前面几天介绍的都是博客园的内容,今天我们切换一下,了解一下大家都感兴趣的信息,比如最近有啥电影是万众期待的?
猫眼电影是了解这些信息的好地方,在猫眼电影中有5个榜单,其中最受期待榜就是我们今天要爬取的对象。这个榜单的数据来源于猫眼电影库,按照之前30天的想看总数量从高到低排列,取前50名。
我们先看一下这个表单中包含什么内容:
【插入图片,6猫眼榜单示例】
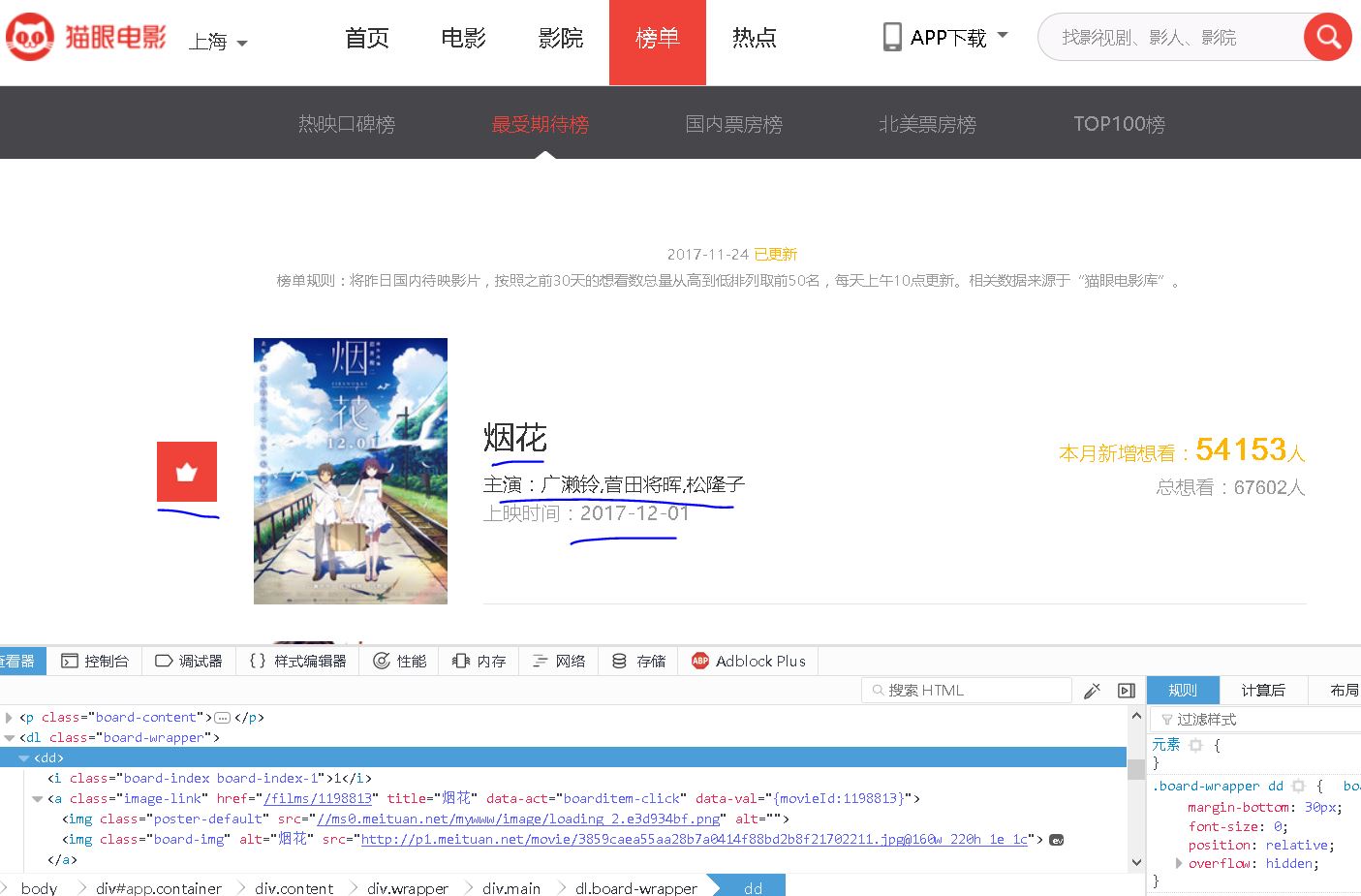
具体的信息有”排名,电影海报,电影名称,主演,上映时间“以及想看人数,今天我们主要关注前面5个信息的收集。
之前我们用正则表达式,在网页源代码中匹配了某一篇文章的标题,大家可能还有印象,这次我们还要用正则表达式来一次爬取多个内容。
另外,也尝试一下requests库。
第一步 如何获取网页的源码?
我们先分析一下这个榜单页面,跟之前博客园的大概是类似的。
url=http://maoyan.com/board/6?offset=0
上面是第一页的榜单地址,我们一眼就关注到了offset这个值,毫无疑问,后面的页面都是将offset改变就能获取到了。
来看一下第二页:
http://maoyan.com/board/6?offset=10
不一样的地方,offset每次增加了10,而不是之前博客园中的1.
无所谓,都是小case。
来来来,我们使用requests来爬一下第一页的源码看看。
import requests
#初始的代码
def get_html(url):
response=requests.get(url)
if response.status_code==200:
html=response.content.decode('utf-8')
return html
else:
return None
requests的get方法返回了一个response对象,我们根据这个response的状态码status_code就可以判断是否返回正常,200一般是OK的。
然后要对返回的内容解码,decode为utf-8的格式。
打印一下,看看得到什么结果。
【插入图片,1显示请求错误】
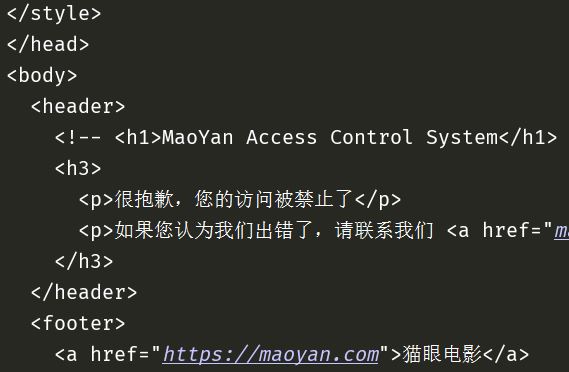
竟然失败了,被禁止访问了。
估计是猫眼设置了反爬虫,不过应该比较容易解决,我们看一下get方法的请求头信息。(在FireFox里面按F12,打开调试,点击网络,先把已经加载的内容删除,刷新一下页面,我们只看html格式的返回,如下图所示。
【插入图片,2user-agent】
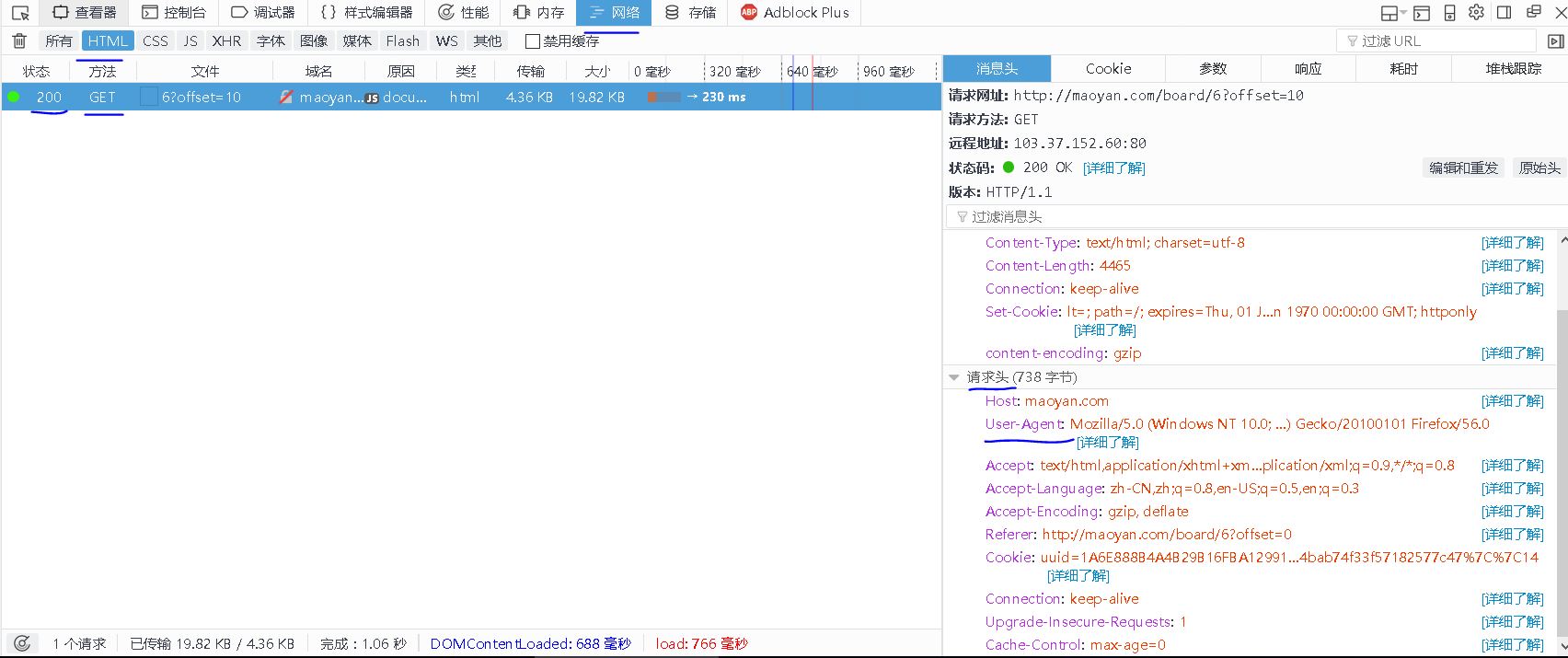
我们先给requests添加一个user-agent的头信息,尝试一下能否获取到源码信息。
import requests
#改进后的代码,插入headers
def get_html(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393'
}
response=requests.get(url,headers=headers)
if response.status_code==200:
html=response.content.decode('utf-8')
return html
else:
return None
好了,成功了,获取到了网页源码
【插入图片,获取源码成功】

第二步 解析获取的源码
得到源码后,就可以开始解析了,我们要得到的5个信息,包括排名、海报、名称、主演和上映时间等信息。
【插入图片 5某一电影标签的内容】
所有的内容包含在一个dd标签内。
我们想要用正则表达式来获取这5个信息,就要用到分组的格式,详见前面对正则表达式的介绍。
r'<dd.*?board-index.*?">(d+)</i.*?data-src="(.*?)".*?<p class="name"><a.*?>(.*?)</a>.*?<p class="star">(.*?)</p.*?class="releasetime">(.*?)</p.*?</dd>'
这个pattern有点长,我们主要关注5个()里面的内容,这就是我们要获取的5个信息。
使用re的findall方法来匹配整个源码,会得到一个list,里面有这5个内容。
但是每一页上有10个电影,假如每个电影一个item,那么我们会得到有10个item组成的一个list。
代码如下:
def parse_html(html):
#为什么一定要开启非贪婪模式?
pattern=re.compile('<dd.*?board-index.*?">(d+)</i.*?data-src="(.*?)".*?<p class="name"><a.*?>(.*?)</a>.*?<p class="star">(.*?)</p.*?class="releasetime">(.*?)</p.*?</dd>',re.S)
items=re.findall(pattern,html)
result=[]
for item in items:
result.append({
'排名':item[0],
'海报':item[1],
'名称':item[2],
'主演':item[3].strip()[3:],
'上映时间':item[4].strip()[5:]
})
return result
尤其要注意的是,.*表示可以匹配任意数量的字符,这个匹配是贪婪的,我们要在后面加上一个?才能保证匹配到第一个符合的内容就结束。
一开始没有注意,导致匹配失败很多次。
另外,由于获取主演的内容是这样的"主演:XXXXX",所以要对list切片,把前面3个字符去掉。
上映时间也是同样的道理。
这样,对一个页面的解析就完成了。
第三步 保存信息
之前我们尝试过将信息保存在文本中,今天试一下json。
因为我们要保存的内容中有中文信息,所以在写入的时候设置编码为utf-8,同时在json的dump方法中设置ascii为False。
def save_one_page(offset_no):
url=url_base+str(offset_no)
html=get_html(url)
items=parse_html(html)
for item in items:
print(item)
with open('most wanted.json','a',encoding='utf-8') as f:
json.dump(item,f,ensure_ascii=False)
第四步 开启多进程
如果想要提高运行效率,我们可以开始多进程,尤其对于这种多页、多条目的下载情况。当然我们目前的情况并不是十分要求,以备后面的情况。
Windows下,python的multiprocessing模块,提供了一个Process类来代表一个进程对象。
创建子进程时,只需要传入一个执行函数名和函数的参数,创建一个Process实例,用start()方法启动,join方法可以等待子进程结束后在继续往下运行。举个栗子:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
#target是要运行的函数名称,args是传入的参数,可以看出是一个元组,
#如果只有一个参数,后面要加一个逗号
p = Process(target=run_proc, args=('test',))
print('Process will start.')
p.start()
p.join()
print('Process end.')
如果要启动大量的子进程,可以用进程池的方式批量创建子进程,这里的进程池就是multiprocessing模块中的Pool类。
如果使用进程池的话,就不要使用start方法了,使用apply或者apply_async方法,async是
举个例子:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool()
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
根据上面的说明,我们的代码应该如下所示:
if __name__=='__main__':
pool = Pool()
for i in range(5):
pool.apply_async(save_one_page,args=(i*10,))
pool.close()
pool.join()
#map函数是python中的一种内置函数,用法后面再介绍
#pool.map(save_one_page, [i * 10 for i in range(5)])
至此为止,我们的代码就全部完成了。
附上效果图:【插入图片,结果】

未完成
但是仍然有一个内容,没有达到我的目标。
【插入图片,乱码】

【插入图片,对应数字】
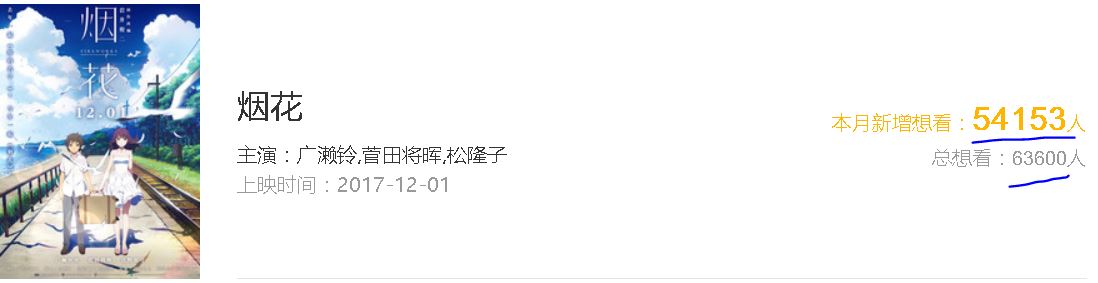
&#x格式的编码,一直没有搞清楚,否则就能得到总共想看该电影的人数了。
这个东西后面一定会解决的。
