爬虫是现代通过互联网获取数据的很重要的一种方法,我相信它在后续工作学习中也能够发挥一定用处。
之前已经学过一些爬虫基本知识,接下来开始记录一下个人在爬虫学习过程中的一些思路与解决办法。
一、目标
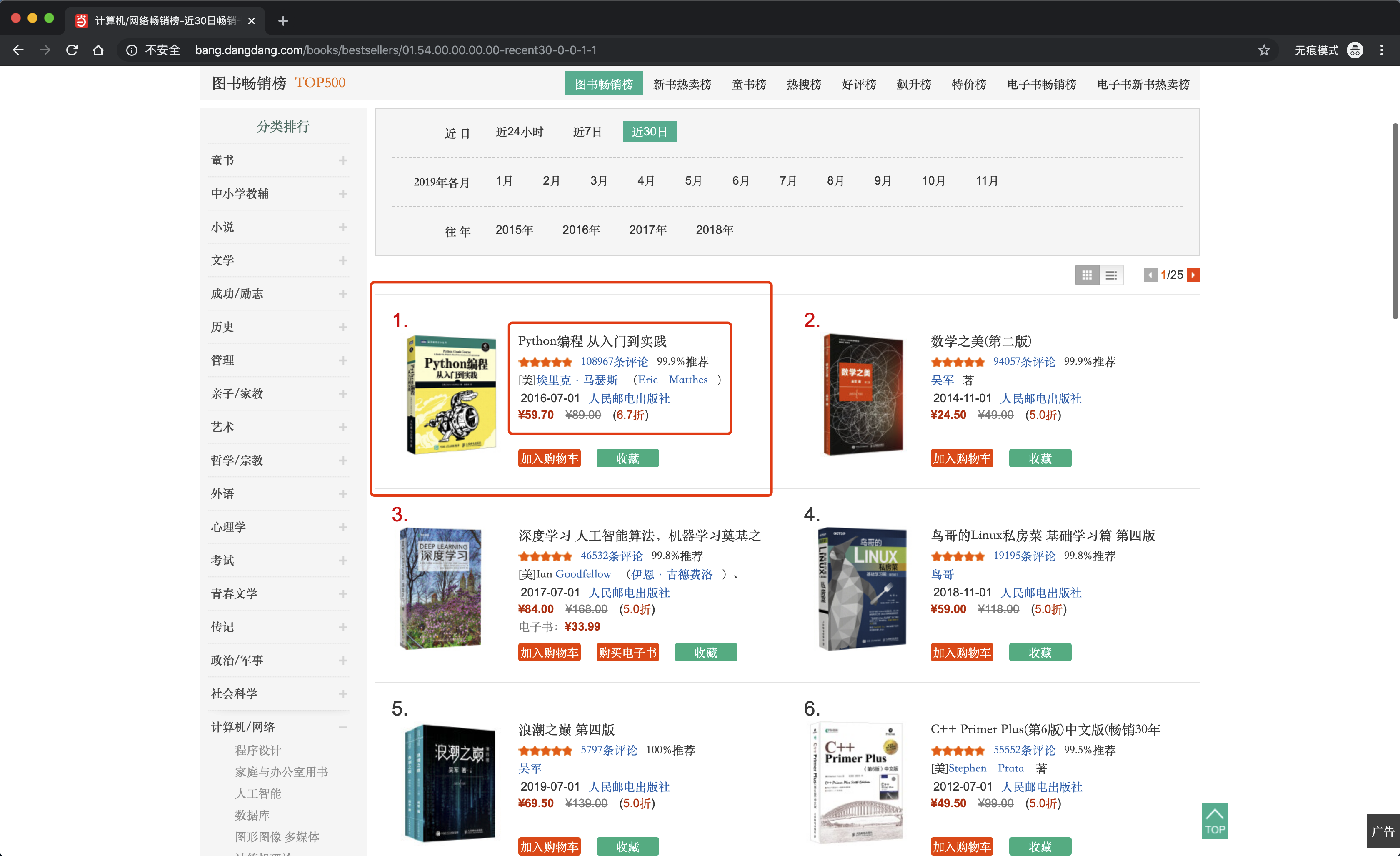
这次要爬取的网页是当当网TOP500图书畅销榜,这个网页收纳了当当网上近30日最畅销的500本书籍,每页展示20本,一共25页。
要爬取的数据,就是每本书籍的标题、评论数、作者、售价等信息。
二、分析网页
1)找到传输数据的连接
按 F12 打开 Chrome 浏览器的检查窗口,刷新页面。
点击查看发现,XHR 异步加载这部分是空白。而在 ALL 这部分里,按照 Size 降序排列,排在最前的是一个 Document 类型的传输,并且传输时间持续较长。
(这里有一个小窍门,不管网页上的内容是通过什么样的方式传输,我们想要爬取的数据往往是从数据传输的主体中提取。而数据主体的流量使用是较大的)
推测,页面的主要内容是通过这个来传输的。

接下来查看这个 Document 类型传输的返回值 Response,大致浏览一下能够发现,要爬取的数据于其中明文传输。
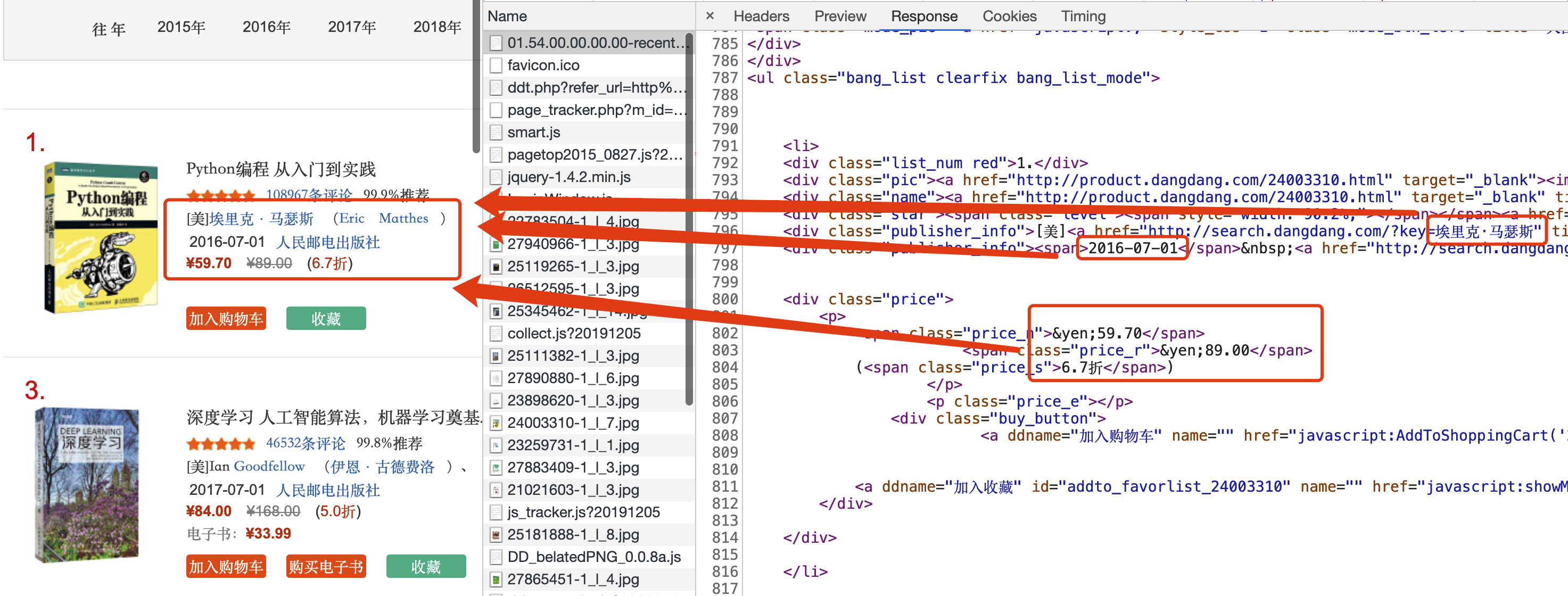
所以,可以确定,访问这个连接就可以拿到我们想要的数据。
2)该连接的传输方式
查看这个 Document 类型传输的 Headers,我们可以从中得出浏览器发出连接请求时所用的关键信息。
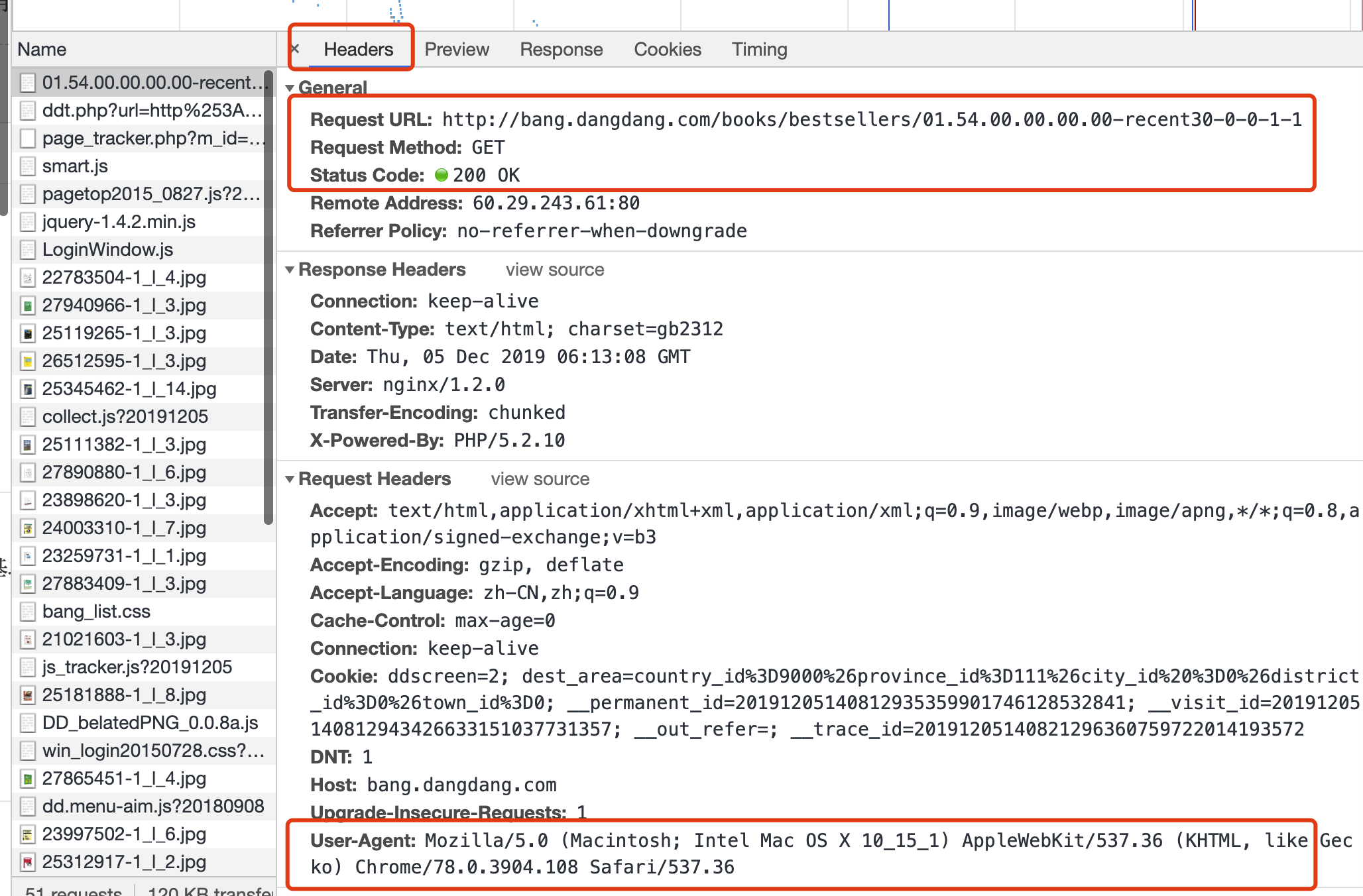
可以看出,这个连接的 URL 是 http://bang.dangdang.com/books/bestsellers/01.54.00.00.00.00-recent30-0-0-1-1,请求方式是 GET。
所以,我们可以使用 requests 包,构建一个 GET 类型的请求,并且使用 User-Agent 将爬虫伪装成浏览器进行请求。
3)翻页逻辑
不要关闭检查窗口,在网页上点击按钮翻到第2页。可以看到窗口中出现了一个新的 Document 类型的连接,不同之处在于末尾的数字变成了2。
重复上述操作1和2,可以发现我们要抓取的第二页的数据,都来自于这个新的 Document 类型连接,并且传输格式大体一致。
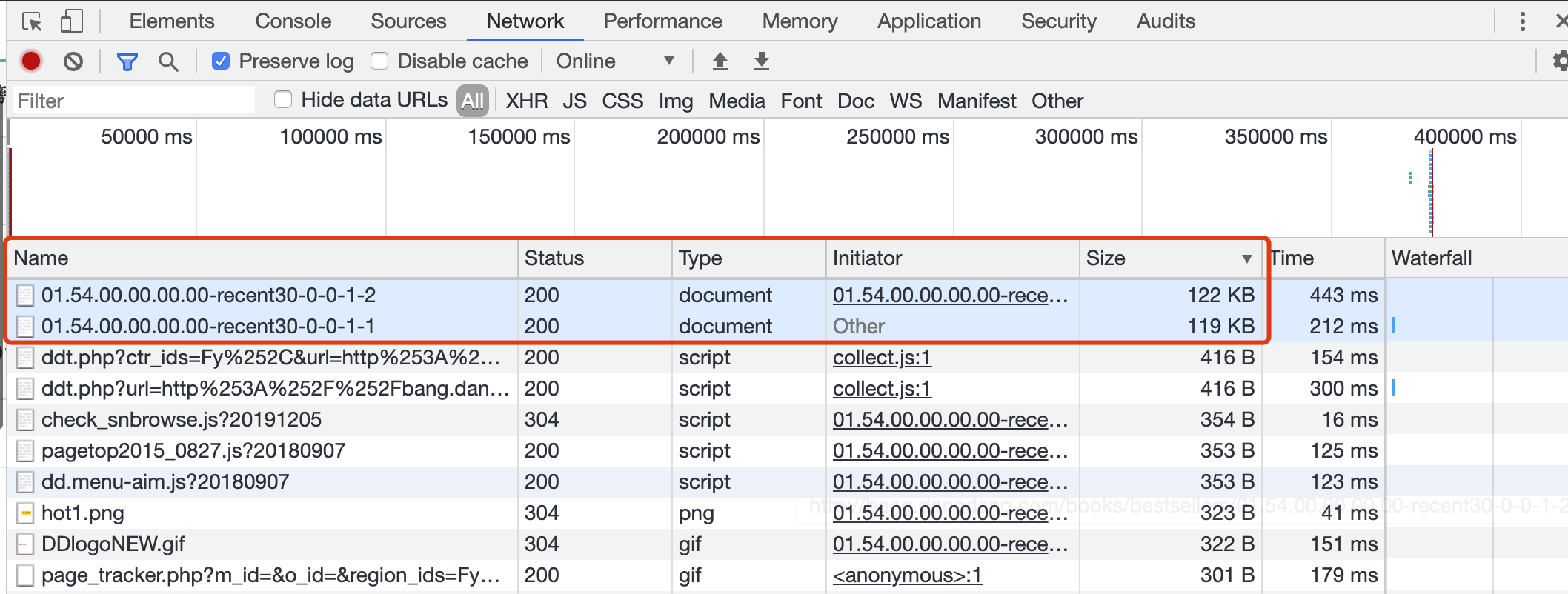
其中第二页对应连接的 URL 是 http://bang.dangdang.com/books/bestsellers/01.54.00.00.00.00-recent30-0-0-1-2。
随便翻了几页查看 URL,找到规律:第 N 页对应的 URL 地址是 http://bang.dangdang.com/books/bestsellers/01.54.00.00.00.00-recent30-0-0-1-N。
所以,我们可以通过更改 URL 结尾的数字实现翻页,其中 N 取值范围是 [1, 25]。
4)提取元素
在1)中,我们已经找到了,书籍对应的信息都在 Document 类型的连接中可以找到。接下来的问题是,如何从 Document 返回的信息中提取每本书籍对应的信息。
我们要找的是每本书籍对应的信息位置,以第一本书为例。把鼠标移至网页上这本书附近,右键选择【检查】,可以看到在检查窗口中的 Elements 部分已经定位到了第一本书的信息。
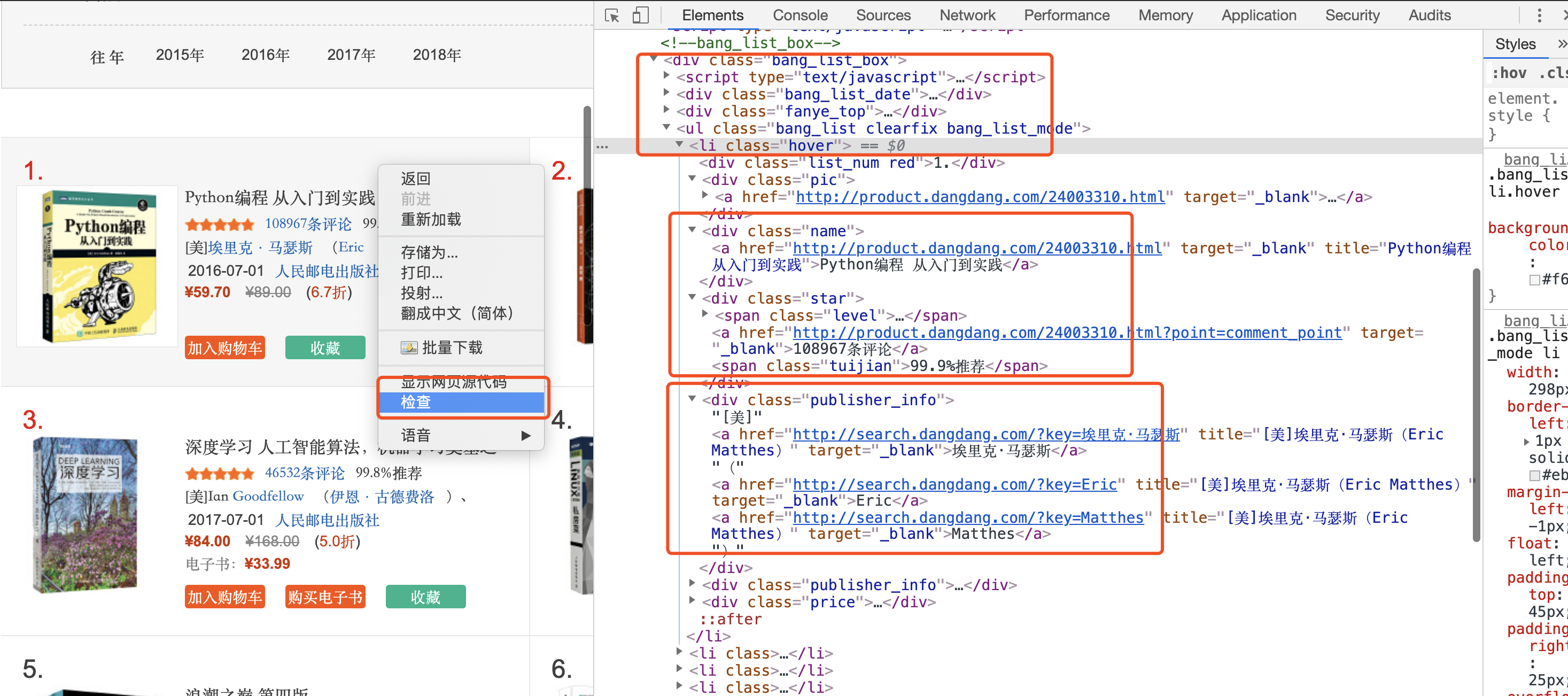
上下移动鼠标,可以发现,<ul class="bang_list clearfix bang_list_mode">包含的是页面上所有书籍的信息,其中同一本书籍的信息都包含在一个 <li> 中,不同书籍的信息对应不同的 <li> 之中。
所以,我们可以使用 BeautifulSoup 这个模块,把想要的信息提取出来,另行保存。
三、总结
当当网TOP500图书畅销榜这个页面没有什么明显的反爬措施,数据也是直接通过 HTML 进行传输,没有使用异步加载等方式传输,也没有经过 JS 加密处理。
只需要熟悉基本的爬虫操作步骤就可以爬取数据,难度低适合新人练习。