MongoDB最基础的东西,我这边就不多说了,这提供罗兄三篇给大家热身
最后对上述内容和关系型数据做个对比
- 非关系型数据库的优势
- 性能 --NoSQL是基于键值对的,不需要经过SQL层的解析,所以性能非常高
- 可扩展性 --因为基本键值对的,数据之间没有耦合性,所以非常容易水平扩展
- 关系型数据库的优势
- 复杂查询 --可以进行多表复杂查询
- 事务支持 --要求安全性高的数据访问得以实现
1.高级查询命令
条件查询
1.1 大于 小于
- $gt 大于 实例:db.singer.find({"age":{$gt : 50}})
- $lt 小于 实例:db.singer.find({"age":{$lt : 30}})
- $gte 大于等于 实例:db.singer.find({"age":{$gte : 50}})
- $lte 小于等于 实例:db.singer.find({"age":{$lte : 30}})
1.2 选择区间
- db.集合名.find({"键名":{$gt:值1,$lt:值2}}) 实例:db.singer.find({"age":{$gte:30, $lt:40}})
1.3 不等于
- $ne 不等于 实例:db,singer.find({"country":{$ne:''china"}})
1.4 in和not in
- $in 在集合中 实例:db.singer.find({"num":{$in:["值1","值2"]}})
- $nin 不在集合中 实例:db.singer.find({"num":{$nin:["值1","值2"]}})
1.5 数组个数
- $size 值的个数 实例:db.singer.find({"works":{$size:3}})
1.6 是否存在
- $exists 是否存在某个键名(true|false) 实例:db.singer.find({'height':{$exists:true}})
1.7 或
- $or 或者,多个条件满足一个就行了 实例:db.singer.find({$or:[{'name':'laoliu'},{'sex':'女'}]})
1.8 模糊查询
- db.集合.find('键':值) 值必须是正则表达式(js正则) 实例:db.singer.find({"name":/刘/})
排序
- db.集合名.find().sort({"键名1":1, "键名2": -1}) 1为升序,-1为降序
限制输出
- limit(n) 实例:db.singer.find().sort({"age":1}).limit(3)
select * from singer order by age asc limit 3
- skip(n) 实例:db.singer.find().sort({"age":1}).skip(3).limit(2)
select * from singer order by age asc limit 3,2
2.聚合 aggregate
聚合主要用于计算数据,类似sql中的sum()、avg()
语法:db.集合名称.aggregate( [{管道:{表达式}}] )
管道:管道一般用于将当前命令的输出结果作为下一个命令的输入,在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
表达式:处理输入文档并输出
2.1 常用表达式
- $sum:计算总和,$sum:1同count表示计数
- $avg:计算平均值
- $min:获取最小值
- $max:获取最大值
- $push:在结果文档中插入值到一个数组中
- $first:根据资源文档的排序获取第一个文档数据
- $last:根据资源文档的排序获取最后一个文档数据
2.2 聚合示例
- $group 语法:db.集合.aggregate( {$group:{_id:'$字段', $表达式: '$字段'} ) 分组统计结果,_id为分组依据,后跟分组字段
db.singer.aggregate({
$group : {
_id:null, //为null表示不分组
总人数:{$sum:1},
平均年龄:{$avg:'$age'}
}
});
db.singer.aggregate({
$group : {
_id:'$sex',
名单:{$push:'$name'} //name对应的值为数组
}
});
- $match 管道,匹配条件
//满足大于40 并且按性别分组
db.singer.aggregate([
{
$match:{"age":{$gt:40}}
},
{
$group : {
_id:'$sex',
总人数:{$sum:1},
平均年龄:{$avg:'$age'}
}
}
])
- $project 是否显示某个字段
db.singer.aggregate([
{$match:{"age":{$gt:50}}},
{$project:{_id:0,name:1}}//显示name,不显示_id
])
- $sort 排序管道
db.singer.aggregate([
{$match:{"age":{$gt:50}}},
{$project:{_id:0,name:1}},//显示name,不显示_id
{$sort:{'age':1}}
])
- $limit 限制多少条 $skip 跳过多少条
db.singer.aggregate([
{$match:{"age":{$gt:50}}},
{$project:{_id:0,name:1}},//显示name,不显示_id
{$sort:{'age':1}},
{$skip:2},
{$limit:3}
])
- $unwind 将数组字段进行拆分,然后分成多个document
db.singer.aggregate([
{$match:{"age":{$gt:50}}},
{$unwind:'$works'}
])
3.安全
1.进入管理平台,首先以无密码形式登陆
2.创建管理员密码
- 默认没有admin数据库,可以自己添加一个 use admin
- 添加好数据库以后可以使用命令添加账户,新增的管理员账号会在system.user集合中,类似mysql的user表
db.createUser({user:"admin",pwd:"password", roles:["root"]})
3.验证密码 db.auth('admin':'password')
4.重新挂载服务(卸载之前的服务,sc delete mongodb) --auth 带上验证
mongod --dbpath d:mongodbdb --logpath d:mongodblogMongoDB.log --install --serviceName "MongoDB" --auth
5.测试密码是否生效
use admin;
show collections; //无法查看,就说生效了
//验证密码, 必须进入到让你生效的数据库进行验证
db.auth('admin','password');
//再次查看
show collections; //正常显示说明权限生效
6.为其他数据库添加用户
//先通过身份验证 再进入指定数据库,添加用户
use app1;
db.createUser({user:"app1",pwd:'123456',roles:[{role:'dbOwner',db:'app1']}})
4.主从复制
4.1 什么是复制
复制提供了数据的longyu备份,并在多个服务器上存储数据副本,提高了数据的可用性,并可以保证数据安全性,复制还允许从硬件故障和服务中断中恢复数据
4.2 为什么复制
- 数据备份
- 数据灾难恢复
- 读写分离
- 高(24*7)数据可用性
- 无宕机维护
- 副本集对应程程序是透明
4.3 复制的工作原理
- 复制至少需要两个节点A,B...
- A是主节点,负责处理客户端请求
- 其他都是从节点,负责复制主节点上的数据
- 节点常见的搭配方式:一主一从,一主多从
- 主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据和主节点的一致
- 主节点与从节点进行数据交互保障数据的一致性
4.4 复制的特点
- N个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
4.5 设置复制节点
开始前,最好把之前的MongoDB服务停掉
(1) 创建数据库目录t1、t2 用于挂起两个MongoDB服务
(2) 使用如下格式启动mongod,注意replSet的名称一致的,你可以理解成同一集群下
- mongod --bind_ip 192.168.0.104 --port 27017 --dbpath d:mongodb 1 --replSet rs0
- mongod --bind_ip 192.168.0.104 --port 27017 --dbpath d:mongodb 2 --replSet rs0
(3) 连接主服务器,假如就设置192.168.0.104:27017 设置为主服务器
- mongo --host 192.168.0.104 --port 27017
(4) 初始化 rs.initiate()
(5) 查看当前服务器主从状态 rs.status()
(6) 添加副本集,也就是指定从服务器 rs.add("192.168.0.104:27018")
(7)查看添加的从服务器主从状态 rs.status()
(8) 连接从服务器,查看提示符
- mongo --host 192.168.0.104 --port 27018
(9) 向主服务插入数据
- db.users.insert({'name':'laoliu'})
(10) 在从服务器上查询 需要注意的是:在从服务器上进行读操作,需要设置rs.slaveOk()
- db.users.find()
4.6 其他说明
- 删除从节点 rs.remove("192.168.0.104:27018")
- 关闭主服务器后,再重新启动,会发现原来的从服务器变成了主服务器,新启动的服务器(原来的主服务器)变成了从服务器
5.备份与恢复
5.1 整库备份
语法:mongodump -h dbhost -d dbname -o dbdirectory
- -h:服务器地址,也可以指定端口号
- -d:需要备份的数据库名称
- -o:备份的数据存储位置,此目录中存放着备份出来的数据
比如: mongodump -h 127.0.0.1:27017 -d itsource -o d:output
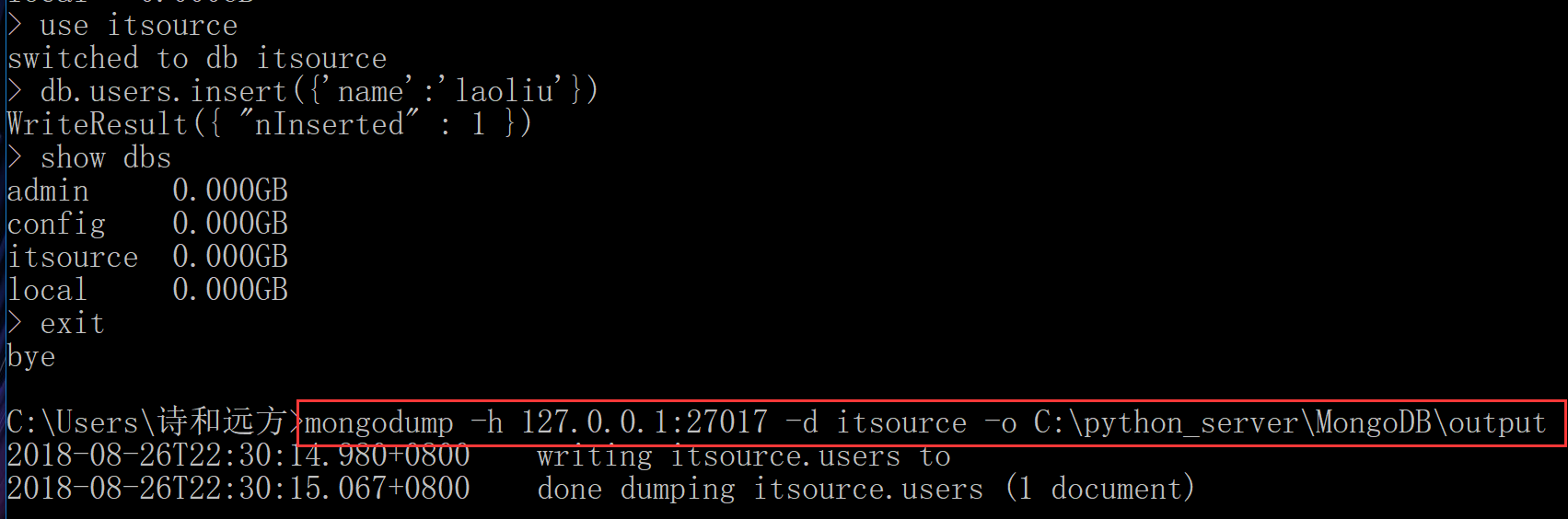
5.2 单个collection备份
语法:mongoexport -h dbhost -d dbname -c collectionname -f collectionKey -o dbdirectory
- -h: MongoDB所在服务器地址
- -d: 需要恢复的数据库实例
- -c: 需要恢复的集合
- -f: 需要导出的字段(省略为所有字段)
- -o: 表示导出的文件名

5.3 整库恢复
语法:mongorestore -h dbhost -d dbname --dir dbdirectory
- -h:服务器地址
- -d:需要恢复的数据库实例
- --dir:备份数据所在的位置
比如:mongorestore -h 127.0.0.1:27017 -d itsource2 d:mongodbitsource
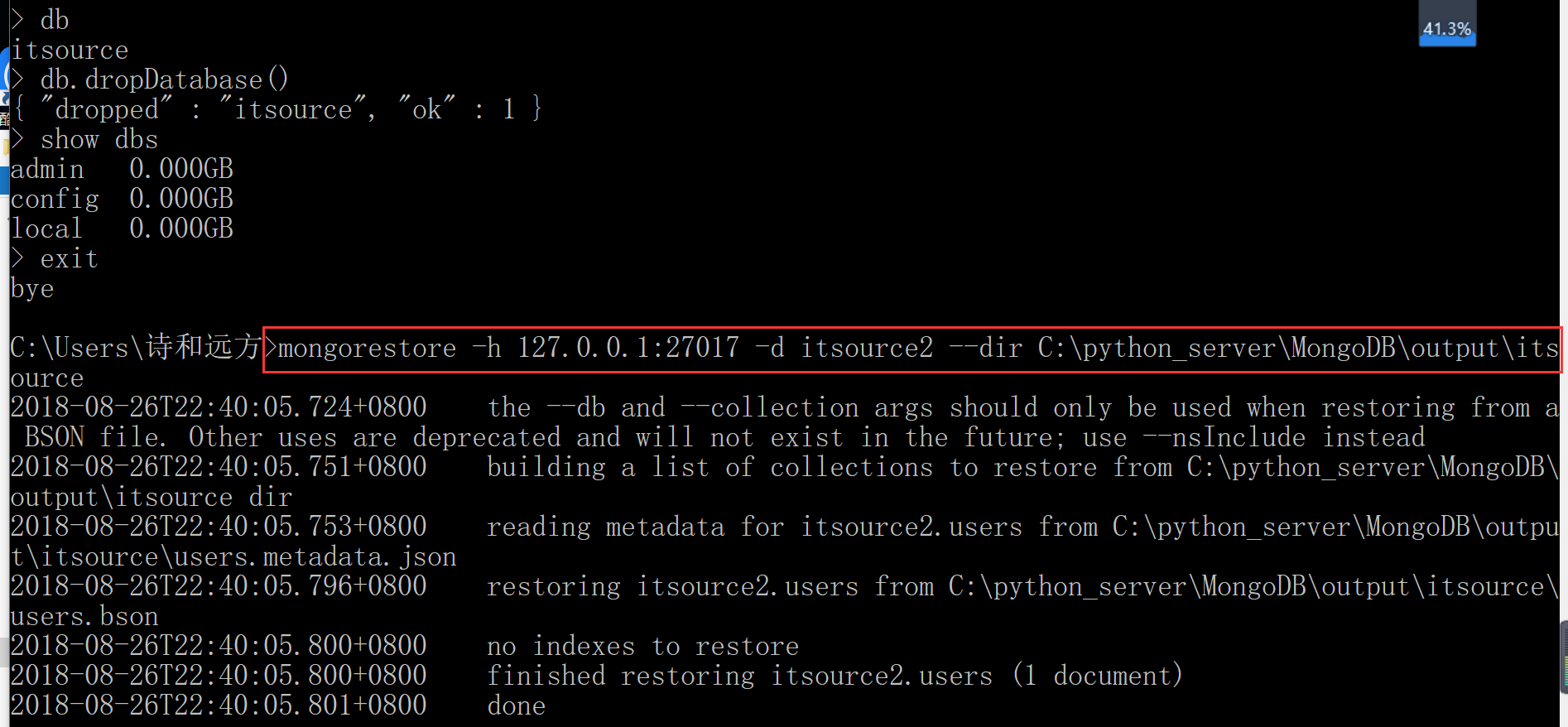

5.4 单个collection恢复
语法:mongoimport -d dbhost -c collectionname --type csv --headerline --file
- -type: 指明要导入的文件格式,默认json
- -headerline: 批明不导入第一行,因为第一行是列名,在csv格式和TSV可用
- -file: 指明要导入的文件路径

6.python操作MongoDB
安装 pip install pymongo
import pymongo
import settings
import copy
import time
import threading
from view_info import view_used_info
event_obj = threading.Event()
amount = 10000000 if settings.AMOUNT == '千万' else 1000000
def warpper(func):
def inner(*args, **kwargs):
func_name = func.__name__
print('execute %s ......'%func_name)
with open('operation_%s.log'%amount, 'a') as f:
f.write('[operation]%s
'%func_name)
view_used_info('before', func_name)
event_obj.set()
start_time = time.time()
print('start_time',start_time)
f.write('[**start_time]%s
'%start_time)
func(*args, **kwargs)
end_time = time.time()
print('end_time',end_time)
f.write('[**end_time]%s
' % end_time)
event_obj.clear()
view_used_info('after', func_name)
print('spend_time', end_time-start_time)
f.write('[**spend_time]%s
'%(end_time-start_time))
f.write('='*50 + '
')
return inner
class DbConnection:
def __init__(self):
self.client = pymongo.MongoClient(settings.MONGODB_HOST, settings.MONGODB_PORT) #127.0.0.1 27017
self.db = self.client[settings.TEST_DB] #"test"
self.coll = self.db[settings.TEST_COLLECTION] #user
@warpper
def init_env(self, amount):
insert_data = []
for i in range(amount):
tmp = copy.deepcopy(settings.DOCUMENT_TEMPLATE)
tmp['uid'] = i
insert_data.append(tmp)
self.coll.insert_many(insert_data)
@warpper
def insert_one(self):
tmp = copy.deepcopy(settings.DOCUMENT_TEMPLATE)
tmp['uid'] = -1
self.coll.insert_one(tmp)
@warpper
def insert_many(self):
insert_data = []
for i in range(5):
tmp = copy.deepcopy(settings.DOCUMENT_TEMPLATE)
tmp['uid'] = -2
insert_data.append(tmp)
self.coll.insert_many(insert_data)
@warpper
def insert_10000(self):
insert_data = []
for i in range(10000):
tmp = copy.deepcopy(settings.DOCUMENT_TEMPLATE)
tmp['uid'] = i - 100000
insert_data.append(tmp)
self.coll.insert_many(insert_data)
@warpper
def find_one(self):
self.coll.find_one({'uid':-1})
@warpper
def find_many(self):
self.coll.find({'uid':-2})
@warpper
def update_one(self):
self.coll.update_one({'uid': -1}, {'$set': {'log_operation': 'p'*100}})
@warpper
def update_many(self):
self.coll.update_many({'uid': -2}, {'$set': {'log_operation': 'p'*100}})
@warpper
def delete_one(self):
self.coll.delete_one({'uid':-1})
@warpper
def delete_many(self):
self.coll.delete_many({'uid': -2})
@warpper
def drop(self):
self.coll.drop()