开始之前
首先我们要安装好pyspider,可以参考上一篇文章。
从一个web页面抓取信息的过程包括:
1、找到页面上包含的URL信息,这个url包含我们想要的信息
2、通过HTTP来获取页面内容
3、从HTML中提取出信息来
4、然后找到更多的URL,回到第2步继续执行~
选择一个开始的URL
我推荐一部小说给大家《恶魔法则》。
今天我们从网上将这部小说的内容按照章节下载下来。
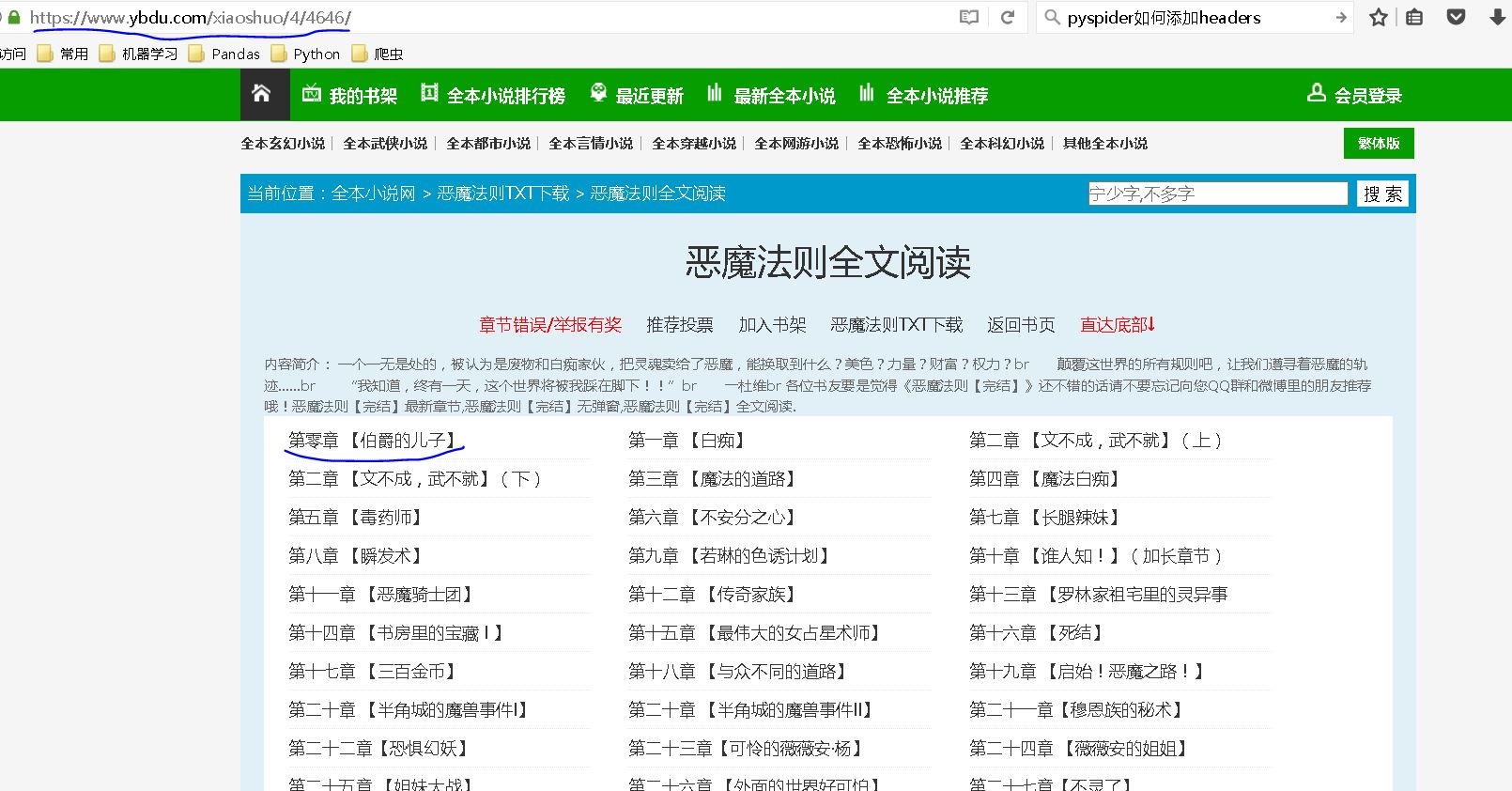
小说目录的url为https://www.ybdu.com/xiaoshuo/4/4646/
创建一个Pyspider项目
我们现在控制台命令行中输入pyspider all,命令,然后打开浏览器,输入http://localhost:5000/。
点击右面的Create按钮,输入项目名称,点击创建即可。
【插入图片,创建项目】

项目内容编辑
创建项目之后,在浏览器出现一个框架,左面是结果显示区,最主要的是一个run命令。
右面是我们输入代码的内容。由于这个代码编辑界面不太友好,建议我们将代码拷贝到pycharm中,编辑好或者修改好之后再复制回来运行。
【插入图片,空白项目内容】

我们如果访问https页面,一定要添加validate_cert=False,否则会报SSL错误。
第一步:on_start()函数
这一步主要是获取目录页。
这个方法会获取url的页面,并且调用callback方法去解析相应内容,产生一个response对象。
【插入图片,小说目录】
@every(minutes=24 * 60)
def on_start(self):
self.crawl(url, callback=self.index_page,validate_cert=False)
第二步:index_page()函数
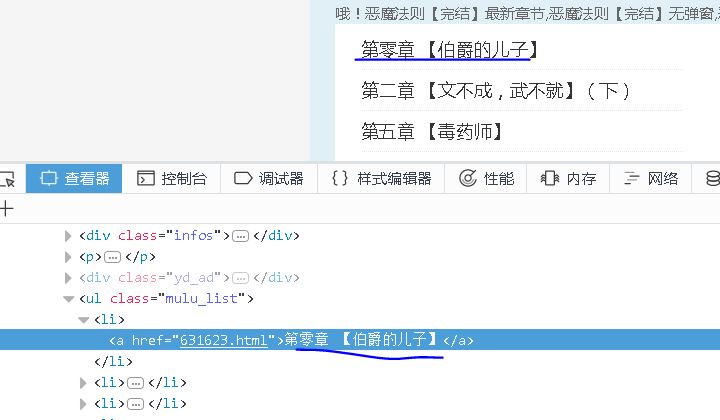
当我们第一次点击run按钮的时候,会对目录页进行解析,返回所有章节的url。
【插入图片,章节标签】
【插入图片,pyspider目录】

@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('ul[class="mulu_list"]>li>a').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
第三步:detail_page()函数
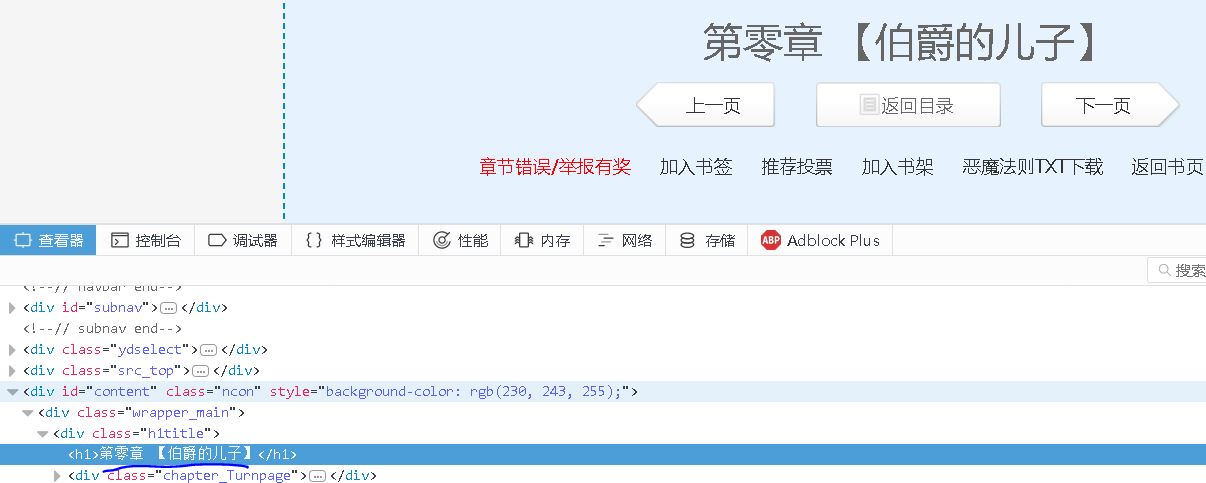
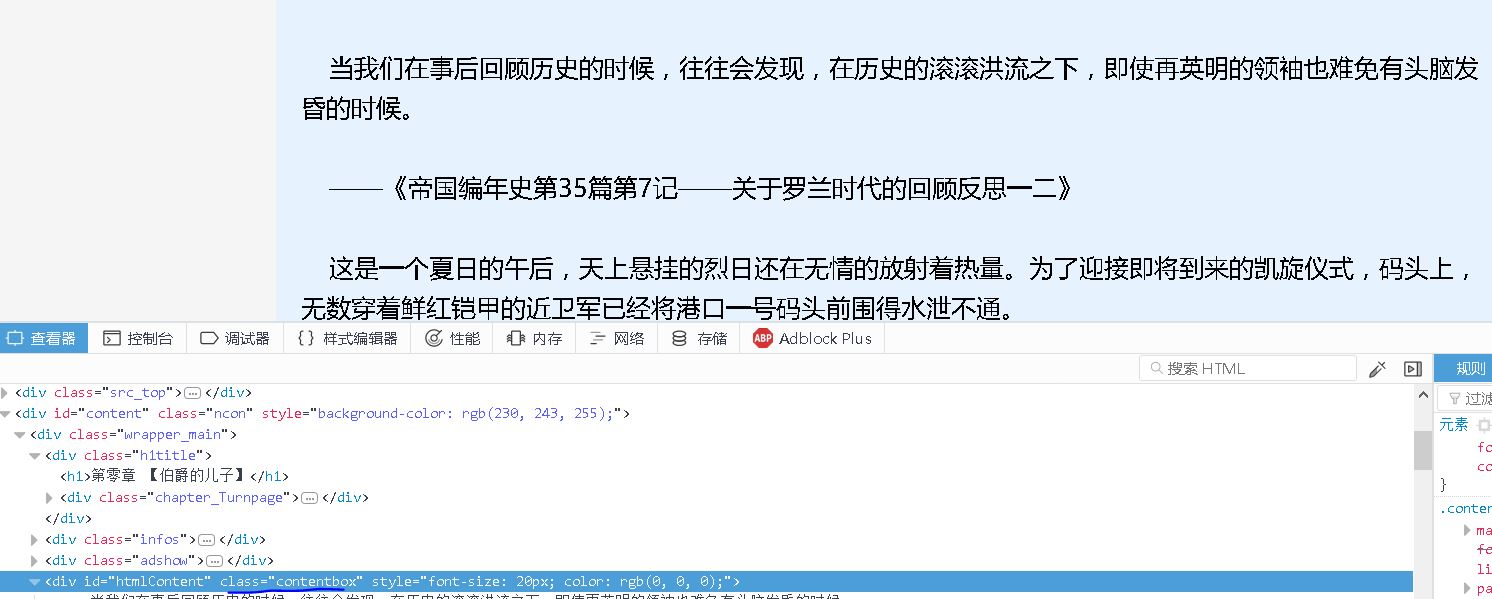
我们将分析每章节的url,获取标题和正文内容,保存成一个txt文件。
【插入图片,标题标签】
【插入图片,正文标签】
@config(priority=2)
def detail_page(self, response):
curPath = os.getcwd()
tempPath = '恶魔法则'
targetPath = curPath + os.path.sep + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
else:
print('路径已经存在!')
filename=response.doc('h1').text()+'.txt'
filePath = targetPath + os.path.sep + filename
with open(filePath, 'w',encoding='utf-8') as f:
content=response.doc('div[class="contentbox"]').text()
f.write(content)
print('写入成功!')
总结
通过以上三步,我们已经将小说的所有章节都能够保存下来。如果让项目自动运行呢?
【插入图片,开始运行】

我们回到Pyspider的控制台,将对应项目的状态调整为running或者debug,点击后面的运行,项目就能够自己动起来了。
【插入图片,结果所有章节】

所有代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-12-12 19:28:47
# Project: Nover_Fetch
import os
from pyspider.libs.base_handler import *
url='https://www.ybdu.com/xiaoshuo/4/4646/'
class Handler(BaseHandler):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
}
crawl_config = {
'headers':headers,
'timeout':1000
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl(url, callback=self.index_page,validate_cert=False)
#这个方法会获取url的页面,并且调用callback方法去解析相应内容
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('ul[class="mulu_list"]>li>a').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
@config(priority=2)
def detail_page(self, response):
curPath = os.getcwd()
tempPath = '恶魔法则'
targetPath = curPath + os.path.sep + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
else:
print('路径已经存在!')
filename=response.doc('h1').text()+'.txt'
filePath = targetPath + os.path.sep + filename
with open(filePath, 'w',encoding='utf-8') as f:
content=response.doc('div[class="contentbox"]').text()
f.write(content)
print('写入成功!')