获取高德和百度地图的POI及边界数据爬虫-JAVA版本
做了什么
- 合理的利用高德地图或者百度地图的API开发者key,对地图上的POI数据进行获取,方便数据统计与整理分析
- 结合百度和高德的API,可以获取到地点的关联信息以及大部分的数据边界信息,并进行了坐标转换
- 对于数据可以进行分级操作,包括区分出地市、区县、乡镇/街道、小区/工业园区/商务楼宇、楼栋等层级
如何使用
在 com.accright.plugins.spider.utils.DBFactory 中配置好数据库与驱动,运行com.accright.plugins.spider.amap.main.CitySpider即可运行地市获取,运行com.accright.plugins.spider.amap.main.AmapSpider即可获取所有的POI数据及大部分的边界信息。运行com.accright.plugins.spider.amap.main.AddressManager即可进行数据的按照级别分割并入库,级别包括地市、区县、乡镇/街道、路、门牌号、小区/工业园区/商务楼宇、楼栋七级,可以通过修改配置的方式来决定保存哪几种分类和哪几个级别。 数据库模型及字段请按照SQL进行创建和整理,目前适用于Oracle,稍加改造即可适用于MySQL
原理及使用
流程总述
简介
该文档主要介绍了通过爬取高德地图和百度地图等互联网地址数据,包括地址坐标、边界范围、地址详情、地址名称和地址类型等,经过去重和正则表达式分割,建立地址之间的层级关系,从而形成标准地址,录入标准地址库等流程。
流程综述
- 高德数据爬取:通过高德地图提供的API接口,根据类型和分块经纬度范围爬取高德的地址信息数据
- 百度数据爬取:根据高德API查询的地址名称,模糊匹配百度地图搜索数据,通过该数据获取地址范围和标准六级地址分割等信息
- 数据结果去重:对地址中查询出的高德或百度ID相同的数据进行去重
- 建立地址关系:对查询出来的标准六级地址数据分割为标准地址前六级
- 标准地址入库:将已建立关联关系的标准地址插入数据库
流程详解
高德数据爬取
功能描述
高德数据爬取是根据高德地图提供的多边形查询 API,使用 Http 请求获取 JSON 数据并解 析,其请求的参数主要如下:
| 参数名 | 含义 | 规则说明 | 是否必填 | 缺省值 |
|---|---|---|---|---|
| key | 请求服务权限标识 | 用户在高德地图官网申请 Web服务API类型KEY | 必填 | 无 |
| polygon | 经纬度坐标对 | 规则:经度和纬度用","分割,经度在前,纬 度在后,坐标对用竖线分割。经纬度小数点后 不得超过 6 位。 多边形为矩形时,可 传入左上右下两顶点坐标对;其他情况下首 尾坐标对需相同。 | 必填 | 无 |
| keywords | 查询关键字 | 规则: 多个关键字用竖线分割 | 可选 | 无 |
| types | 查询POI类型 | 可选值:分类代码或汉字(若用汉字,请 严格按照附件之中的汉字填写) 分类代码由六位数字组成,一共分为三个部分,前两个数字代表大类;中间两个数字代 表中类;最后两个数字代表小类。 若指定了某个大类,则所属的中类、小类都 会被显示。例如:010000 为汽车服务(大类)010100 为加油站(中类) 010101 为中国石化(小类)010900 为汽车租赁(中类) 010901 为汽车租赁还车(小类) 当指定 010000,则 010100 等中类、010101 等小类都会被包含。当指定 010900,则 010901 等小类都会被包 含载 POI 分类编码和城市编码表当 keywords 和 types 为空的时候, 我们会 默认指定 types 为 120000(商务住宅)&15 0000(交通设施服务) | 可选 | 无 |
| offset | 每页记录数据 | 用户在高德地图官网申请 Web 服务 API 类 型 KEY | 可选 | 20 |
| page | 当前页数 | 最大翻页数 100 | 可选 | 1 |
| extensions | 返回结果控制 | 此项默认返回基本地址信息;取值为all返回地址信息、附近POI、道路以及道路交叉口信息。 | 可选 | base |
| output | 返回数据 | 可选值:JSON,XML | 可选 | JSON |
由于高德地图有数据保护,每次返回数据不会超过 1000 条,实际上最多到 900 条左右便不 会再返回数据,而且数据超过 300 条有极大概率出现翻页不准确的问题,所以需要严格划分 查询的区块,然后如果区块内的数据超过 200 条,则进行递归查询,将区块一分为四,保证 每个区块内的数据不会超过 200 条。其中的类型参数,使用 | 分割,根据高德地图 POI 分 类列表,采用多线程的方式进行获取。其获取的数据字段主要有:
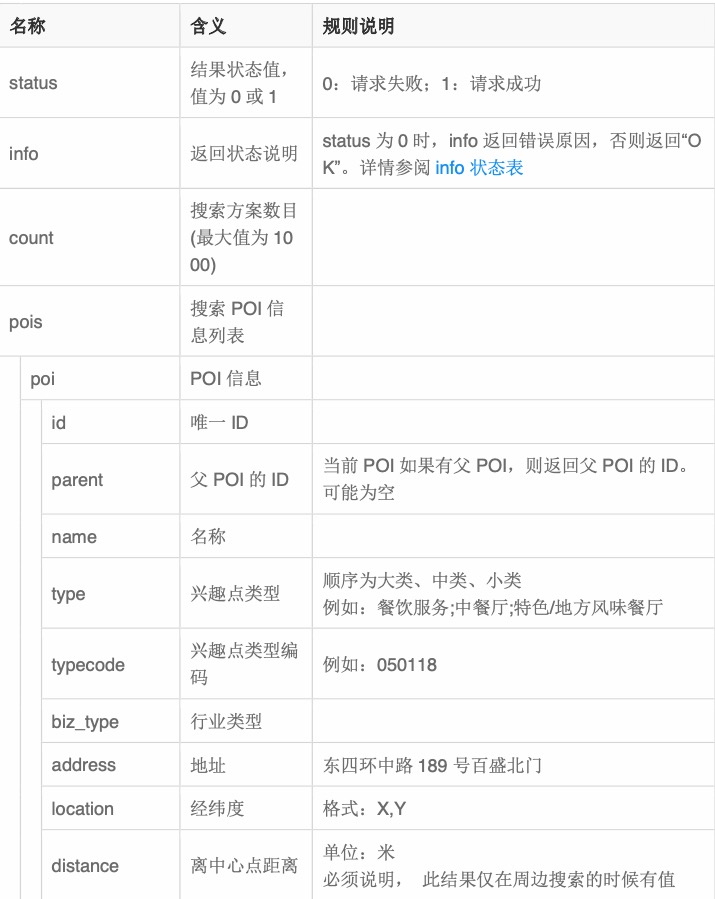
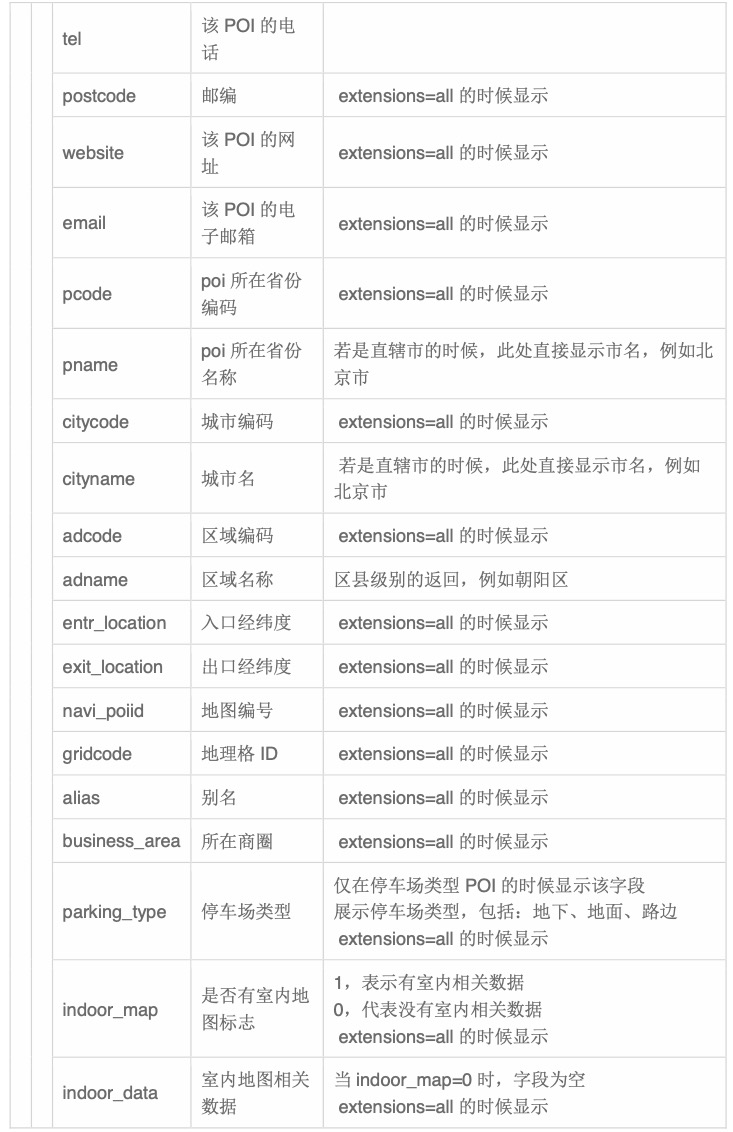

将获取的以上字段中的 id,parent,name,types,location,cityname,adname,address 存入数据库,以 上信息不包括边界数据,而高德的边界数据请求有破解难度非常高的反爬虫机制,因此地址 的边界数据需要通过高德地图的名称模糊匹配百度地图的数据,从而获取百度米制坐标系的 边界信息数据。
关键功能点及解决办法
地图数据数量爬取限制
高德地图数据爬取最多返回1000条,实际每次请求如果超过 300 条便会发生分页异常,咨询高德客服表明这是一个bug,也是为了处于数据保护考虑,因此对于大的区域,例 如地市和省份需要进行画区块分割的方式进行范围查询,同时对于每个区块,如果数据 超过 200 条,再次进行递归分割,其示例图如下:

由于 200 条数据会导致查询数量增多,速度变慢,因此对于不同的分类,采用多线程的方式进行查询。
递归次数过多导致StackOverFlow
如果选取的范围太大,多次递归会导致StackOverFLow,因此对于大区域,需要先进行区块分割,然后再进行递归查询。
百度数据爬取
功能描述
为了解决高德地图查询的数据没有边界信息和地址分割信息的问题,通过高德地图查询的数据名称模糊匹配百度地图查询的数据,然后根据百度地图查询的数据获取地址的边界信息和 地址分割数据,其中边界信息是采用的百度米制坐标的数据,需要进行坐标转换将其转换为 火星坐标系的点坐标,获取的地址信息则需要通过正则表达式分割之后存入临时表。百度地 图没有提供现成的 API 做边界查询使用,通过抓包获取到可以查询边界信息的地址为: https://api.map.baidu.com/?qt=s&c=288&wd=%E6%B5%AA%E6%BD%AE%E7%A7%91%E6%8A%80%E5%9B %AD&rn=10&ie=utf- 8&oue=1&fromproduct=jsapi&res=api&callback=BMap._rd._cbk48424&ak=8QiGVpCMtmzYxWSeYC MhzQvmjH8laVql 其中 wd 参数即为模糊查询的关键字参数,c参数即为地市参数,贵阳市的参数为146 callback 参数可以为空。返回的数据为 str 数据,需要解析为 JSONObject 数据进行解析,其 返回的数据列表字段位为:

将以上数据存入数据库,用于后续的去重及筛选操作。
关键功能点及解决办法
一条高德数据对应多条百度数据:因为查询百度的数据是根据模糊匹配的,所以查询的数据会出现多条,默认第一条是最 准确的数据,因此如果一条高德数据对应多条百度数据,取百度的第一条数据为准。
在百度地图中查询不出数据:如果在百度地图中查询不出数据,说明在百度中没有该点数据,则该点数据不保存百度 的地址信息,直接存入数据库。由于该接口不是百度地图的标准接口,所以可能存在部分地址更新不全的问题,这个问题需要在后续通过抓包找出更适合的链接来替换。
地址分割方法:百度地址查询出来的地址信息比较多,且可以进行正则表达式的分割,其主要的地址类 型有以下几种:
-
比较标准的地址数据,分为省、市、区、街道或路、门牌号,示例如下: [ 贵 州 省 (520000)|PROV|0|][ 贵 阳 市 (520100)|CITY|1|][ 南 明 区 (520102)|AREA|1|][花果园大街()|ROAD|1|1 号$]
-
比较标准但是无门牌号的数据,示例如下: [贵州省(520000)|PROV|1|][贵阳市(520100)|CITY|1|][乌当区(520112)|AREA|1|] 新添寨[新添大道北段()|ROAD|1|]仁恒别墅
-
带有附加地址的数据,例如某某公园附近,示例如下: [贵州省(520000)|PROV|0|][贵阳市(520100)|CITY|0|][南明区(520102)|AREA|0|] 太慈桥[车水路()|ROAD|1|]第十五中学北
-
带有附加地址和 POI_PARENT 字段的数据,示例如下: [ 贵 州 省 (520000)|PROV|0|][ 贵 阳 市 (520100)|CITY|0|][ 观 山 湖 区 (520115)|AREA|0|][ 商 城 东 路 ()|ROAD|0|] 杭 州 路 [ 贵 阳 西 南 国 际 商 贸 城 (4665258296544379272)|POI_PARENT|1|]
-
带有附加地址的数据,同时路或街道数据被附加地址数据所分割: [ 贵 州 省 (520000)|PROV|0|][ 贵 阳 市 (520100)|CITY|0|][ 观 山 湖 区 (520115)|AREA|0|]金岭社区服务中心高新区[阳关大道()|ROAD|1|110 号$]
以上数据中,1、2、3、4、5 可以按照以下正则表达式分割为省、市、区、路(可能为空)、门牌号(可能为空),附加地址信息(可能为空):
String xareg = "\|\d*\|\]";//截取到]
对于第五类数据,分割出来的路数据可能会包含附加信息数据,需要使用程序再次分割。 多条高德数据指向同一百度数据 对于有边界的情况,出现多条高德数据指向同一百度的数据时,将地址名称以百度地图的为准,对于没有边界的地址,如果该地址数据属于需要入库的分类,则其地址信息也 以百度的地址数据为准。
数据结果去重
功能描述
数据去重主要分为高德地图数据去重和百度地图数据去重,同时要筛选掉明显不符合结果详 情的数据,例如根据高德的名称从百度地图中查询出来的数据地市明显不符合要求,这些数 据需要筛选掉。
关键功能点及解决办法
高德地图数据去重
高德地图数据去重可以使用 SQL 直接去重,因为高德数据中 ID 数据是唯一的(如果爬 取数据量过大,高德会处于数据保护的原因返回错误数据,会导致 ID 不唯一,如果出 现 ID 不唯一,解决方案是重新申请一个 Key 然后替换),可以使用如下 SQL 进行 ID 的数据去重:
select t.id,count(id) from t_amap_addr_temp t group by id having
count(t.id) > 1;
select min(rowid) from t_amap_addr_temp t group by id having
count(t.id) > 1;
delete from t_amap_addr_temp a where a.id in (select t.id from
t_amap_addr_temp t group by id having count(t.id) > 1)
and rowid not in (select min(rowid) from t_amap_addr_temp t group by id having count(t.id) > 1);
如果数据量过大,直接执行可能会导致崩溃,可用创建临时表的方式去重:
select t.id,count(id) from t_amap_cus_temp t group by id having count(t.id) > 1;
select min(rowid) from t_amap_cus_temp t group by id having count(t.id) > 1;
delete from t_amap_cus_temp a where a.id in (select t.id from t_amap_cus_temp t group by id having count(t.id) > 1)
and rowid not in (select min(rowid) from t_amap_cus_temp t group by id having count(t.id) > 1);
select t.*,t.rowid from t_amap_cus_temp t where t.id = 'B035302WL1';
create table t_temp_cus_del as select t.id,count(id) counts from t_amap_cus_temp t group by id having count(t.id) > 1;
create table t_temp_cus_rowid as select min(rowid) minrowid from t_amap_cus_temp t group by id having count(t.id) > 1;
select t.*,t.rowid from t_temp_cus_del t;
select t.*,t.rowid from t_temp_cus_rowid t;
delete from t_amap_cus_temp a where a.id in (select t.id from t_temp_cus_del t) and rowid not in (select b.minrowid from t_temp_cus_rowid b );
百度地图数据去重
对于多条高德数据,查询出同一条百度数据来的情况,使用百度地图查询出来的地址信息数据。这些数据有一些明显不符合要求,例如查询出来的省份或者地市不正确,可以直接在数据库中执行删除。删除之后,还会出现百度地图UID相同的数据,这些数据可以直接使用 SQL去重,其 SQL如下所示:
create table t_cus_bmap_rowid_del as select min(rowid) minrow from t_amap_cus_temp t group by t.bmap_uid having count(t.bmap_uid) > 1;
create table t_cus_bmap_uid_del as select t.bmap_uid from t_amap_cus_temp t group by t.bmap_uid having count(t.bmap_uid) > 1;
delete from t_amap_cus_temp t where t.bmap_uid in (select b.bmap_uid from t_cus_bmap_uid_del b)
由于要使用百度地图的数据为准,需要将该数据的分类赋值为百度地图的分类,并将地址的名称赋值为百度地图获取的地址名称。
update t_amap_addr_temp t set t.zh_label = t.bmap_zhlabel,t.types =
concat('BMAP_',t.bmap_types) where t.bmap_uid in (select a.bmap_uid
from t_cus_bmap_uid_del a);
建立地址关系
功能描述
建立地址关系主要是通过程序对标准地址的分割数据进行筛选,需要注意的是目前地址只能分割到前六级,即小区/公司/园区一级,标准地址的附加信息中可能会包含 7-9 级地址数据, 但是目前没有很好的方式分割。对于标准地址的分割数据中,街道和镇等可能会与附加信息 处于同一等级,例如: [贵州省(520000)|PROV|0|][贵阳市(520100)|CITY|0|][修文县(520123)|AREA|0|]扎佐镇[襄 阳南路()|ROAD|1|308 号$] 和[贵州省(520000)|PROV|0|][贵阳市(520100)|CITY|1|][云岩区(520103)|AREA|1|]贵乌社区服务中心[百花山路()|ROAD|1|123 号$] 也可能没有乡镇/街道信息,目前解决办法是将路/街道/乡镇信息全部汇入附加信息一级,街 道和乡镇一级为空。对于标准地址分割中不包括路等级的(路一级可能会在附加信息中出现, 但是没有规律,例如:[贵州省(520000)|PROV|0|][贵阳市(520100)|CITY|0|][白云区 (520113)|AREA|0|]诚信南路)直接采取舍弃改地址的方式处理。
关键功能点及解决办法
- OOM异常:由于采用程序批量处理地址数据,将地址数据入库时采用的方法为直接加载到内存处理,如果数据量过大时很可能出现 OOM 异常,目前通过加大程序内存解决,后续需要将程 序更改为分批处理的方案。
- 地址信息不全:对于百度的地址分割数据不是标准地址的信息,例如没有路信息的地址,目前的处理方案为直接舍弃,对于没有门牌号信息的地址,目前的解决方案为将门牌号关联置空,对 于有附加信息的数据,将数据保存到六级地址的附加信息字段中,用于在以后再次提取地址信息数据使用。对于有边界信息的地址数据,将边界信息直接保存到六级地址的 Clob 类型的字段中。
标准地址入库
功能描述
标准地址入库功能主要是将分割和建立好地址关系的数据录入标准地址数据库,主要为前六级数据:省、地市、区县、街道(目前为空)、路、门牌号(可能为空)、小区/园区/公司级, 各地址之间使用唯一的 INT_ID 作为关联。