交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
1. 二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越大。比如投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理,我们希望:ANN在训练时,如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。然而,如果使用二次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同的样本数据x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的代价(误差):
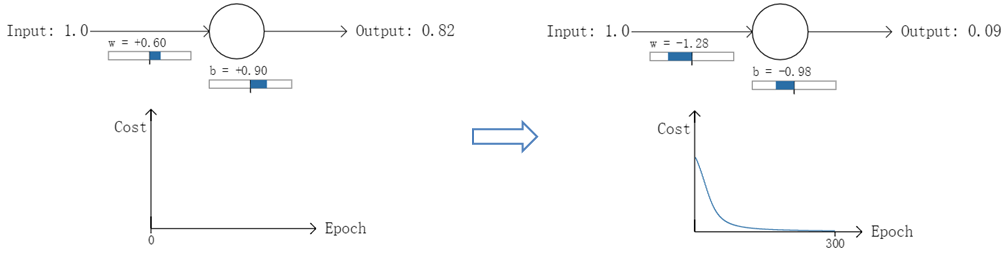
实验1:第一次输出值为0.82

实验2:第一次输出值为0.98
在实验1中,随机初始化参数,使得第一次输出值为0.82(该样本对应的实际值为0);经过300次迭代训练后,输出值由0.82降到0.09,逼近实际值。而在实验2中,第一次输出值为0.98,同样经过300迭代训练,输出值只降到了0.20。
从两次实验的代价曲线中可以看出:实验1的代价随着训练次数增加而快速降低,但实验2的代价在一开始下降得非常缓慢;直观上看,初始的误差越大,收敛得越缓慢。
其实,误差大导致训练缓慢的原因在于使用了二次代价函数。



如图所示,实验2的初始输出值(0.98)对应的梯度明显小于实验1的输出值(0.82),因此实验2的参数梯度下降得比实验1慢。这就是初始的代价(误差)越大,导致训练越慢的原因。与我们的期望不符,即:不能像人一样,错误越大,改正的幅度越大,从而学习得越快。
可能有人会说,那就选择一个梯度不变化或变化不明显的激活函数不就解决问题了吗?图样图森破,那样虽然简单粗暴地解决了这个问题,但可能会引起其他更多更麻烦的问题。而且,类似sigmoid这样的函数(比如tanh函数)有很多优点,非常适合用来做激活函数,具体请自行google之。



利用交叉熵去验证上面的程序:
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 载入数据集 mnist = input_data.read_data_sets("MNIST_data", one_hot=True) # 每个批次的大小 batch_size = 100 # 计算一共有多少个批次 n_batch = mnist.train.num_examples // batch_size # 定义两个placeholder x = tf.placeholder(tf.float32, [None, 784]) y = tf.placeholder(tf.float32, [None, 10]) # 创建一个简单的神经网络 W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) prediction = tf.nn.softmax(tf.matmul(x, W) + b) # 二次代价函数 # loss = tf.reduce_mean(tf.square(y - prediction)) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=prediction)) # 使用梯度下降法 train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) # 初始化变量 init = tf.global_variables_initializer() # 结果存放在一个布尔型列表中 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1)) # argmax返回一维张量中最大的值所在的位置 # 求准确率 # 把布尔类型转化成0和1类型,true是1,false是0 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) with tf.Session() as sess: sess.run(init) for epoch in range(21): for batch in range(n_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys}) acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}) print("Iter " + str(epoch) + ",Testing Accuracy " + str(acc))
