0. overview
There are too many guides about node pressure and pod eviction, most of them are specific, and no system. so here is to combine the knowledge together and see it system and specific. Before introduce the knowledge lets us thinking those questions(actually too many questions..). What happened when the node shutdown, what happened if the API-server of Kubernetes can not connect to the Kubelet, what happened if the pod use too much resource even made the node unhealthy.
Yes, it just a piece of node pressure and pod eviction, the node pressure and pod eviction are more likely to belong to the abnormal cases, and yes those cases are very very important for business.
And here has a manifest about the guide cause is the abnormal cases and I just have the env with company product, it's serious and I don't want touch and make the env bad for our abnormal cases. So there is no too much demo with trials, for the demo I will attach the links if needed, and yes minikube is a good VM Kubernetes platform for newcomer and I also do something in minikube but I have checked with some materials online there already has a similar demo so I will pick the online materials directly.
1. container resource
As we know the app is running within a container and the resource is covered at the container level, there are limited by Cgroups. For container resource, it can be defined with CPU, memory, disk. For CPU is the compressible resources, but for memory, disk is the incompressible resources which means if one container uses too much memory, others(container/process/thread) will no too much memory can be used. so the resource limit is important, in Kubernetes, there are two fields that can define the resource: request and limit.
- requests: is the minimal resource container requests, but the container can use less than the request value.
- limits: is the maximal resource container requests, once out of the limits OOM killer will kill the container.
ok, lets us focus on the requests field, design an appropriate value that is good enough for requests cause Kubernetes will schedule the pod(container) to nodes bases on the requests, not the actual resources. For example, there is 500M memory of node can be allocated,one pod(just have one container) requests 600M but actually, the container just use 100M(the request value is more than actual value).. the container still can not scheduler to the node cause the requested memory is over than the allocated memory of the node.
here we are discussing the container resource, for pod resources, yes you probably know is the sum of all containers. now lets we thinking if the node resource is not enough and the pod needs to be evicted, which pod should be the first one? we must be thinking the low priority pods should be evicted, correct, Kubernetes has a QoS field that defined the priority of pod, how to define the priority is pretty simple by requests and limits.
there are too many guides that introduce how to define the priority: BestEffort, Burstable, and Guaranteed. I just want mentioned requests/limits are for container level, for pod QoS depends on all container requests/limits, which means all QoS of the container is the same, the pod QoS is the same as the container's Qos, but once one container QoS is different with others, the QoS of the pod is Burstable. let see the table directly:
| container1 QoS | container2 QoS | pod QoS |
|---|---|---|
| BestEffort | BestEffort | BestEffort |
| BestEffort | Burstable | Burstable |
| BestEffort | Guaranteed | Burstable |
| BestEffort | Burstable | Burstable |
| Burstable | Burstable | Burstable |
| Burstable | Burstable | Burstable |
| Burstable | Guaranteed | Burstable |
| Guaranteed | Guaranteed | Guaranteed |
For the description of QoS please refer to here.
2. node pressure eviction
In chapter1 we know that if the pod wants to use the incompressible resource more than the limits of resource, the OOM killer will kill the process, more detailed info can refer here.
Now if the node has the pressure of incompressible resources, but pods haven't use the resource over the limits, how do the Kubernetes do? it will introduce the Kubelet module of Kubernetes, Kubelet will monitor the resource of pods and report the resource to API-server, once meet the condition of pod eviction, the Kubelet will do the eviction action.
let's see the configure for Kubelet, just pick the necessary field:
[root@chunqiu ~ (Master)]# systemctl cat kubelet.service
# /etc/systemd/system/kubelet.service
...
ExecStart=/usr/local/bin/kubelet
--pod-infra-container-image=bcmt-registry:5000/gcr.io/google-containers/pause-amd64:3.1
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig
--config=/etc/kubernetes/kubelet-config.yml
...
Restart=always
RestartSec=5
Slice=system.slice
OOMScoreAdjust=-999
[root@chunqiu ~ (Master)]# cat /etc/kubernetes/kubelet-config.yml
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
...
nodeStatusUpdateFrequency: 8s
evictionPressureTransitionPeriod: "60s"
evictionMaxPodGracePeriod: 120
evictionHard:
memory.available: 9588Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
imagefs.available: 15%
evictionSoft:
memory.available: 15341Mi
evictionMminimumReclaim:
memory.available: 15341Mi
evictionSoftGracePeriod:
memory.available: "30s"
systemReserved:
memory: 33Gi
cpu: "44"
Before introducing these parameters, let's see the eviction is split into two kinds of styles: soft eviction and hard eviction. For soft eviction, there are graceful eviction time(evictionSoftGracePeriod) and also graceful eviction time for pod(evictionMaxPodGracePeriod). For hard eviction, it more like an urgent status for node, so the pod will be evicted immediately to relieve symptoms asap.
ok, let's see the parameters now, and yes the detailed introduce can be found from Kubernetes Docs here.
common parameters
- nodeStatusUpdateFrequency: as the name, Kubelet will report the node status to API-server with this frequency, for the frequency is also too much is too slow to check the status of the node, too lower will make the node update frequently. it has been discussed with the article here.
- evictionPressureTransitionPeriod: when a pod has been evicted, probably the pod will be scheduled to the same node(with a label, affinity..) at that time the node pressure will become high again, then eviction will be triggered again, so the pod will be eviction and do the same procedure like a circle(and also here has an exponential delay for pod delete, it means pod will be deleted after 10s, 20s,30s.. till default value 5minutes, after that pod will be deleted by 5min, 10min.. this mechanism is for avoiding the frequent deletion of a pod), so Kubernetes has defined a period with parameter evictionPressureTransitionPeriod is to keep no pod scheduled to the node which just eviction pods.
- evictionMminimumReclaim: see how much resource Kubernetes will be clean up, if too low the purpose of eviction is not obvious, which means the pod will scheduler to the node again and the resource pressure will high after a while. so Kubernetes will clean up to enough resources which have been defined with parameter evictionMminimumReclaim so that no more resource pressure frequently.
soft eviction
- memory.available: is the target of memory available, once over the target, the pod eviction will be triggered.
- evictionSoftGracePeriod: after fitting the target, wait the time of evictionSoftGracePeriod to see whether the target is always satisfied, once satisfied the "alarm" will be canceled.
- evictionMaxPodGracePeriod: once fitting the target and satisfied the time of evictionSoftGracePeriod, the pod will be eviction by Kubelet, and the pod needs to graceful shutdown during the time evictionMaxPodGracePeriod, is important for business. The time of evictionMaxPodGracePeriod has two places one is the time that set in the pod manifest, Kubelet will choose the minimal value, such as here the evictionMaxPodGracePeriod is 120(s), and the pod manifest has defined the time with terminationGracePeriodSeconds: 30(s), so the evictionMaxPodGracePeriod time for Kubelet is 30(s).
hard eviction
- there are no too many parameters defined for hard eviction cause hard eviction is an urgent case once met the hard condition, the pod will be evicted immediately.
emm.., another question raised up: which pod should be eviction? it more related to the QoS that we discussed in the chapter1, and the incompressible resource itself, for how to pick the evicted pod here has been introduced in detail, we just skip it, and then we know the framework now, but how do we know the real-time resource status of pod or specific containers?
It will relate with the monitor mechanism of Kubernetes, the Kubelet module of Kubernetes has integrated the cAdvisor module build-in which is to monitor the pods status. and there is another module called metrics-server that will collect all cAdvisor data together then provide to outside with Kubernetes service clusterIP:
[root@chunqiu ~ (Master)]# kubectl get pods -n kube-system | grep met
dashboard-metrics-scraper-6554464489-kptsr 1/1 Running 1 102d
metrics-server-78f8b874b5-4hdzj 2/2 Running 4 102d
[root@chunqiu ~ (Master)]# kubectl get service -n kube-system | grep met
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP **.***.246.177 <none> 443/TCP 102d
for more detailed Infos about the metrics server please refer here.
we can get the metrics server data by curl, but a more common way is to use the command: kubectl top, like:
[root@chunqiu ~ (Master)]# kubectl top pod --containers -n ci
POD NAME CPU(cores) MEMORY(bytes)
chunqiu-pod-0 container1 7m 64Mi
chunqiu-pod-0 container2 9m 83Mi
chunqiu-pod-0 container3 4m 20Mi
...
The result is different from the Kubectl describe command, this is the real-time resource status of pods.
ok, someone might see we can check the real-time result, but how do I know the resource define of containers? yes, this is related to the Linux cgroup, we can check with the container inside:
[root@chunqiu ~ (Master)]# kubectl exec -it chunqiu-pod-0 /bin/bash -n ci
bash-5.0$ ls /sys/fs/cgroup/memory/
memory.kmem.max_usage_in_bytes memory.max_usage_in_bytes memory.pressure_level
...
the container resource has been defined in cgroup, and also can check the defined with pod level, more detailed info can refer to here.
3. node eviction
Chapter2 we have discussed the case of node pressure, but how about this case that node shutdown and can not recovery long time, or network issue cause work node can not connect to the master node. For this case is also covered in Kubernetes, the controller manager has to monitor the status of the node, once the node "failed"(can cause by many factors), the Kubelet can not connect to API-server, which is an offline status, and then the controller manager will do something "delete" the pod, add Taints and scheduler the pod to other nodes. Describe the procedure is so complex, let's see a procedure figure first:
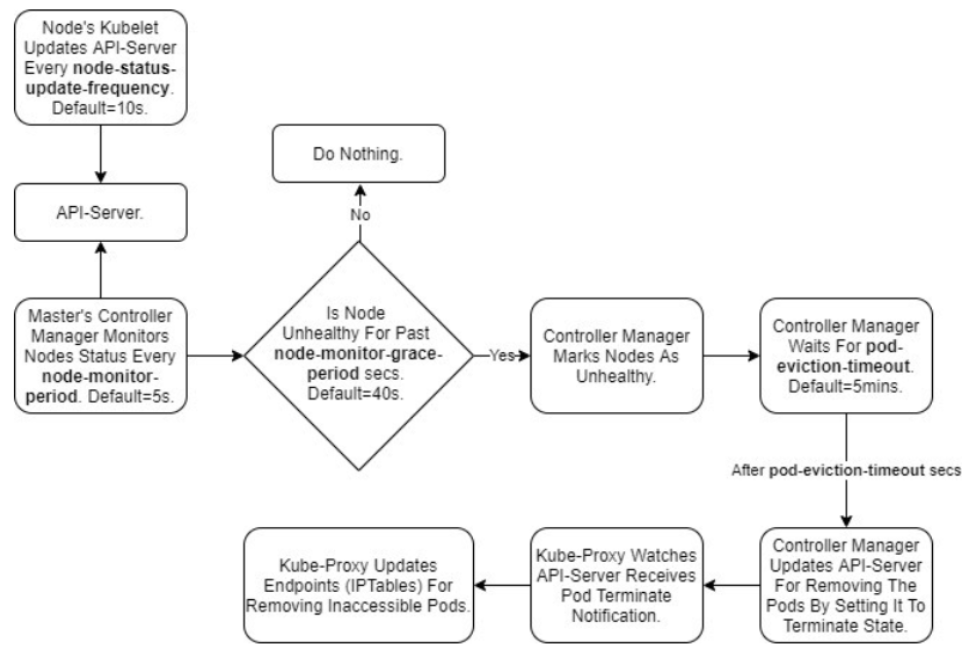
The figure is clear, we will introduce the procedure based on the figure, first, let's see the parameters that can be found by the controller-manager defined in the picture.
[root@chunqiu ~ (Master)]# kubectl get pods -n kube-system | grep controller-manager
kube-controller-manager-chunqiu-0 1/1 Running 1 102d
[root@chunqiu ~ (Master)]# kubectl describe pods kube-controller-manager-chunqiu-0 -n kube-system
Name: kube-controller-manager-chunqiu-0
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: chunqiu-0/172.17.66.2
Controlled By: Node/chunqiu-0
Command:
/usr/local/bin/kube-controller-manager
--node-monitor-period=5s
--node-monitor-grace-period=35s
--pod-eviction-timeout=120s
--terminated-pod-gc-threshold=100
State: Running
Last State: Terminated
Reason: Error
Exit Code: 255
Ready: True
Restart Count: 1
Limits:
cpu: 300m
memory: 1000Mi
Requests:
cpu: 100m
memory: 30Mi
Liveness: http-get https://127.0.0.1:10252/healthz delay=15s timeout=1s period=10s #success=1 #failure=3
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
...
There are some necessary parameters that need to introduce, the detained info can check here:
- node-monitor-period: the controller manager will query the API-server by the period of node-monitor-period.
- node-monitor-grace-period: if the status of the node is not ready or unknown with the period of node-monitor-grace-period, the node will be set as unhealthy(unknown), the default time of node-monitor-grace-period is the 40s.
- pod-eviction-timeout: after fitting the node-monitor-grace-period, the controller manager will wait the time of pod-eviction-timeout, after meeting the time, the controller manager will update the pod status as Terminating. The default time of pod-eviction timeout is 5 minutes.
Combine the procedure and parameters. Now let us summary the procedure here:
The Kubelet will report the node status to API-server with the period of nodeStatusUpdateFrequency, and then the controller manager will query the node status by API-server, here if the time is over the node-monitor-period, the node will be set as not ready(the meaning is like one give a signal to other, but other handles the signal so slowly, and also the revert case one query signal from other, but other haven't sent the signal), the more discussed the info can be checked here. ok, then if the status of the node is not ready(unhealthy)(actually, I haven't find the info about how to define the node status, like when is not ready, when is unhealthy, when is unknown, a related article is in here, it might occur together, but still need check, anyone knows the info please tell me, thanks so much). and then if the not ready status keeps until the period of node-monitor-grace-period, the node will be set as unknown, and the controller manager will wait for the time defined in pod-eviction-timeout, after that the pod will be set as Terminating but it still existing in Kubernetes cause Kubernetes doesn't know what happened with the unknown node, and also doesn't know the pod alive or not. The controller manager will set the status of the pod, and then add the Taints to the unknown nodes:
-
node.kubernetes.io/not-ready: Node is not ready. This corresponds to the NodeCondition Ready being “False”;
-
node.kubernetes.io/unreachable: Node is unreachable from the node controller. This corresponds to the NodeCondition Ready being “Unknown”.
after that, the new pod will be scheduled to other nodes, and once the unknown nodes become normal the old pod will be deleted by Kubelet which is triggered by the controller manager, also the operator can delete the Terminating pod manually in this case.
ok, is finished all? I would like to see no. lets us thinking again pod has been controller by the controller manager which divided into deployments, statefulSet, Daemonset.. so we talked above is what kind of controller? I prefer is deployments much cause for statefulSet the controller manager doesn't scheduler the new pod, the real action is to wait for the status of the old pod from Terminating to Ready, for daemonset is almost same, and the daemonset is more adapt for the hot env, more detailed info can refer to here.
4. What Next?
- [ ] For CPU/memory.. is the system resource, and if we want to define the resource by ourself how should we do?
- [ ] We have seen the priority 2000001000 of pod kube-controller-manager-chunqiu-0, how do the priority get and what's the functionality of the priority?
- [ ] What happened if the node has been added the Taints.