2014年,Ian Goodfellow和他的同事发表了一篇论文,向世界介绍了生成对抗网络(GAN)。通过对计算图和博弈论的创新性组合,他们表明如果有足够的建模能力,两个相互对抗的模型可以通过普通的反向传播进行共同训练。
模型具有两个不同的角色。给定数据集 R ,生成器 G 试图创建类似真实数据的假数据,鉴别器 D 分辨真实数据或假数据,并计算它们的差异。Goodfellow将 G 比喻为一群伪造者试图创作真实的绘画作品,而 D 则是试图分辨真假绘画的侦探团队。(除了这个例子, G 从没有接触到真实的数据,只有鉴别器 D 可以看到。)
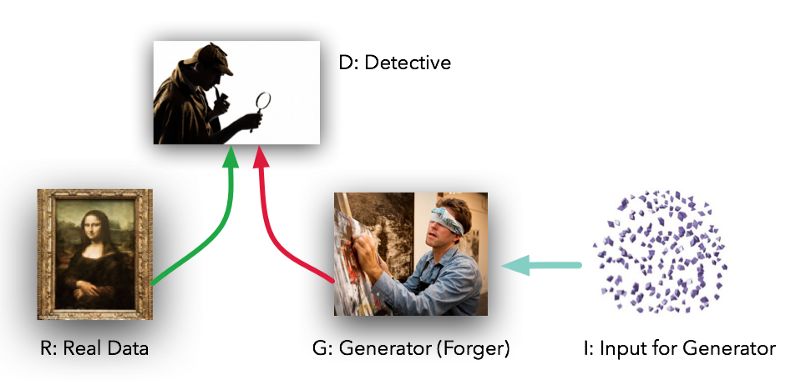
理想情况下, D 和 G 都会越来越好,直到 G 可以完全模仿真实的绘画,并且 D 不能分辨真假。
在实践中,Goodfellow展示了 G 使用真实数据集进行无监督学习,找到某种简单的方式表示该数据。正如Yann LeCun所说,无监督学习才是人工智能真正的“蛋糕”。
这种方法是否需要很多代码才能实现?实际上使用PyTorch,我们可以只用50行代码就可以创建一个非常简单的GAN。一共需要考虑5个部分:
-
R :原始数据集
-
I :输入生成器的随机噪声
-
G :模仿原始数据集的生成器
-
D :辨别器
-
不断训练 G 去欺骗 D ,而 D 进行分辨。
1.) R :我们从最简单的 R - 正态分布曲线开始。该函数输入均值和标准差,返回一个生成样本数据的函数,这些数据使用带参数的高斯函数生成的。我们的代码中平均值为4.0,标准差为1.25。

2.) I :生成器的输入是随机的,但是为了增加一点难度,我们使用均匀分布而不是正态分布。这意味着模型G 不能简单地通过转换或缩放得到 R ,而是必须以非线性方法生成数据。

3.) G :生成器是标准的前向传播图,两个隐藏层,三个全连接层,双曲正切激活函数。 G 从 I 中输入均匀分布的数据样本,以某种方式模仿 R 的正态分布,即使它没有接触过 R 。
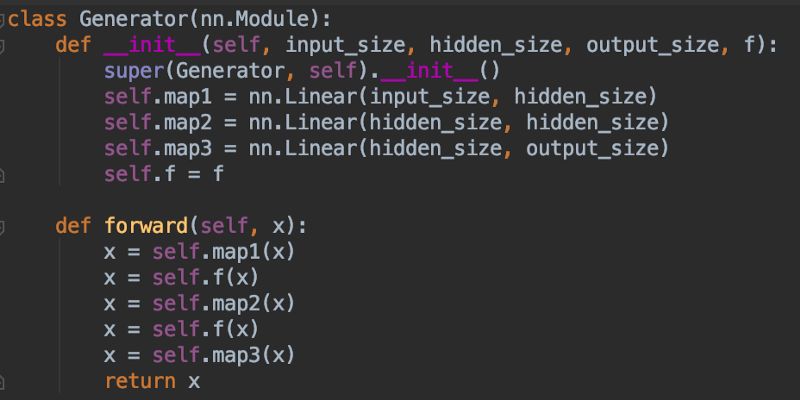
4.) D :鉴别器与生成器 G 的代码非常相似。它是有两个隐藏层,三个全连接层的前向图。激活函数是sigmoid。它从 R 或 G 获取数据,并输出0到1之间的数字,用来表示“真”或“假”。换句话说,这也是一般的神经网络做的事情。
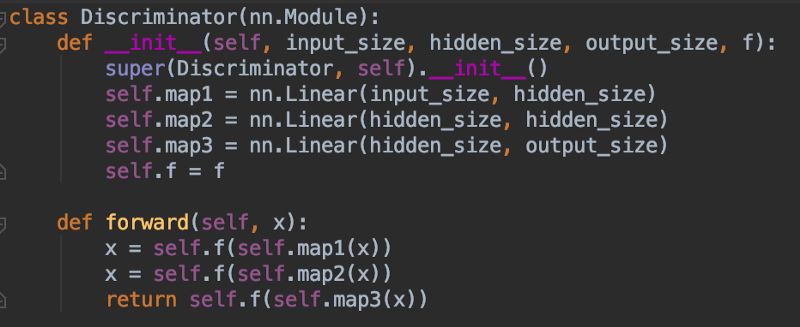
5.)最后,不断在这两个模型之间交替训练:首先使用用真实的数据集训练 D 分辨真实数据和虚假数据, 然后训练 G 生成虚假数据欺骗 D 。

即使你之前没有接触过PyTorch也可以大概了解上面代码的运行过程。在绿色部分,通过向 D 输入真实或虚假的数据,并在 D 的预测结果和真实标签之间应用交叉熵函数。这是“前向传播”的步骤; 然后调用'backward()'函数计算梯度,调用 d_optimizer.step() 更新 D 的参数。这里用到了 G 但没有对它进行训练。
在红色部分,对 G 做同样的过程。注意我们将 G 的输出作为 D 的输入(给伪造者一个侦探进行练习),但不对 D 进行优化,因为不能让辨别器 D 学习错误的标签。因此我们只调用 g_optimizer.step()。
上面就是所有的过程。当然还有一些其他代码,但GAN主要就是这5个部分。
经过几千轮的迭代,鉴别器 D 能力提高的很快(相对来说 G 提高的比较慢),但是一旦到达某种程度,生成器 G 就会因为有一个相当优秀的对手并开始迅速的提高能力。
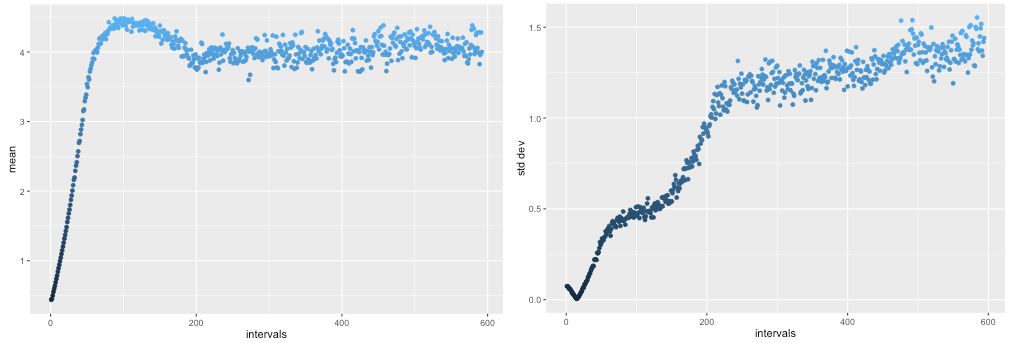
经过5,000轮的训练,每轮都训练了生成器 G 20次,鉴别器 D 20次。 G 输出的均值超过了4.0,但随后回到了正确的范围(左)并稳定下来。同样的,标准差刚开始在较低的位置徘徊,但随后上升到正确的1.25范围(右),和数据集 R 相同。
最终结果的统计数据和数据集 R 相匹配。但是分布的形状是否相同呢?毕竟,也有均值4.0,标准差为1.25,但与 R 不同的均匀分布。看一下 G 的最终分布:
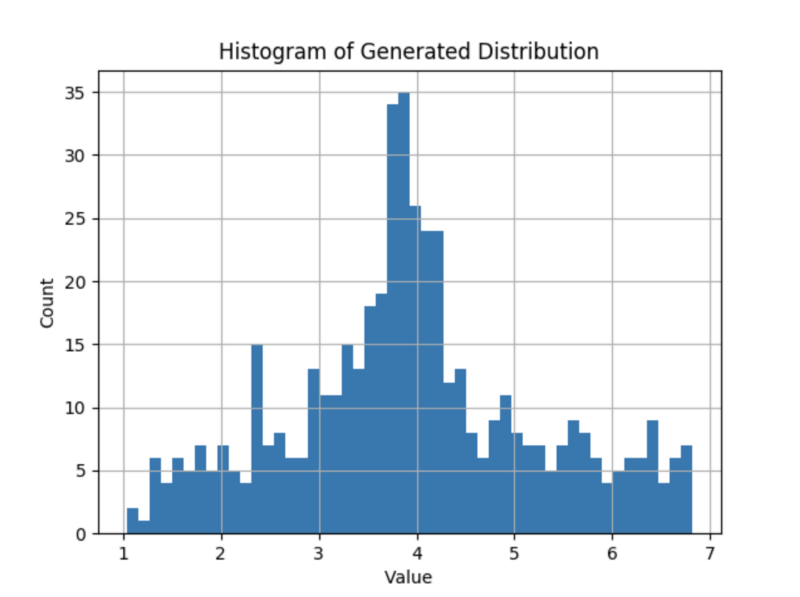
挺好。右下比左下胖一点,可能偏态和峰度受到了原始数据的影响。
生成器 G 几乎完美还原了原始数据集 R ,并且辨别器 D 几乎无法分辨。这正是我们想要的结果。实现这个一共只有不到50行的代码。
提醒:GAN比较挑剔,而且比较脆弱。当它们进入了某种状态,可能会得到其他奇怪的结果。运行示例代码十次(每次超过5,000轮迭代)后得到了下面十个分布结果:
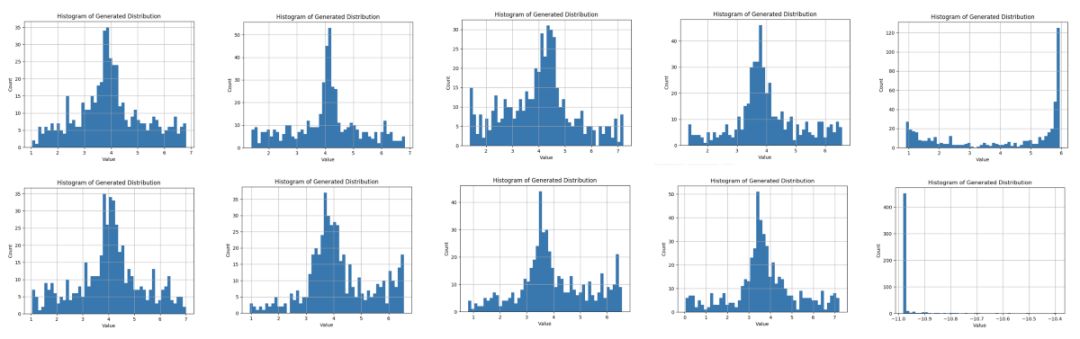
可以看到十次运行中有八次结果符合分布。但有两次不符合。其中一种情况(第5次运行)出现了凹面的分布,均值约为6.0。最后一次运行结果(第10次运行),在值 -11 处有一个狭窄的峰值!当你在其他环境中使用GAN时,它并不像有监督学习那样稳定。但是当它们正常工作时,它们的效果就非常好。