本文首发于:行者AI
在多agent的强化学习算法中,前面我们讲了QMIX,其实VDN是QMIX的一个特例,当求导都为1的时候,QMIX就变成了VDN。QTRAN也是一种关于值分解的问题,在实际的问题中QTRAN效果没有QMIX效果好,主要是QTRAN的约束条件太过于松散,导致实际没有理论效果好。但是QTRAN有两个版本,QTRAN_BASE和QTRAN_ALT,第二版本效果比第一要好,在大部分实际问题中和QMIX的效果差不多。
上述的算法都是关于值分解的,每个agent的回报都是一样的。如果在一局王者荣耀的游戏中,我方大顺风,我方一名角色去1打5,导致阵亡,然后我方4打5,由于我方处于大优势,我方团灭对方,我方所有的agent都获得正的奖励。开始去1打5的agnet也获得了一个正的奖励,显然他的行为是不能获得正的奖励。就出现了“吃大锅饭”的情况,置信度分配不均。
COMA算法就解决了这种问题,利用反事实基线来解决置信度分配的问题。COMA是一种“非中心化”的策略控制系统。
1. Actor-Critic
COMA主要采样了Actor-Critic的主要思想,一种基于策略搜索的方法,中心式评价,边缘式决策。
2. COMA
COMA主要使用反事实基线来解决置信分配问题。在协作智能体的系统中,判断一个智能体执行一个动作的的贡献有多少,智能体选取一个动作成为默认动作(以一种特殊的方式确认默认动作),分别执行较默认动作和当前执行的动作,比较出这两个动作的优劣性。这种方式需要模拟一次默认动作进行评估,显然这种方式增加了问题的复杂性。在COMA中并没有设置默认动作,就不用额外模拟这基线,直接采用当前策略计算智能体的边缘分布来计算这个基线。COMA采用这种方式大大减少了计算量。
基线的计算:
COMA网络结构
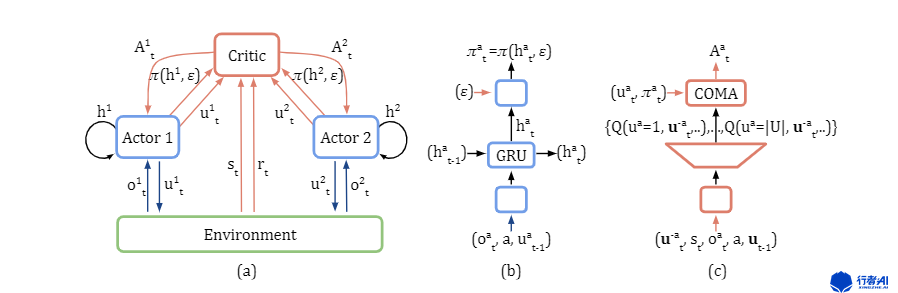
图中(a)表示COMA的集中式网络结构,(b)表示actior的网络结构,(c)表示Critic的网络结构。
3. 算法流程
-
初始化actor_network,eval_critic_network,target_critic_network,将eval_critic_network的网络参数复制给target_critic_network。初始化buffer (D),容量为(M),总迭代轮数(T),target_critic_network网络参数更新频率(p)。
-
(for) (t)=(1) (to) (T) (do)
1)初始化环境
2)获取环境的(S),每个agent的观察值(O),每个agent的(avail) (action),奖励(R)。
3)(for) (step=1) (to) (episode)_(limit)
a)每个agent通过actor_network,获取每个动作的概率,随机sample获取动作(action)。actor_network,采用的GRU循环层,每次都要记录上一次的隐藏层。
b)执行(action),将(S),(S_{next}),每个agent的观察值(O),每个agent的(avail) (action),每个agent的(next) (avail) (action),奖励(R),选择的动作(u),env是否结束(terminated),存入经验池(D)。
c)(if) (len(D)) (>=) (M)
d)随机从(D)中采样一些数据,但是数据必须是不同的episode中的相同transition。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络传入每个episode的同一个位置的transition。
e)(td\_error =G_t-Q\_eval)计算loss,更新Critic参数。(G_t)表示从状态(S),到结束,获得的总奖励。
f)通过当前策略计算每个agent的每个step的基线,基线计算公式:
g)计算执行当前动作的优势advantage:
h)计算loss,更新actor网络参数:
i)(if) (t) (p==0) :
j)将eval_critic_network的网络参数复制给target_critic_network。
4. 结果对比
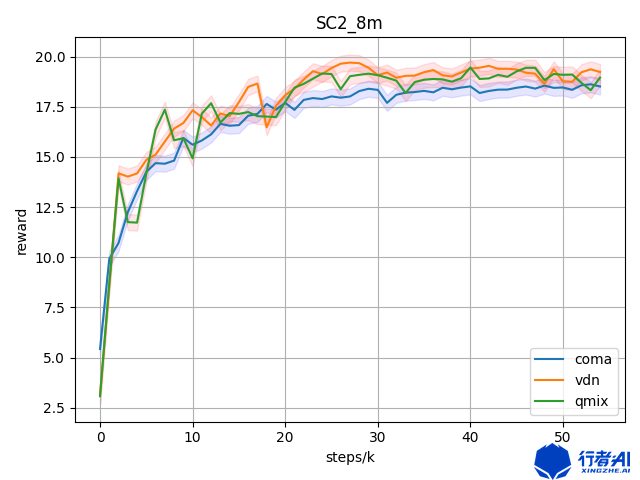
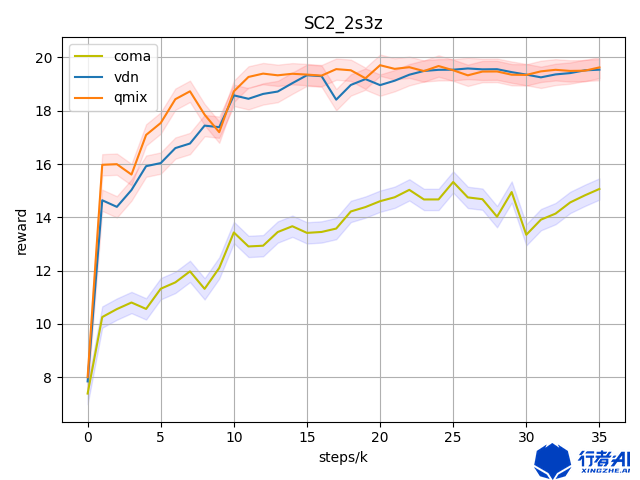
我自己跑的数据,关于QMIX,VDN,COMA,三者之间的对比,在相同场景下。
5. 算法总结
COMA在论文写的算法原理很好,但是在实际的场景中,正如上面的两张图所示,COMA的表现并不是很理想。在一般的场景中,并没有QMIX的表现好。笔者建议读者,在实际的环境中,可以试试VDN,QMIX等等,COMA不适合“带头冲锋”。
6. 资料
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!