---恢复内容开始---
一,个人心得
我觉得学习python就想玩一款游戏,python的基本数据类型(字符串 数字 列表 元组 字典)可以看做一个游戏职业,每个职业都有相应的技能。
玩好这些职业,让我们的python之旅更加容易。
二,数字(职业:初级剑士,技能较少)
在python语言中,数字类型主要包括整形,浮点数,和复数。
整形 int
浮点数 float
复数 complex(real [,image])
数字的技能:
hex(x) 将一个整形x转化为一个十六进制字符串
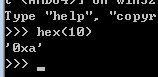
oct(x) 将一个整形x转化为一个八进制字符串
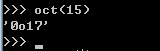
x . bit_length() 整形x对应的二进制的占位个数
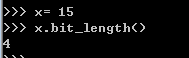
三,字符串(职业:三转剑士(剑神),技能较多)
字符串就是连续的字符序列,可以是计算机所能表示的一切字符的合集。
字符串的技能:
字符串的拼接:字符串与字符串之间可以通过 + 来实现拼接。
str1 = '我今天一共走了' num = 12098 str2 = '步' print(str1 + str(num)+ str2 )

len.(x) 字符串x的长度
str1 = '我今天一共走了' c = len(str1) print(c)

x.[:] 字符串的截取
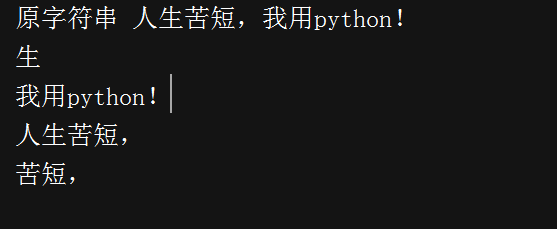
#!/D:\python # -*- coding:utf-8 -*- str1 = '人生苦短,我用python!' s1 = str1[1] s2 = str1[5:] s3 = str1[:5] s4 = str1[2:5] print('原字符串',str1) print(s1+'\n'+ s2 + '\n'+s3 +'\n'+s4)
x.split() 分割字符串
#!/D:\python # -*- coding:utf-8 -*- str1 = '人生苦短,我用python!>>> www.lll.ccv' print('原字符串:',str1) a = str1.split() b = str1.split('>>>') c = str1.split('.') print(a) print(b) print(c)

x.join() 合并字符串
#!/D:\python # -*- coding:utf-8 -*- l = ['小明','小王','小李','小张'] a = ' @'.join(l) # b = '@' + a print('你要@的好友:',a)

x.count() count 方法用于检索指定字符串在另一个字符串中出现的次数
#!/D:\python # -*- coding:utf-8 -*- l = '@小明 @小王 @小号 ' print('字符串',l ,'包括',l.count('@'),'个@字符')

x.find() 用于检索是否含有指定的子字符串。如果检索的字符串不存在,返回 -1,否则返回首次出现子字符串时索引。
#!/D:\python # -*- coding:utf-8 -*- l = '@小明 @小王 @小号 ' print('字符串',l,'中@字符串首次出现的位置索引为',l.find('@'))

另外 x。index('@')
x.startswith() 检索字符串是否以指定子字符串开头
#!/D:\python # -*- coding:utf-8 -*- l = '@小明 @小王 @小号 ' print('字符串',l,'是否以@开头',l.startswith('@'))

x.endswith() 检索字符串是否以指定子字符串结尾
#!/D:\python # -*- coding:utf-8 -*- l = '@小明 @小王 @小号 ' print('字符串',l,'是否以@结尾',l.endswith('@'))

字母大写小写转化 x.upper() x.lower()
x.strip() 用于去掉字符串左右两侧的空格和特殊字符。
#!/D:\python # -*- coding:utf-8 -*- s1 = ' http://www.baidu.com \t\n\r ' print('原字符串:'+ s1 +'.') print('字符串:'+ s1.strip()+'。') s2 = '@摩天营救@' print('原字符串s2;'+ s2 + '。') print('字符串:'+ s2.strip('@') + '。')

%格式化字符串 ‘%[-][+][0][m][.n]格式化字符’%exp
#!/D:\python # -*- coding:utf-8 -*- t = '编号: %09d\t 公司名称 : %s \t 官网: http://www.%s.com' c = (7,'百度','baidu') print(t%c)

format() 格式化字符串
#!/D:\python # -*- coding:utf-8 -*- t = '编号: {}\t 公司名称 : {} \t 官网: http://www.{}.com' print(t.format('7','百度','baidu'))

字符串编码转换
#!/D:\python # -*- coding:utf-8 -*- v = '野渡无人舟自横' b = v.encode('gbk') a = v.encode('utf-8') print('原字符串:',v) print('gbk转换后:',b) print('utf-8转换后',a)
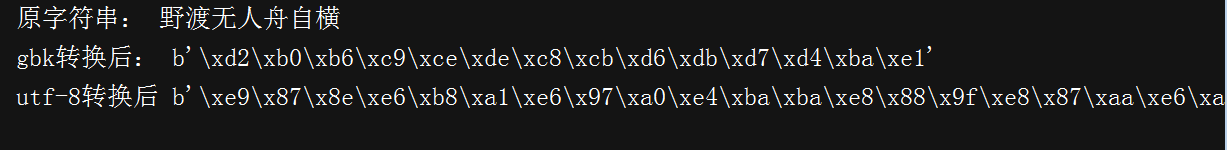
decode () 方法解码
#!/D:\python # -*- coding:utf-8 -*- v = b'\xd2\xb0\xb6\xc9\xce\xde\xc8\xcb\xd6\xdb\xd7\xd4\xba\xe1' c = b'\xe9\x87\x8e\xe6\xb8\xa1\xe6\x97\xa0\xe4\xba\xba\xe8\x88\x9f\xe8\x87\xaa\xe6\xa8\xaa' b = v.decode('gbk') a = c.decode('utf-8') print('原字码:',v) print('原字码:',c) print('gbk转换后:',b) print('utf-8转换后',a)

四,列表(弓箭手,技能较多)
列表切片
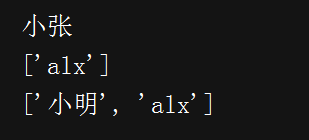
#!/D:\python # -*- coding:utf-8 -*- List = ['小明','小张','alx','zhangsan'] a = List[1] b = List[2:3] c = List[0:3:2] print(a) print(b) print(c)
列表的创建
emptylist = []
创建数值列表
list(data)
例如; list (rrnge(10,20,2))
删除列表中的元素 del []
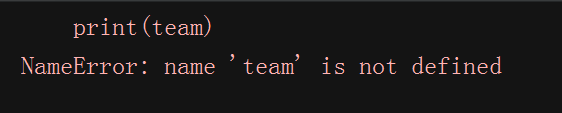
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen'] del team print(team)
遍历列表 直接使用for循环实现
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] for i in team: print(i)

使用for循环和enumerate()函数实现
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] for index,i in enumerate(team): print(index+1,i)

#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] for index,i in enumerate(team): if index%2 == 0: print(i + "\t\t",end='') else: print(i + "\n")

添加,修改和删除列表元素
x.append()
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] a = len(team) print(a) team.append("小学") c = len(team) print(c) print(team)

x.extend()
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] l = ['1','58','888'] a = len(team) print(a) team.extend(l) c = len(team) print(c) print(team)

修改元素
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] print(team) team[3] = '小法' print(team)

删除元素
x.remove(' c') c表示要删除的元素
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王'] print(team) team.remove('小李') print(team)

x.count() 获得指定元素出现的次数
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王','小王'] c = team.count('小王') print(c)

x.index() 获取指定元素首次出现的下标
#!/D:\python # -*- coding:utf-8 -*- team = ['huama','louam','bairen','小明','小李','小王','小王'] c = team.index('小王') print(c)

统计数值列表的元素和
#!/D:\python # -*- coding:utf-8 -*- team = [2,5,7,9,5,14,15] c = sum(team[:]) a = sum(team[1:5]) print(c) print(a)

对列表进行排序
#!/D:\python # -*- coding:utf-8 -*- grade = [58,5,12,9,5,14,15] print(grade) a = sorted(grade) print('升序',a) c = sorted(grade,reverse=True) print('降序',c)

列表推导式
LIst = [Expression for var in range]
#!/D:\python # -*- coding:utf-8 -*- import random randomnumber = [random.randint(10,100) for i in range(10)] print("生成的随机数为:",randomnumber)

二维列表的使用
使用嵌套的for循环创建
五,元组
元组的创建和删除
emptytuple = ()
#!/D:\python # -*- coding:utf-8 -*- c = tuple(range(10,20,2)) print(c)
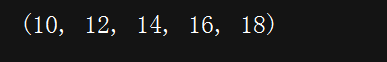
删除元组 del list
元组不可以修改
六,字典
字典,每个元素都包含两部分‘键’和‘值’
dictionary = {'key1':'value1','key2':'value2',.........,'keyn':'valuen'}
通过映射函数创建字典
dictionaryd = dict(zip(list1,list2))
#!/D:\python # -*- coding:utf-8 -*- name = ['幽梦','冷血','带蓝'] sign = ['水瓶座','射手座','双鱼座'] dictionary = dict(zip(name,sign)) print(dictionary)

通过给定“键”-值对"创建字典
dictonary = dict.fromkeys(list1)
#!/D:\python # -*- coding:utf-8 -*- name = ['幽梦','冷血','带蓝'] dictionary = dict.fromkeys(name) print(dictionary)

通过键值对访问字典
#!/D:\python # -*- coding:utf-8 -*- name = {'1':'幽梦','2':'冷血','3':'带蓝'} print(name['1'])
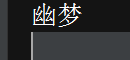
字典的遍历
#!/D:\python # -*- coding:utf-8 -*- name = {'1':'幽梦','2':'冷血','3':'带蓝'} for key,value in name.items(): print(key,value)

添加,修改和删除字典元素
#!/D:\python # -*- coding:utf-8 -*- name =dict((('1','幽梦'),('2','冷血'),('3','带蓝'))) print(name) name['4']='重新' print(name)

修改
#!/D:\python # -*- coding:utf-8 -*- name =dict((('1','幽梦'),('2','冷血'),('3','带蓝'))) print(name) name['1']='重新' print(name)

删除
#!/D:\python # -*- coding:utf-8 -*- name =dict((('1','幽梦'),('2','冷血'),('3','带蓝'))) print(name) del name['2'] print(name)

字典推导式
#!/D:\python # -*- coding:utf-8 -*- name = ['按时','等等','次数','问问'] sign =['1分钟','我','2次','谁'] dictionary = {i:j+'hh' for i,j in zip(name,sign)} print(dictionary)
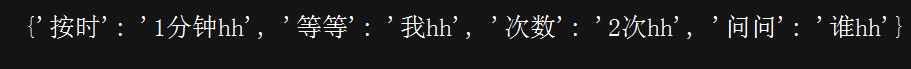
2018-11-19 15:07:32
---恢复内容结束---