导航目录
1.装饰器
1.1 函数即变量
1.2 高阶函数
1.3 嵌套函数
1.4 高阶函数+嵌套函数 =>就能实现本节的函数装饰器功能
2.迭代器&生成器
2.1 列表生成式
2.2 生成器
2.3 斐波那契序列
2.4 生成器实力应用
2.5 迭代器
迭代器&生成器两者的对比
3.Json & pickle 数据序列化
3.1 Json
3.2 pickle
3.3 pickle 简便方法介绍
3.4 二者区别
3.5 dump和load注意事项
4.跨目录的模块调用
5.软件目录结构规范
装饰器
定义:装饰器本质是函数
功能:用来装饰其它函数,翻译成大白话就是为其它函数增加附加功能
遵循原则:1.不能改被装饰函数的代码题 2.函数的调用方式不能被更改
实现装饰器必备的知识储备:
1.函数即变量
2.高阶函数
3.嵌套函数
高阶函数+嵌套函数 =>就能实现本节的函数装饰器功能
函数即变量
函数的错误调用方式
错误调用方式一: # Author:Sean sir def foo(): print('in the foo!') bar() foo() # 输出 NameError: name 'bar' is not defined 错误调用方式二: # Author:Sean sir def foo(): print('in the foo!') bar() foo() def bar(): print('in the bar!') # 输出 NameError: name 'bar' is not defined
函数的正确调用方式
正确调用方式一: # Author:Sean sir def foo(): print('in the foo!') bar() def bar(): print('in the bar!') foo() # 输出 in the foo! in the bar! 正确调用方式二: # Author:Sean sir def bar(): print('in the bar!') def foo(): print('in the foo!') bar() foo() # 输出 in the foo! in the bar!
我们可以想象如果把整个内存看作一个大楼的话,那么当我们变量并赋值情况大概是这样的,见图
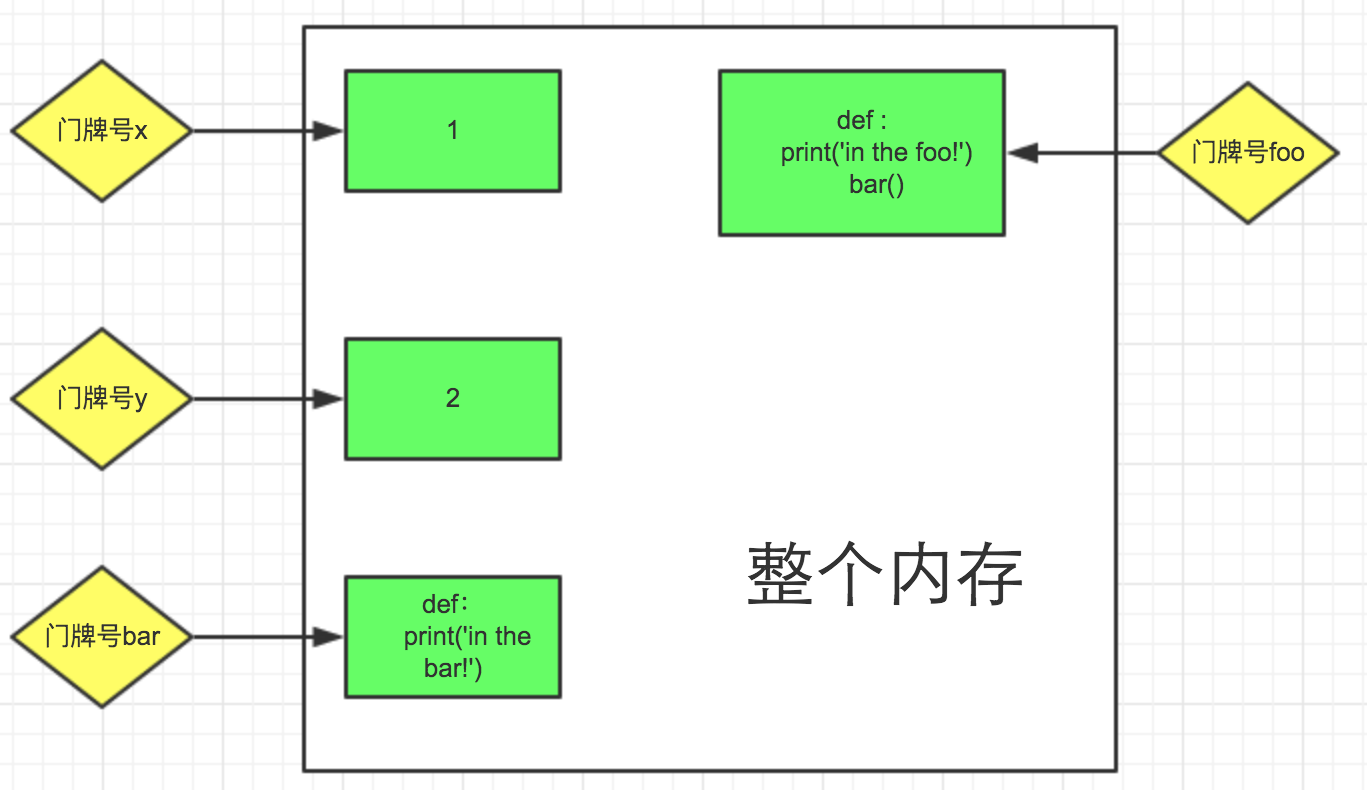
如果python发现这里是一个函数讲不执行,那么继续往下走,当有函数调用的情况下的,才会执行这个函数,所以说如果调用函数要先声明函数
高阶函数
定义:a.把一个函数名当做实参传给另外一个函数 (看下面的第二个列子,我们貌似感觉到了,我们可以利用高阶函数在不修改被装饰的函数代码实现附加功能)
b.返回值中包涵函数名 (看到下面的第三个列子,我们貌似感觉到了,我们可以不修改被修饰函数的调用方式实现附加功能)
按照第一个定义,我们来写一个高阶函数,示例一:
# Author:Sean sir def bar(): print('in the bar!') def foo(fun): print('in the foo!') print(fun) fun() foo(bar) # 输出 in the foo! # 这里输出的是bar所在的内存地址 <function bar at 0x101a7aa60> # 执行了bar这个方法 in the bar!
示例二:
# Author:Sean sir import time def bar(): print('in the bar!') time.sleep(3) def foo(fun): star_time = time.time() fun() stop_time = time.time() print('fun run time: %s' % (stop_time - star_time)) foo(bar) # 输出 in the bar! fun run time: 3.0041251182556152 Process finished with exit code 0
按照第二个定义,来创建一个高阶函数
# Author:Sean sir import time def bar(): print('in the bar!') time.sleep(3) def foo(fun): print('aaaaaaaaaa') return fun bar = foo(bar) bar() # 输出 aaaaaaaaaa in the bar!
嵌套函数
def foo(): print('in the foo') def bar(): print('in the bar') bar() foo() # 输出 in the foo in the bar
小高潮版的装饰器
# Author:Sean sir import time def test1(fun): def test2(): start_time = time.time() fun() stop_time = time.time() print('run time:%s' %(stop_time-start_time)) return test2 @test1 def ceshi(): print('in the ceshi!') time.sleep(2) ceshi() # 输出 in the ceshi! run time:2.0033769607543945
上面的代码,我猜你也看不明白,看图吧,我来画图!
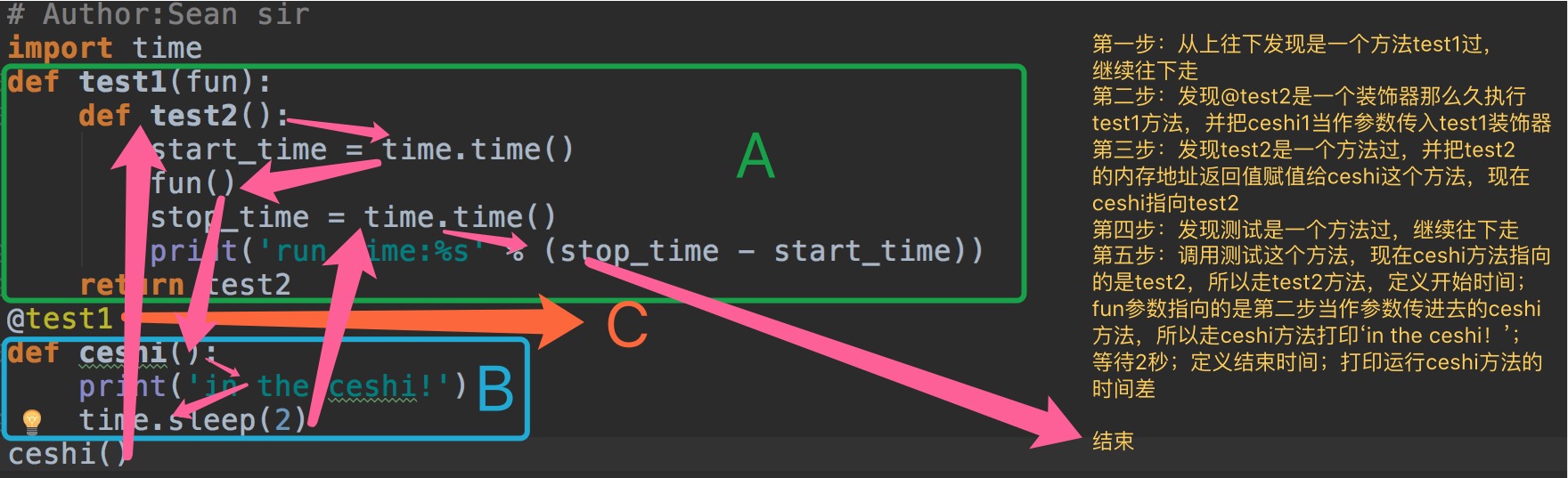
小高潮版装饰器2
上面的装饰器中所有的函数都是没有参数的,加入要使用装饰器函数有形参呢?
# Author:Sean sir import time def test1(fun): def test2(*args, **kwargs): start_time = time.time() fun(*args, **kwargs) stop_time = time.time() print('run time:%s' % (stop_time - start_time)) return test2 @test1 def ceshi(name,info): print('-------start------') print(name) for i in info: print(i,info[i]) print('--------end-------') time.sleep(2) ceshi('alex', {'age':34,'sex':'man','job':'teacher'}) # 输出 -------start------ alex sex man job teacher age 34 --------end------- run time:2.005190134048462
装饰器终极高潮
# 带返回值的装饰器 user = 'sean' passwd = 'abc123' def auth(fun): def warrp(*args, **kwargs): username = input('UserName:').strip() Password = input('Passwd:').strip() if user == username and passwd == Password: print('Log in successfully!') return fun(*args, **kwargs) # 这个返回值是为了返回函数的执行结果 else: print('Logon failure') exit() return warrp def index(): print('In the index!') @auth def home(): print('In the Home!') return 'form home!' @auth def bbs(): print('In the BBS') index() print(home()) bbs()
# 带返回值的装饰器&通过装饰器传入不同参数,进行逻辑处理 user = 'sean' passwd = 'abc123' def auth(auth_type): print(auth_type) def outer_wrapper(fun): def warrp(*args, **kwargs): print( auth_type ) username = input('UserName:').strip() Password = input('Passwd:').strip() if user == username and passwd == Password: print('Log in successfully!') return fun(*args, **kwargs) # 这个返回值是为了返回函数的执行结果 else: print('Logon failure') exit() return warrp return outer_wrapper # 这个返回值处理效果等于 auth = outer_wrapper def index(): print('In the index!') @auth(auth_type = 'local') # 因为这里加了小括号,所以当运行完了第一遍的时候,回再走一遍,自然进入了outer_wrapper方法, # outh_wrapper方法把home函数当作一个参数传了进去,fun自然就成了home方法, # 后面的执行程序和上面讲的的装饰器一个效果 def home(): print('In the Home!') return 'form home!' @auth(auth_type = 'ldap') def bbs(): print('In the BBS') index() home() bbs()
迭代器&生成器
列表生成式
作用:使代码更简洁(还可以提高逼格)
# Author:Sean sir # 生成式 alist = [i * 2 for i in range(19)] print(alist) # 不用生成式 alist = [] for i in range(10): alist.append(i*2) print('append',alist)
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。---摘抄自大王博客
上面说的优点太官方,我还是给翻译成白话文吧,哈哈
假如我们使用生成式来创建了一个包涵10w元素的列表,我们可想而知这样庞大的数据对我们系统内存将产生不可估量的影响,而且当我循环列表的时候,我们执行第一遍循环的时候后面的元素对我没有用,我们完全可以不用知道这个列表后面的元素是什么,聪明的人类根据这个特性就想出了一个好的办法,我们可以通过某种算法把生成这个列表的规律存放下来,我们根据这个规律来推算出后面的元素值,由此伟大的发明“生成器”就诞生了。---本段摘抄自作者本人内心
# Author:Sean sir # 使用生成式生成一个列表 alist = [i * 2 for i in range(19)] print(alist) # 我们来使用这种规律做一个生成器 alist = (i * 2 for i in range(19)) print(alist) # 输出 [0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36] <generator object <genexpr> at 0x101b7f888>
可能上面的效果并不是很直观的看出一个生成器的速度来,如果你不信,自己可以来一个试着生成1个亿的列表试试看,这里要说的是 后者并没有真正生成10个元素的列表,只是把他们的生成规律记了下来,所以它“后者”快。
继续看生成器的用法:
# Author:Sean sir # 使用生成式生成一个列表 a = [i * 2 for i in range(19)] print(a) # 我们来使用这种规律做一个生成器 c = (i * 2 for i in range(19)) print(c) print(a[5]) print(c[5]) # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/列表生成式.py Traceback (most recent call last): File "/Users/sean/python/s14/课堂/d4/列表生成式.py", line 11, in <module> print(c[5]) TypeError: 'generator' object is not subscriptable [0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36] <generator object <genexpr> at 0x10137f888> 10 Process finished with exit code 1
上面我们可以看到,列表可以实时调用,但是后者的生成器不能直接调用后面的元素,原因是生成器只能在循环到本次才会生成本次的数据,所以它不支持切片、下标等方式的取数据,总而言之:1.生成器只有在调用时才会生成相应的数据 2.生成器只记住当前位置,无法调用前面的数据,只能通过next方法调用后面的数据。3.生成器不能跨着往后读数据,如果想看到后面第十个的数据,没办法只能next10次,来看代码:
# Author:Sean sir # 使用生成式生成一个列表 a = [i * 2 for i in range(19)] print(a) # 我们来使用这种规律做一个生成器 c = (i * 2 for i in range(19)) print(c) print(a[5]) print(c.__next__()) print(c.__next__()) print(c.__next__()) print(c.__next__()) print(c.__next__()) print(c.__next__()) # 输出 [0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36] <generator object <genexpr> at 0x10137f888> 10 0 2 4 6 8 10 Process finished with exit code 0
明显上面的next的方法比较笨拙,我们可以使用循环的方式调用生成器的数据,如果使用for循环是不会出错的看代码:
# Author:Sean sir # 我们来使用这种规律做一个生成器 c = (i * 2 for i in range(19)) # 使用异常处理的方式,进行循环这个生成器 try: while True: print(c.__next__()) except StopIteration as a: print(a) # 输出 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 Process finished with exit code 0
# Author:Sean sir
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
data = fib(10)
for i in data:
print(i)
/usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/斐波那契序列.py
1
1
2
3
5
8
13
21
34
55
Process finished with exit code 0
斐波那契序列
生成器功能非常强大,上面我们对这种具有简单规律的序列,可以使用这种方法,但是有些复杂的,上面的功能就不能实现了。
著名的斐波那契数列,算是比较复杂的规律序列,我们用函数的方法来实现,看代码:
# Author:Sean sir def fib(max): n, a, b = 0, 0, 1 while n < max: print(b) a, b = b, a + b a=0 b=1 a = 1 b = 1 a =2 b =3 n = n + 1 return 'done' fib(10) # 输出 1 1 2 3 5 8 13 21 34 55 Process finished with exit code 0
上面我们实现了斐波那契数列,距离生成器只有一步之遥,只需要把print改成yield就好了,看代码:
# Author:Sean sir def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 return 'done' print(fib(10)) # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/斐波那契序列.py <generator object fib at 0x101b7f888> Process finished with exit code 0
有人说上面实现的效果没有啥用,那我们就来说说有啥用?
# Author:Sean sir def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 return 'done' data = fib(10) print(data.__next__()) # 假如不使用生成器的话,如果想执行函数外面的代码块,那么只有等上看的函数运行完毕后, # 才能继续往下走,现在有了生成器,我们可以执行一次函数,执行一次外面的代码块, # 执行一次函数,执行一次外面的代码快, 执行函数只需要调用next方法就可以了。现在是不是感觉到,生成器有点卵用了呢? print('函数外代码块') print(data.__next__()) print('函数外代码块2') print(data.__next__()) print('函数外代码块3') print(data.__next__()) print('函数外代码块4') print(data.__next__()) print('函数外代码块5') print(data.__next__()) print('函数外代码块6') # 输出1 函数外代码块 1 函数外代码块2 2 函数外代码块3 3 函数外代码块4 5 函数外代码块5 8 函数外代码块6 Process finished with exit code 0
下面我们来用while循环的方式来循环一下这个生成器,并用try做一下异常处理:
# Author:Sean sir def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 #return 'done' # 此处的作用是当有异常的情况下,打印的错误,如果这里不定义,那么捕捉异常的时候,不返回任何数据 try: data = fib(10) while True: print(data.__next__()) except StopIteration as a: print(a.value) # # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/斐波那契序列.py 1 1 2 3 5 8 13 21 34 55 # 如果函数中没有返回值,那么这里打印的a.value将会是一个None;如果有返回值,那么这里打印的就是返回值的内容 None
生成器实力应用
我们来做一个吃饱的过程,看代码:
import time def consume(name): print('[%s]开始吃包子了!' % name) while True: baozi = yield print('[%s]的包子被[%s]吃了!' % (baozi,name)) chibaozi = consume('sean') chibaozi.__next__() # 硬生生的做一个韭菜馅的包子 b1 = '韭菜馅' # 把这个韭菜馅的包子送到包子铺 chibaozi.send(b1) # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/做包子.py [sean]开始吃包子了! [韭菜馅]的包子被[sean]吃了! Process finished with exit code 0
现在我们不硬生生的做包子了,我们有一个包子铺还有一个专门做包子的工坊,一边做一边卖,看代码:
就这样我们实现了简单的单线程并行的效果,虽说是有那么点意思,但是说到底,还是串行,可以仔细揣摩一下!
import time # 包子铺 def consume(name): print('[%s]开始吃包子了!' % name) while True: baozi = yield print('[%s]的包子被[%s]吃了!' % (baozi,name)) # 做包子工坊 def produce(*args,**kwargs): clent1 = consume(args[0]) clent1.__next__() clent2 = consume(args[1]) clent2.__next__() print('有吃货上门,我们要开始做包子了!') i = 0 while i < 10: print( '---------开吃第%s波吃了-------' % i ) print( '包子%s熟了' % i ) clent1.send(i) clent2.send(i) i += 1 time.sleep(1) produce('sean','xiaoxin') # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/做包子.py [sean]开始吃包子了! [xiaoxin]开始吃包子了! 有吃货上门,我们要开始做包子了! ---------开吃第0波吃了------- 包子0熟了 [0]的包子被[sean]吃了! [0]的包子被[xiaoxin]吃了! ---------开吃第1波吃了------- 包子1熟了 [1]的包子被[sean]吃了! [1]的包子被[xiaoxin]吃了! ---------开吃第2波吃了------- 包子2熟了 [2]的包子被[sean]吃了! [2]的包子被[xiaoxin]吃了! ---------开吃第3波吃了------- 包子3熟了 [3]的包子被[sean]吃了! [3]的包子被[xiaoxin]吃了! ---------开吃第4波吃了------- 包子4熟了 [4]的包子被[sean]吃了! [4]的包子被[xiaoxin]吃了! ---------开吃第5波吃了------- 包子5熟了 [5]的包子被[sean]吃了! [5]的包子被[xiaoxin]吃了! ---------开吃第6波吃了------- 包子6熟了 [6]的包子被[sean]吃了! [6]的包子被[xiaoxin]吃了! ---------开吃第7波吃了------- 包子7熟了 [7]的包子被[sean]吃了! [7]的包子被[xiaoxin]吃了! ---------开吃第8波吃了------- 包子8熟了 [8]的包子被[sean]吃了! [8]的包子被[xiaoxin]吃了! ---------开吃第9波吃了------- 包子9熟了 [9]的包子被[sean]吃了! [9]的包子被[xiaoxin]吃了! Process finished with exit code 0
迭代器
Json & pickle 数据序列化
序列化的作用:可以把系统当前的状态序列化的存放到文件中,就像VMware中的挂起功能,当点挂起按钮的时候,就会吧虚拟机的状态序列化的存放到文件中;
当然有序列化有反序列化,下面我们来讲解下,看代码:
Json
序列化
# Author:Sean sir import json info = { 'name':'sean', 'age':28, 'job':'it', 'salary':9999 } print(type(json.dumps( info ))) f = open('序列化存放文件','w+') f.write(json.dumps(info)) f.close() # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/序列化.py <class 'str'> Process finished with exit code 0
反序列化
# Author:Sean sir import json f = open('序列化存放文件','r') data = f.read() f.close() print(data,type(data)) data_2 = (json.loads(data)) print(data_2['age']) # 输出 {"salary": 9999, "name": "sean", "age": 28, "job": "it"} <class 'str'> 28 Process finished with exit code 0
上面这种使用json方法,我们可以把简单的字典、数组等序列化到文件中,但是当存放一些比较复杂的东西就比较困难了,如果想存放的话我们将适用pickle,下面继续讲解pickle这个序列化的方法。
pickle
我们用json来处理一个复杂的字典,看有什么效果:
# Author:Sean sir import json def technique(): print('擅长解锁各种姿势') info = { 'name':'sean', 'age':28, 'job':'it', 'salary':9999, 'technique':technique } print(type(json.dumps( info ))) f = open('序列化存放文件','w+') f.write(json.dumps(info)) f.close() # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/序列化.py Traceback (most recent call last): File "/Users/sean/python/s14/课堂/d4/序列化.py", line 12, in <module> print(type(json.dumps( info ))) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/json/__init__.py", line 230, in dumps return _default_encoder.encode(obj) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/json/encoder.py", line 198, in encode chunks = self.iterencode(o, _one_shot=True) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/json/encoder.py", line 256, in iterencode return _iterencode(o, 0) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/json/encoder.py", line 179, in default raise TypeError(repr(o) + " is not JSON serializable") TypeError: <function technique at 0x101b7aa60> is not JSON serializable
# 报错这不是一个可被json序列化的类型 Process finished with exit code 1
序列化
我们使用pickle来序列化一个交复杂的数据,看代码:
这里和上面的区别在于,pickle序列化的时候,存放的是二进制的文件,所以打开一个文件的时候,我们要以二进制的格式打开
# Author:Sean sir import pickle def technique(): print('擅长解锁各种姿势') info = { 'name':'sean', 'age':28, 'job':'it', 'salary':9999, 'technique':technique } print(type(pickle.dumps(info))) f = open('序列化存放文件','wb+') f.write(pickle.dumps(info)) f.close() # 输出 <class 'bytes'> Process finished with exit code 0
使用dump可以更方便的序列化数据
# Author:Sean sir import pickle def technique(): print('擅长解锁各种姿势') info = { 'name':'sean', 'age':28, 'job':'it', 'salary':9999, 'technique':technique } print(type(pickle.dumps(info))) f = open('序列化存放文件','wb+') pickle.dump(info,f) f.close() # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/序列化.py <class 'bytes'> Process finished with exit code 0
反序列化
# Author:Sean sir import pickle def technique(name): # 这里要说的是,这里需要自己先定义一下和序列化之前的函数名一样的函数,内容可以自己定义, # 执行这个函数的时候,是访问的第二个函数体 print('%s擅长解锁各种姿势' %name) f = open('序列化存放文件','rb') data = f.read() f.close() data_2 = (pickle.loads(data)) print(data_2['age']) data_2['technique']('sean') # 输出 28 sean擅长解锁各种姿势 Process finished with exit code 0
使用load更方便的反序列化
# Author:Sean sir import pickle def technique(name): # 这里要说的是,这里需要自己先定义一下和序列化之前的函数名一样的函数,内容可以自己定义, # 执行这个函数的时候,是访问的第二个函数体 print('%s擅长解锁各种姿势' %name) f = open('序列化存放文件','rb') data_2 = (pickle.load(f)) f.close() print(data_2['age']) data_2['technique']('sean') # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/反序列化.py 28 sean擅长解锁各种姿势 Process finished with exit code 0
二者区别
pickle只能序列化python的代码,而json可以序列化任何语言。
也就是说,如果使用json序列化的文件,拿到java中依旧可以反序列化而pickle不能实现这种功能
dump和load注意事项
在python2中可以dump多次,也可以load多次;先dump进去的,就会被先load出来,这样就会出问题;
在python3中好了,可以dump多次,但是不可以load多次;这样比较好,因为dump和load多次并没有意义,所以切记如果dump的话最好只dump一次,如果想
dump第二次的话,建议把第一次dump的冲掉。----摘抄自大王思想
软件目录结构规范
注:软件目录结构规范内容全部摘抄自大王博客,容我们来细细品味
照抄地址:http://www.cnblogs.com/alex3714/articles/5765046.html
为什么要设计好目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
- 一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
- 另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
目录组织方式
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。在Stackoverflow的这个问题上,能看到大家对Python目录结构的讨论。
这里面说的已经很好了,我也不打算重新造轮子列举各种不同的方式,这里面我说一下我的理解和体会。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
简要解释一下:
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。docs/: 存放一些文档。setup.py: 安装、部署、打包的脚本。requirements.txt: 存放软件依赖的外部Python包列表。README: 项目说明文件。
除此之外,有一些方案给出了更加多的内容。比如LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织,可以参考这篇文章。
下面,再简单讲一下我对这些目录的理解和个人要求吧。
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具setuptools来管理这些事情。这种方式普遍应用于开源项目中。不过这里的核心思想不是用标准化的工具来解决这些问题,而是说,一个项目一定要有一个安装部署工具,能快速便捷的在一台新机器上将环境装好、代码部署好和将程序运行起来。
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
- 安装环境时经常忘了最近又添加了一个新的Python包,结果一到线上运行,程序就出错了。
- Python包的版本依赖问题,有时候我们程序中使用的是一个版本的Python包,但是官方的已经是最新的包了,通过手动安装就可能装错了。
- 如果依赖的包很多的话,一个一个安装这些依赖是很费时的事情。
- 新同学开始写项目的时候,将程序跑起来非常麻烦,因为可能经常忘了要怎么安装各种依赖。
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的文档比较庞大,刚接触的话,可能不太好找到切入点。学习技术的方式就是看他人是怎么用的,可以参考一下Python的一个Web框架,flask是如何写的: setup.py
当然,简单点自己写个安装脚本(deploy.sh)替代setup.py也未尝不可。
requirements.txt
这个文件存在的目的是:
- 方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在
setup.py安装依赖时漏掉软件包。 - 方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明: 点这里。
关于配置文件的使用方法
注意,在上面的目录结构中,没有将conf.py放在源码目录下,而是放在docs/目录下。
很多项目对配置文件的使用做法是:
- 配置文件写在一个或多个python文件中,比如此处的conf.py。
- 项目中哪个模块用到这个配置文件就直接通过
import conf这种形式来在代码中使用配置。
这种做法我不太赞同:
- 这让单元测试变得困难(因为模块内部依赖了外部配置)
- 另一方面配置文件作为用户控制程序的接口,应当可以由用户自由指定该文件的路径。
- 程序组件可复用性太差,因为这种贯穿所有模块的代码硬编码方式,使得大部分模块都依赖
conf.py这个文件。
所以,我认为配置的使用,更好的方式是,
- 模块的配置都是可以灵活配置的,不受外部配置文件的影响。
- 程序的配置也是可以灵活控制的。
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
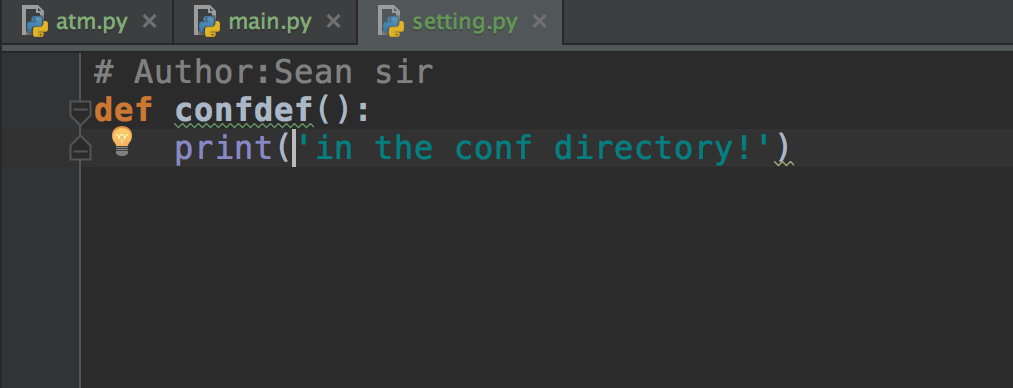
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的。
跨目录的模块调用
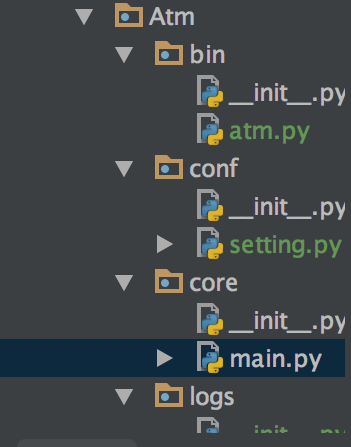
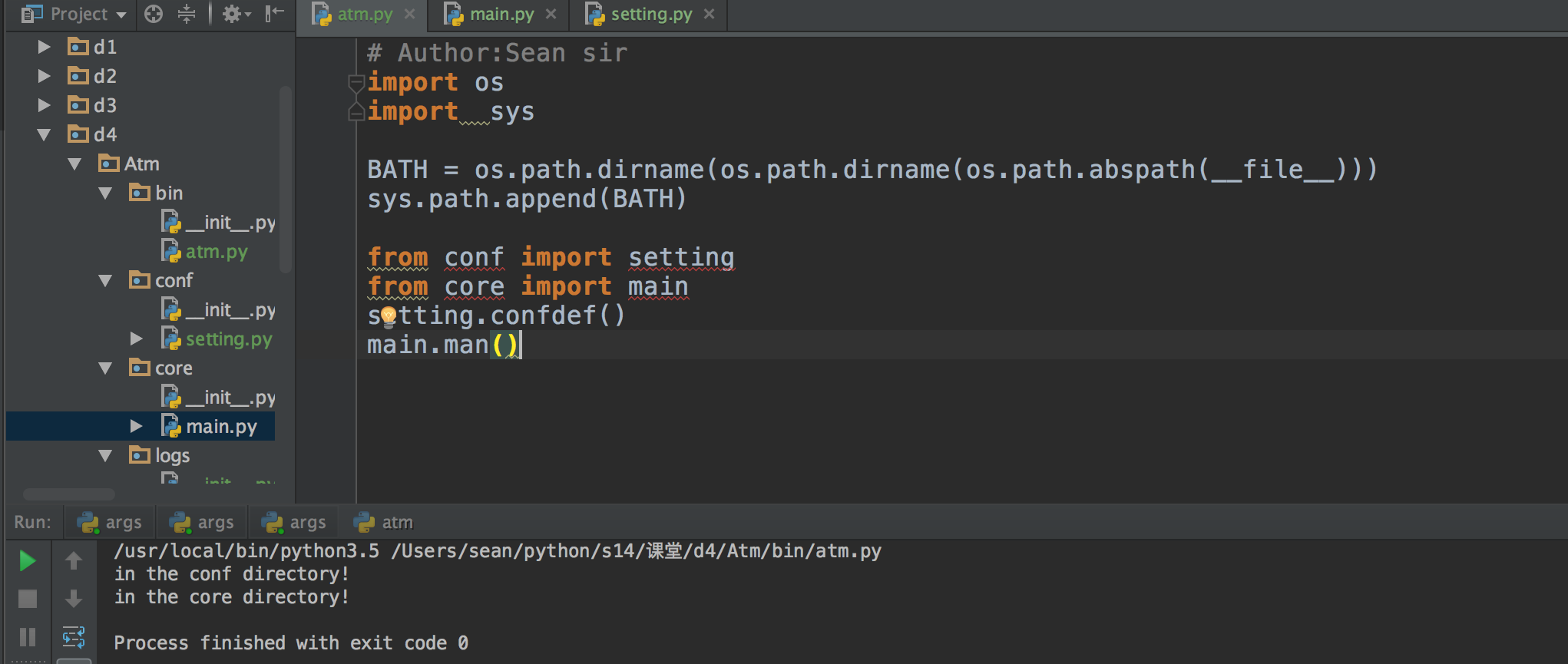
这里只需要讲解3个函数即可,
1.内置函数__file__ 作用:
当执行python pyName的时候,会返回文件当前的相对路径,相对是指执行文件的目录和文件的存放目录存放的相对路径。
bogon:Atm sean$ ls __init__.py bin conf core logs bogon:Atm sean$ python bin/atm.py bin/atm.py
2.os模块中的path.abspath方法作用:
当__file__函数当作一个参数传入到os.path.abspath()方法中,那么将返回py程序的绝对路径
bogon:Atm sean$ python bin/atm.py
/Users/sean/python/s14/课堂/d4/Atm/bin/atm.py
3.os模块中的path.dirname方法作用:
当os.path.abspath(__file__)当作一个参数传入到os.path.dirname函数中,会返回上一级的目录
bogon:Atm sean$ python bin/atm.py
/Users/sean/python/s14/课堂/d4/Atm/bin
如果调用两遍os.path.dirname函数,理所当然就会上出两层目录
bogon:Atm sean$ python bin/atm.py
/Users/sean/python/s14/课堂/d4/Atm
4.既然拿到了代码的最顶层目录,那么我们就可以把当前目录加到系统的环境变量下了,忘了嘛? sys.path打印出来的是一个列表,所以appen就可以了,引入模块系统就会这个目录下照方法啦? 大王威武
BATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BATH)
5.可以直接饮用了哦!
# Author:Sean sir import os import sys BATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BATH) from conf import setting from core import main setting.confdef() main.man() # 输出 /usr/local/bin/python3.5 /Users/sean/python/s14/课堂/d4/Atm/bin/atm.py in the conf directory! in the core directory! Process finished with exit code 0