目录
1.1 Mysql数据库的优化技术
1.2 数据库表设计
1.3 SQL优化
1、为查询缓存优化你的查询
2、EXPLAIN 你的 SELECT 查询
3、 当只要一行数据时使用 LIMIT 1
4、建立适当的索引
1.4 MySQL中like模糊匹配为何低效
1.5 数据库优化方案
1.6 数据库怎么优化查询效率
1.1 Mysql数据库的优化技术
1、mysql优化是一个综合性的技术,主要包括
1. 表的设计合理化(符合3NF)
2. 添加适当索引(index) [四种: 普通索引、主键索引、唯一索引unique、全文索引]
3. 分表技术(水平分割、垂直分割)
4. 读写[写: update/delete/add]分离
5. 存储过程 [模块化编程,可以提高速度]
6. 对mysql配置优化 [配置最大并发数my.ini, 调整缓存大小 ]
7. mysql服务器硬件升级
8. 定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
2、要保证数据库的效率,要做好以下四个方面的工作
1. 数据库设计
2. sql语句优化
3. 数据库参数配置
4. 恰当的硬件资源和操作系统
此外,使用适当的存储过程,也能提升性能。
这个顺序也表现了这四个工作对性能影响的大小
1.2 数据库表设计
1、通俗地理解三个范式
第一范式: 1NF是对属性的原子性约束,要求属性(列)具有原子性,不可再分解;(只要是关系型数据库都满足1NF)
第二范式: 2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式: 3NF是对字段冗余性的约束,它要求字段没有冗余。 没有冗余的数据库设计可以做到
2、第一范式(1NF)
1. 即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只要数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF。
2. 数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
3. 如果实体中的某个属性有多个值时,必须拆分为不同的属性 。通俗理解即一个字段只存储一项信息。
3、第二范式(2NF)
1、要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要我们设计一个主键来实现(这里的主键不包含业务逻辑)。
4、第三范式(3NF)
1、要求一个数据库表中不包含已在其它表中已包含的非主键字段。
2、如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键join就用外键join)。
3、很多时候,我们为了满足第三范式往往会把一张表分成多张表。
1.3 SQL优化
1、为查询缓存优化你的查询
1、大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。
2、当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
3、像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。
2、EXPLAIN 你的 SELECT 查询
1、explain关键字作用
1、使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
2、EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
2、explain使用举例
Explain select * from emp where ename=“wsrcla”
会产生如下信息:
select_type: 表示查询的类型。
table: 输出结果集的表
type: 表示表的连接类型
possible_keys: 表示查询时,可能使用的索引
key: 表示实际使用的索引
key_len: 索引字段的长度
rows: 扫描出的行数(估算的行数)
Extra: 执行情况的描述和说明
3、EXPLAIN信息详解
1. id SELECT识别符。这是SELECT的查询序列号
2. select_type
PRIMARY : 子查询中最外层查询
SUBQUERY : 子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY: 子查询内层第一个SELECT,依赖于外部查询
UNION : UNION语句中第二个SELECT开始后面所有SELECT,
SIMPLE: 简单的 select 查询,不使用 union 及子查询
UNION : UNION 中的第二个或随后的 select 查询,不依赖于外部查询的结果集
3. Table : 显示这一步所访问数据库中表名称
4. Type : 对表访问方式
ALL: SELECT * FROM emp G 完整的表扫描 通常不好
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system: 表仅有一行(=系统表)。这是const联接类型的一个特
const: 表最多有一个匹配行
5. Possible_keys : 该查询可以利用的索引,如果没有任何索引显示 null
6. Key : Mysql 从 Possible_keys 所选择使用索引
7. Rows : 估算出结果集行数
8. Extra查询细节信息
No tables : Query语句中使用FROM DUAL 或不含任何FROM子句
Using filesort : 当Query中包含 ORDER BY 操作,而且无法利用索引完成排序,
Impossible WHERE noticed after reading const tables: MYSQL Query Optimizer
通过收集统计信息不可能存在结果
Using temporary: 某些操作必须使用临时表,常见 GROUP BY ; ORDER BY
Using where: 不用读取表中所有信息,仅通过索引就可以获取所需数据;
3、 当只要一行数据时使用 LIMIT 1
1、当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
2、在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
4、建立适当的索引
1、索引为什会使查找变快
1、btree类型的索引,就是使用的二分查找法,肯定快啊,算法复杂度是log2N,也就是说16条数据查4次,32条数据查5次,64条数据查6次....依次类推。
2、使用索引跟没使用索引的区别,就跟我们使用新华字典查字,一个是根据拼音或者笔画查找,一个是从头到尾一页一页翻。
2、索引的代价
1、磁盘占用
2、对dml(update delete insert)语句的效率影响
3、索引使用原则
1、较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1;
2、唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
select * from emp where sex = '男'
3、更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1
4、不会出现在WHERE子句中的字段不该创建索引
4、mysql四种索引的区别
1、主键索引,主键自动的为主索引 (类型Primary)
2、唯一索引 (UNIQUE)
3、普通索引 (INDEX)
4、全文索引 (FULLTEXT) [适用于MyISAM] ——》sphinx + 中文分词 coreseek [sphinx 的中文版 ]
*5、索引的使用 *
1. 建立索引
1、create [UNIQUE|FULLTEXT] index index_name on tbl_name (col_name [(length)] [ASC | DESC] , …..);
2、alter table table_name ADD INDEX [index_name] (index_col_name,...)
2. 删除索引
1、DROP INDEX index_name ON tbl_name;
2、alter table table_name drop index index_name;
注:删除主键(索引)比较特别: alter table t_b drop primary key;
3. 创建普通索引方法
#1 查看student表中有哪些索引
mysql> show index from student; #查看student表中有哪些索引
#2 创建最基本的的索引
mysql> create index index_name on student(name(32)); #将student中字段name创建成索引
#3 删除索引的语法
mysql> drop index index_name on student;
4. 创建唯一索引
注: 它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
#1创建索引
mysql> create unique index index_name on student(name(32));
6、使用或不使用索引的情况
1. 下列几种情况下有可能使用到索引
1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
2,对于使用like的查询,查询如果是 '%aaa' 不会使用到索引, 'aaa%' 会使用到索引。
2. 下列的表将不使用索引
1, 如果条件中有or,即使其中有条件带索引也不会使用。
2, 对于多列索引,不是使用的第一部分,则不会使用索引。
3, like查询是以%开头
4, 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。(添加时,字符串必须'')
5, 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
1.4 MySQL中like模糊匹配为何低效
1、都不使用索引
- 说明:不使用索引的时候普通查询与like查询的耗时相当,like略长,这也是必然的,因为它要进行额外的算法
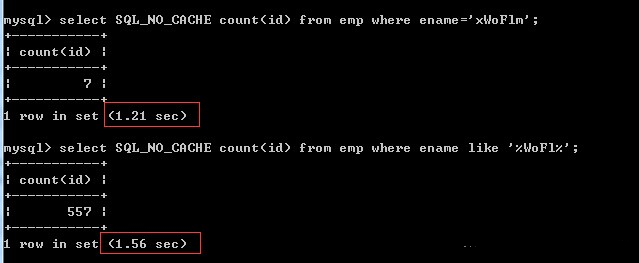
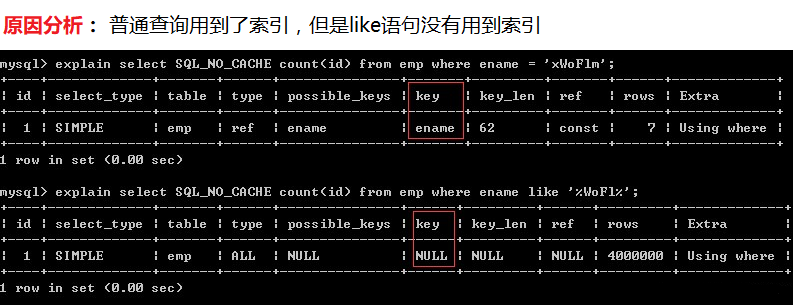
2、like不使用索引、普通查询使用索引
- 说明:使用索引后,普通查询的耗时基本算是秒查,非常快;而like查询还是耗时一秒多。

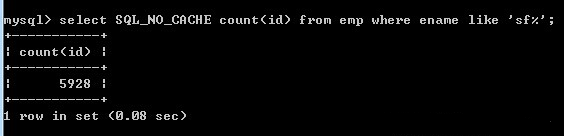
3、like查询起始也可以使用索引
1)如果我们查询的时候写成“like 'dd_'或者like 'dd%'”,这样是可以用到索引的,此时的查询速度也会相对的快一点。
2)如果查询的时候写成“ like '%dd'”,查询字符串最前面就是模糊的无法使用索引
1.5 数据库优化方案
1. 优化索引、SQL 语句、分析慢查询
2. 设计表的时候严格根据数据库的设计范式来设计数据库
3. 使用缓存,把经常访问到的数据而且不需要经常变化的数据放在缓存中,能节约磁盘IO
4. 优化硬件;采用SSD,使用磁盘队列技术(RAID0,RAID1,RDID5)等;
5. 采用MySQL 内部自带的表分区技术,把数据分层不同的文件,能够提高磁盘的读取效率
6. 垂直分表;把一些不经常读的数据放在一张表里,节约磁盘I/O
7. 主从分离读写;采用主从复制把数据库的读操作和写入操作分离开来
8. 分库分表分机器(数据量特别大),主要的的原理就是数据路由
9. 选择合适的表引擎,参数上的优化
10. 进行架构级别的缓存,静态化和分布式
11. 不采用全文索引
1.6 数据库怎么优化查询效率
1、储存引擎选择:如果数据表需要事务处理,应该考虑使用InnoDB,因为它完全符合ACID特性。如果不需要事务处理,使用默认存储引擎MyISAM是比较明智的
2、分表分库,主从。
3、对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
4、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
5、应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描
6、应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
7、Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志
8、对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。