知乎上关于 文献管理软件的总结:
http://www.zhihu.com/question/20533954
http://www.zhihu.com/question/26857521
http://www.douban.com/group/topic/45562674/
http://blog.sina.com.cn/s/blog_663d9a1f0101dhx5.html
推荐这篇链接,因为对Zotero有一个详细介绍,特别是里面对阳志平老师的链接
强烈推荐阳志平老师的链接!!!!(我以后还要认真看)
http://www.yangzhiping.com/tech/zotero1.html 网址如下。
第一篇文章有papermachines,可视化文献
http://quan7.work/2014/12/20/Zotero-1/
比较简单地(解决了我对zotfile的rename 的设置)
安装zotfile插件
- 这个插件方便对pdf文件进行命名,使云盘的storage文件夹下的文件名不会太混乱
- 点我下载最zotfile
- 打开Zotero,点击 工具->插件,在
extends选项卡中,将下载好的zotfile-4.1.xpi文件拖到选区中,提示重启完成安装 - 配置:
- 主界面->工具->插件-》Extensions中找到zotfile,点击options.
- General Settings→Location of Files中,将网盘下的某目录填入Custom Location中,并根据需要勾选subfolder和填写附件整理规则,如/%y或者/%w/%y.这样所有的PDF文件会按年份归类到各子文件夹中。
- Advanced settings—>Other Advanced Settings中,将Autoatically rename new attachments 选成Always rename,这样就可以实现每次自动下载好PDF之后就自动重命名文件且归类到指定的子目录中。
即:
zotfile Preference→General Settings→Location of Files中,将网盘下的某目录填入Custom Location中,并根据需要勾选subfolder和填写附件整理规则,如/%y,这样所有的PDF文件会按年份归类到各子文件夹中。
zotfile Preference-->Advanced settings-->Other Advanced Settings中,将Autoatically rename new attachments 选成Always rename,这样就可以实现每次自动下载好PDF之后就自动重命名文件且归类到指定的子目录中。
http://blog.liang2.tw/posts/2015/09/ref-management-zotero/
这篇文章对我的影响蛮大的,直接让我开始使用BibDesk+Zotero+Zotfile+sufdrive(高校免费)
实验了一下,在使用chrome Zotero 插件下载文件的时候,需要启动Zotero standalone 才能使用Zotfile。 否则,即使后面打开Zotero standalone,虽然仍然有该记录,但是是网页同步的结果,不是本地下载的结果。该PDF不会出现在zotfile定义的文件夹中。
关于 linked attachment Base directory 和 Data Directory Location的区别
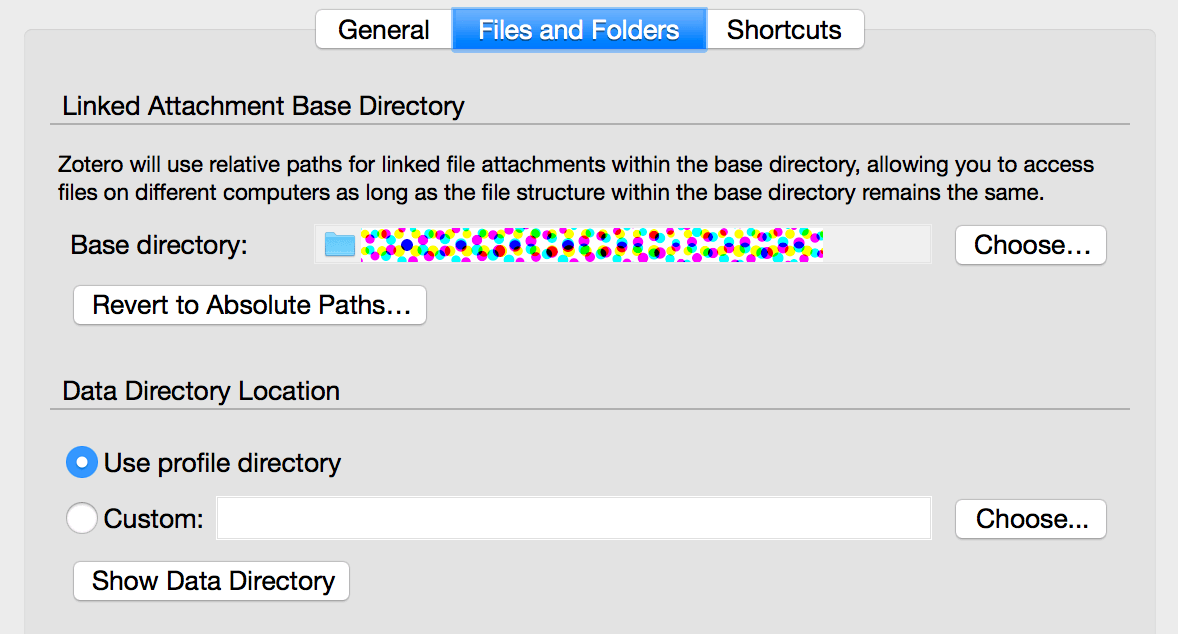
這邊要額外說明一下 Linked Attachment Base Directory 以及 Data Directory 的差異。像 PDF 這類如果被 Zotfile 所管理的檔案,或是自己手動選「Attach Link …」的檔案,他使用的是 linked attachment,icon 會有個連結的符號  。其他像 Webpage Snapshot 或是預設的 PDF 檔都是放在 Data Directory。
。其他像 Webpage Snapshot 或是預設的 PDF 檔都是放在 Data Directory。
http://emuch.net/html/201410/7981977.html
关于Zotfile的介绍 (和软连接相比,好处,可以自动命名文件并分类,即使不适用zotero访问也可以直接访问文件夹)
首先解释一下为何要便用zotfile插件。
如前文所提,为了不占用zotero服务器上的300M空间,我们需要对storage文件夹做点手脚但同时保持PDF与文献之间的关联。有一种流行的做法是使用“软链接”,让storage文件夹本质上是一个链接,而链接的源头是网盘下的某个目录,即玩儿狸猫换太子的把戏,无论你存了多少PDF,其实都只存在了网盘的目录中,而storage永远只是一个链接文件,文件大小可以忽略不计,自然就不会增加zotero服务器上的300M空间了。这样做确实可以实现database与files的分离,但是不知道为什么,原生zotero会默认在storage文件夹下将附件保存在以杂乱符号为名的子文件夹中,不便于查看和整理,而且没有办法让用户修改。这样就会造成,当你脱离zotero软件去访问网盘文件夹时,PDF都被存于一个个名字像乱码一样的文件夹中,让你无从寻找想要的文件。
zotfile这款小插件就正好能一举两得地既能实现database与files的分离,又能自定义storage下的文件保存样式,比如以年份为文件夹名归类各PDF。
下面说说如何设置zotfile:
1. 在FireFox扩展应用下载zotfile,若需要使用standalone版的软件,则需要下载和安装zotfile的安装文件(https://github.com/jlegewie/zotfile/releases)
2. zotfile Preference→General Settings→Location of Files中,将网盘下的某目录填入Custom Location中,并根据需要勾选subfolder和填写附件整理规则,如/%y,这样所有的PDF文件会按年份归类到各子文件夹中。
3. zotero Prefernce-->Advanced-->Linked Attachment Base Directory中,填入网盘中的目录,和zotfile中的custom location一致
上面3的目的是:如果是同步到 Dropbox 的話,可能每台電腦的路徑都不一樣,例如 OSX可能是 /Users/me/Dropbox,但 Debian 可能是 /home/me/Dropbox,這時候存放的路徑就要改成相對路徑
软连接的方式:
Zotero的数据文件可以分为两个部分,一个是存放便签、笔记等的数据文件,一个是存放原始pdf文献文件的附件,后者存放在Storage文件夹里。文献多时,Storage的体积会变得很大。高手的解决方案是,将Zotero同步文件夹下的storage文件夹变成一个超链接,链接到另一个真实存放pdf文献资料的文件夹。这样,Zotero同步文件夹下的Storage文件夹就成了一个链接,从而同步到云上的数据大大减小。同时,Zotero中的笔记等又可以通过该超链接链接到真实的存放文献资料的地方。而真实存放资料的地方,可以通过百度云、金山快盘等云端进行实时更新。但经过比较,个人选择了使用Dropbox,因此我尝试了一下几个的更新速度,Dropbox云端的更新速度是最快的,最快时曾经达到震惊的800 KB/s。
http://swordi.com/2013/04/24/zotero/
阳志平老师的关于Zotero的介绍,非常详细,推荐
http://libzx.so/chn/2015/01/03/use-zotero-to-organize-knowledge.html
zotero 的用户数据一般来说包括几个主要部分:
- 系统自己的配置,如首选项设置的保存文件
- 用户的文献库的索引和结构等数据,保存在用户文件夹里
- 用户所有嵌入的 PDF 全文等文件,存放再上面的用户文件夹下的 storage 文件夹中
同步方式:
1、软连接
2、Zotero的webdev
3、zotfile插件
zotero 同步设置
zotero 有 sync 功能,可以同步上述2、3两个文件夹。注册一个官网帐号,然后到 Preference - Sync - Settings 中填上即可。
但是我们一般不希望 zotero 将上述3类 storage 文件夹也做同步。因为大量的 PDF 文件应该很大,而且 zotero 也没有那么大的云空间,于是我们就有两种处理方式了。
一种方法是,关闭 zotero 对附加文件夹的同步:回到上述 Sync - Settings 中取消下面的打勾。然后我们另外使用其他国内的云盘,如百度云、坚果云等,将对应的 storage 文件夹纳入同步就可以了。
在 *nix 系统下面有一个 trick,即可以将 storage 文件夹删除,用一个 symbolic link 来替代它,这样我们还可以进一步地自定义 storage 文件夹的位置和名称,也照顾了云盘的使用、方便管理。
当然,如果在多台电脑同步,那就在多台电脑上都需要对云盘做类似设置。
另一种方法是,使用 zotero 的 WebDAV 方式同步。只需提供其他支持 WebDAV 的网盘即可,如坚果云,在坚果云后台 “设置” - “安全” 中可以看到 WebDAV 的路径,甚至可以设置一个单独密码,以便不用暴露坚果云的密码到 zotero 中。
我们回到 zotero 中 Preference - Sync - Settings 下面下拉框中将 “Zotero” 改成 “WebDAV”,然后选默认 https,再填 “dav.jianguoyun.com/dav” 到后面的框中。下面的用户名是坚果云的邮箱名,密码是坚果云的密码或者独立密码。使用 Verify Server 功能可以验证是否成功。
这样之后,zotero 会在坚果云账户里建立一个 zotero 的子文件夹(放心,不会包含URL路径的dav字样)。所有的 storage 内容就会放到这里了,并且云盘上存的是经过压缩后的,而不像本地一样是原始 PDF,不会占用太多云盘上的空间。同时,在坚果云客户端中可以关闭对此文件夹的同步,因为我们并不关心此文件夹的结构和内容,它就是一个给 zotero 专用的区域。
官方也有一些同步的建议: https://www.zotero.org/support/sync
http://sealhuang.github.io/zotero/
对于zotfile的使用介绍比较详细(包括安装)
zotfile 官网 http://zotfile.com/
http://blog.yesmryang.net/zotero-usage/
有详细介绍
就说这么多,开始认真干活!!!!