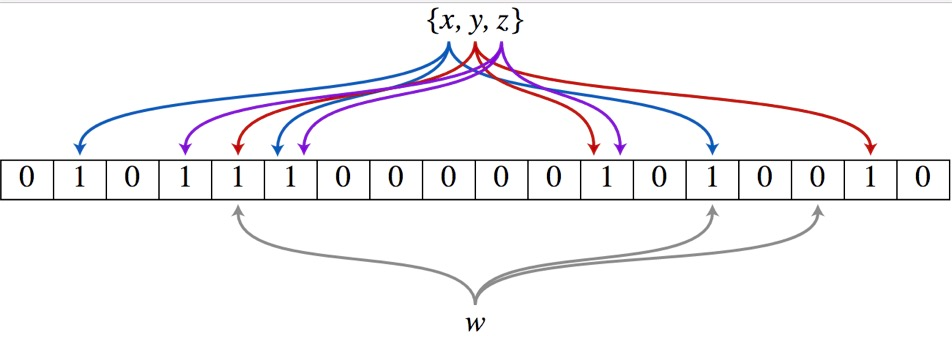
布隆过滤器处理流程
布隆过滤器应用很广泛,比如垃圾邮件过滤,爬虫的url过滤,防止缓存击穿等等。下面就来说说布隆过滤器的一个完整流程,相信读者看到这里应该能明白布隆过滤器是怎样工作的。
第一步:开辟空间
开辟一个长度为m的位数组(或者称二进制向量),这个不同的语言有不同的实现方式,甚至你可以用文件来实现。
第二步:寻找hash函数
获取几个hash函数,前辈们已经发明了很多运行良好的hash函数,比如BKDRHash,JSHash,RSHash等等。这些hash函数我们直接获取就可以了。
第三步:写入数据
将所需要判断的内容经过这些hash函数计算,得到几个值,比如用3个hash函数,得到值分别是1000,2000,3000。之后设置m位数组的第1000,2000,3000位的值位二进制1。
第四步:判断
接下来就可以判断一个新的内容是不是在我们的集合中。判断的流程和写入的流程是一致的。
误判问题
布隆过滤器虽然很高效(写入和判断都是O(1),所需要的存储空间极小),但是缺点也非常明显,那就是会误判。当集合中的元素越来越多,二进制序列中的1的个数越来越多的时候,判断一个字符串是否在集合中就很容易误判,原本不在集合里面的字符串会被判断在集合里面。
数学推导
布隆过滤器原理十分简单,但是hash函数个数怎么去判断,误判率有多少?
假设二进制序列有m位,那么经过当一个字符串hash到某一位的概率为:
1m
也就是说当前位被反转为1的概率:
p(1)=1m
那么这一位没有被反转的概率为:
p(0)=1−1m
假设我们存入n各元素,使用k个hash函数,此时没有被翻转的概率为:
p(0)=(1−1m)nk
那什么情况下我们会误判呢,就是原本不应该被翻转的位,结果翻转了,也就是
p(误判)=1−(1−1m)nk
由于只有k个hash函数同时误判了,整体才会被误判,最后误判的概率为
p(误判)=(1−(1−1m)nk)k
要使得误判率最低,那么我们需要求误判与m、n、k之间的关系,现在假设m和n固定,我们计算一下k。可以首先看看这个式子:
(1−1m)nk
由于我们的m很大,通常情况下我们会用2^32来作为m的值。上面的式子中含有一个重要极限
limx→∞(1+1x)x=e
因此误判率的式子可以写成
p(误判)=(1−(e)−nk/m)k
接下来令t=−n/m,两边同时取对数,求导,得到:
p′1p=ln(1−etk)+klnet(−etk)1−etk
让p′=0,则等式后面的为0,最后整理出来的结果是
(1−etk)ln(1−etk)=etklnetk
计算出来的k为ln2mn,约等于0.693mn,将k代入p(误判),我们可以得到概率和m、n之间的关系,最后的结果
(1/2)ln2mn,约等于0.6185m/n
以上我们就得出了最佳hash函数个数以及误判率与mn之前的关系了。
下表是m与n比值在k个hash函数下面的误判率
| m/n | k | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 | k=8 |
| 2 | 1.39 | 0.393 | 0.400 | ||||||
| 3 | 2.08 | 0.283 | 0.237 | 0.253 | |||||
| 4 | 2.77 | 0.221 | 0.155 | 0.147 | 0.160 | ||||
| 5 | 3.46 | 0.181 | 0.109 | 0.092 | 0.092 | 0.101 | |||
| 6 | 4.16 | 0.154 | 0.0804 | 0.0609 | 0.0561 | 0.0578 | 0.0638 | ||
| 7 | 4.85 | 0.133 | 0.0618 | 0.0423 | 0.0359 | 0.0347 | 0.0364 | ||
| 8 | 5.55 | 0.118 | 0.0489 | 0.0306 | 0.024 | 0.0217 | 0.0216 | 0.0229 | |
| 9 | 6.24 | 0.105 | 0.0397 | 0.0228 | 0.0166 | 0.0141 | 0.0133 | 0.0135 | 0.0145 |
| 10 | 6.93 | 0.0952 | 0.0329 | 0.0174 | 0.0118 | 0.00943 | 0.00844 | 0.00819 | 0.00846 |
| 11 | 7.62 | 0.0869 | 0.0276 | 0.0136 | 0.00864 | 0.0065 | 0.00552 | 0.00513 | 0.00509 |
| 12 | 8.32 | 0.08 | 0.0236 | 0.0108 | 0.00646 | 0.00459 | 0.00371 | 0.00329 | 0.00314 |
| 13 | 9.01 | 0.074 | 0.0203 | 0.00875 | 0.00492 | 0.00332 | 0.00255 | 0.00217 | 0.00199 |
| 14 | 9.7 | 0.0689 | 0.0177 | 0.00718 | 0.00381 | 0.00244 | 0.00179 | 0.00146 | 0.00129 |
| 15 | 10.4 | 0.0645 | 0.0156 | 0.00596 | 0.003 | 0.00183 | 0.00128 | 0.001 | 0.000852 |
| 16 | 11.1 | 0.0606 | 0.0138 | 0.005 | 0.00239 | 0.00139 | 0.000935 | 0.000702 | 0.000574 |
| 17 | 11.8 | 0.0571 | 0.0123 | 0.00423 | 0.00193 | 0.00107 | 0.000692 | 0.000499 | 0.000394 |
| 18 | 12.5 | 0.054 | 0.0111 | 0.00362 | 0.00158 | 0.000839 | 0.000519 | 0.00036 | 0.000275 |
| 19 | 13.2 | 0.0513 | 0.00998 | 0.00312 | 0.0013 | 0.000663 | 0.000394 | 0.000264 | 0.000194 |
| 20 | 13.9 | 0.0488 | 0.00906 | 0.0027 | 0.00108 | 0.00053 | 0.000303 | 0.000196 | 0.00014 |
| 21 | 14.6 | 0.0465 | 0.00825 | 0.00236 | 0.000905 | 0.000427 | 0.000236 | 0.000147 | 0.000101 |
| 22 | 15.2 | 0.0444 | 0.00755 | 0.00207 | 0.000764 | 0.000347 | 0.000185 | 0.000112 | 7.46e-05 |
| 23 | 15.9 | 0.0425 | 0.00694 | 0.00183 | 0.000649 | 0.000285 | 0.000147 | 8.56e-05 | 5.55e-05 |
| 24 | 16.6 | 0.0408 | 0.00639 | 0.00162 | 0.000555 | 0.000235 | 0.000117 | 6.63e-05 | 4.17e-05 |
| 25 | 17.3 | 0.0392 | 0.00591 | 0.00145 | 0.000478 | 0.000196 | 9.44e-05 | 5.18e-05 | 3.16e-05 |
| 26 | 18 | 0.0377 | 0.00548 | 0.00129 | 0.000413 | 0.000164 | 7.66e-05 | 4.08e-05 | 2.42e-05 |
| 27 | 18.7 | 0.0364 | 0.0051 | 0.00116 | 0.000359 | 0.000138 | 6.26e-05 | 3.24e-05 | 1.87e-05 |
| 28 | 19.4 | 0.0351 | 0.00475 | 0.00105 | 0.000314 | 0.000117 | 5.15e-05 | 2.59e-05 | 1.46e-05 |
| 29 | 20.1 | 0.0339 | 0.00444 | 0.000949 | 0.000276 | 9.96e-05 | 4.26e-05 | 2.09e-05 | 1.14e-05 |
| 30 | 20.8 | 0.0328 | 0.00416 | 0.000862 | 0.000243 | 8.53e-05 | 3.55e-05 | 1.69e-05 | 9.01e-06 |
| 31 | 21.5 | 0.0317 | 0.0039 | 0.000785 | 0.000215 | 7.33e-05 | 2.97e-05 | 1.38e-05 | 7.16e-06 |
| 32 | 22.2 | 0.0308 | 0.00367 | 0.000717 | 0.000191 | 6.33e-05 | 2.5e-05 | 1.13e-05 | 5.73e-06 |
简单实现:
/** * Implements a Bloom Filter */ class BloomFilter { /** * Size of the bit array * * @var int */ protected $m; /** * Number of hash functions * * @var int */ protected $k; /** * Number of elements in the filter * * @var int */ protected $n; /** * The bitset holding the filter information * * @var array */ protected $bitset; /** * 计算最优的hash函数个数:当hash函数个数k=(ln2)*(m/n)时错误率最小 * * @param int $m bit数组的宽度(bit数) * @param int $n 加入布隆过滤器的key的数量 * @return int */ public static function getHashCount($m, $n) { return ceil(($m / $n) * log(2)); } /** * Construct an instance of the Bloom filter * * @param int $m bit数组的宽度(bit数) Size of the bit array * @param int $k hash函数的个数 Number of different hash functions to use */ public function __construct($m, $k) { $this->m = $m; $this->k = $k; $this->n = 0; /* Initialize the bit set */ $this->bitset = array_fill(0, $this->m - 1, false); } /** * False Positive的比率:f = (1 – e-kn/m)k * Returns the probability for a false positive to occur, given the current number of items in the filter * * @return double */ public function getFalsePositiveProbability() { $exp = (-1 * $this->k * $this->n) / $this->m; return pow(1 - exp($exp), $this->k); } /** * Adds a new item to the filter * * @param mixed Either a string holding a single item or an array of * string holding multiple items. In the latter case, all * items are added one by one internally. */ public function add($key) { if (is_array($key)) { foreach ($key as $k) { $this->add($k); } return; } $this->n++; foreach ($this->getSlots($key) as $slot) { $this->bitset[$slot] = true; } } /** * Queries the Bloom filter for an element * * If this method return FALSE, it is 100% certain that the element has * not been added to the filter before. In contrast, if TRUE is returned, * the element *may* have been added to the filter previously. However with * a probability indicated by getFalsePositiveProbability() the element has * not been added to the filter with contains() still returning TRUE. * * @param mixed Either a string holding a single item or an array of * strings holding multiple items. In the latter case the * method returns TRUE if the filter contains all items. * @return boolean */ public function contains($key) { if (is_array($key)) { foreach ($key as $k) { if ($this->contains($k) == false) { return false; } } return true; } foreach ($this->getSlots($key) as $slot) { if ($this->bitset[$slot] == false) { return false; } } return true; } /** * Hashes the argument to a number of positions in the bit set and returns the positions * * @param string Item * @return array Positions */ protected function getSlots($key) { $slots = array(); $hash = self::getHashCode($key); mt_srand($hash); for ($i = 0; $i < $this->k; $i++) { $slots[] = mt_rand(0, $this->m - 1); } return $slots; } /** * 使用CRC32产生一个32bit(位)的校验值。 * 由于CRC32产生校验值时源数据块的每一bit(位)都会被计算,所以数据块中即使只有一位发生了变化,也会得到不同的CRC32值。 * Generates a numeric hash for the given string * * Right now the CRC-32 algorithm is used. Alternatively one could e.g. * use Adler digests or mimick the behaviour of Java's hashCode() method. * * @param string Input for which the hash should be created * @return int Numeric hash */ protected static function getHashCode($string) { return crc32($string); } } $items = array("first item", "second item", "third item"); /* Add all items with one call to add() and make sure contains() finds * them all. */ $filter = new BloomFilter(100, BloomFilter::getHashCount(100, 3)); // var_dump($filter); exit; $filter->add($items); // var_dump($filter); exit; $items = array("firsttem", "seconditem", "thirditem"); foreach ($items as $item) { var_dump(($filter->contains($item))); } /* Add all items with multiple calls to add() and make sure contains() * finds them all. */ $filter = new BloomFilter(100, BloomFilter::getHashCount(100, 3)); foreach ($items as $item) { $filter->add($item); } $items = array("fir sttem", "secondit em", "thir ditem"); foreach ($items as $item) { var_dump(($filter->contains($item))); }