知识点
- SQL 基本概念
- SQL Context 的生成和使用
- 1.6 版本新API:Datasets
- 常用 Spark SQL 数学和统计函数
- SQL 语句
- Spark DataFrame 文件保存
实验步骤
Spark SQL 是Spark 中用于处理结构化数据的模块。它与基本的Spark RDD API 不同的地方在于其接口提供了更多关于结构化数据的信息,能够更好地应用于计算过程。这些额外的信息也能够帮助系统进行优化,从而提高计算的性能。
这个体系中,DataFrame是非常重要的一种数据结构。 在实验楼之前发布的课程中,《Spark 大讲堂之 DataFrame 详解》为你讲述了关于 DataFrame 的各方面知识。建议在此之前对 DataFrame 有所深入了解,否则你也可以将其简单理解为一个由命名列组成的分布式数据集。
我们可以通过文件、Hive表以及各类数据库或者当前环境中的RDD来创建DataFrame。这在之前的课程中已有详细的探讨,此处不再 赘述。本课程主要通过SQL Context对象,以已有的RDD来创建DataFrame,大家可以在具体的代码中了解创建过程。
万物始于 SQL Context
对于整个Spark SQL 里错综复杂的功能来说,程序的入口便是 SQLContext 类(或是该类的子类)。而盆地一个 SQLContext对象,则需要SparkContext。
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
新的接口: Datasets
Spark 从1.6版本起,引入了一个实验性的接口,名为Dataset。提供该接口的目的是为了在RDD的特性上,再集成SPark SQL 的一些优化操作引擎。Dataset可以由JVM对象构造,并且可以通过map、flatMap、filter等函数对其进行计算。
鉴于它的构造特点,因此我们只能使用Scala或者 Java 语言来使用它的API。对于Python的支持可能会在后续的SPark 版本中提供。
Dataset 与 RDD 十分类似,一个简单的创建方法如下:
请输入下面的代码来创建Dataset。
首先是通过已有的变量来创建。
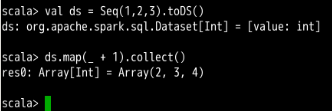
// 数据类型的转化是自动完成的,大多数据情况下可以直接使用 toDS() 函数创建 Dataset
val ds = Seq(1,2,3).toDS()
//Dataset 支持 map等操作
ds.map(_ + 1).collect()
执行结果如下:
我们还可以通过 Case Class 来创建Dataset:
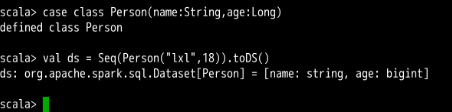
//构造一个 case class
case class Person(name: String, age: Long)
//使用 case class 创建 Dataset
val ds = Seq(Person("lxl",18)).toDS()
执行结果如下:
Select函数的应用:一些数学和统计函数
Spark SQL 中最常用的函数,莫过于检索函数 select()。就像其他语言中的检索一样,你可以通过该函数实现一些数据上的CURD操作。
Spark SQL API 中涉及到检索的函数主要有:
select(col: String, cols: String*):该函数基于已有的列名进行查询,返回一个 DataFrame 对象。使用方法如df.select($"colA", $"colB")。select(cols: Column*):该函数可以基于表达式来进行查询,返回一个 DataFrame 对象。使用方法如df.select($"colA", $"colB" + 1)。selectExpr(exprs: String*):该函数的参数可以是一句完整的SQL语句,仍然返回一个 DataFrame 对象。具体的 SQL 语法规则可以参考通用的 SQL 规则。该函数使用方法如df.selectExpr("colA", "colB as newName", "abs(colC)"),当然你也可以进行表达式的组合,如df.select(expr("colA"), expr("colB as newName"), expr("abs(colC)"))。
接下来,我们结合一些数据和统计的例子,来学习如何使用这些SQL函数(主要为select 函数)。
下面部分内容翻译自博文《Statistical and Mathematical Functions with DataFrames in Apache Spark》,内容上有改编。原文提供了 Python 代码。实验楼为你提供 Scala 版本的代码,可直接在 Spark Shell 中使用
产生随机数据
在很多时候,我们可能需要去验证一个算法(无论是自己设计的还是现有的),或者是实现一个随机的算法(例如随机投影)。这些时候我们手头上又找不到合适的数据集怎么办?产生随机的数据就是一个很好的选择。
在Spark SQL中,org.apache.spark.sql.functions 包提供了一些实用的函数,其中就包含了产生随机数的函数。它们可以从一个特定的分布中提取出独立同分布值,例如产生均匀分布随机数的函数 rand() 和产道理从正态分布的随机数的函数 randn()。我们可以通过下面的例子来简单使用一下随机数产生函数。
请按照下面的步骤完成操作。
首先我们需要产生一个数据框(DataFrame)来存放随机数
在获得 SQL Context 对象 sqlContext 后,使用range 方法产生一个指定范围大小的DataFrame。
// 创建含有单列数据的 DataFrame
val df = sqlContext.range(0,16)
执行结果如下:

接着,用show函数查看当前DataFrame 的内容(如果数据条目超过20个,默认只会显示前20行)。
df.show()
执行结果如下:

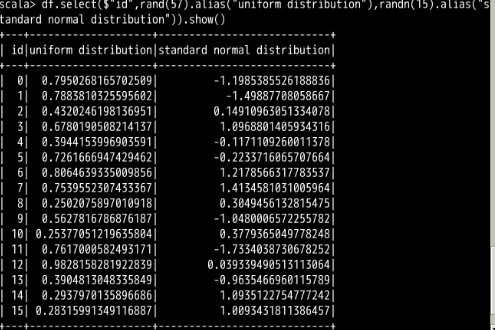
最后,使用均匀分布函数 rand 和标准正态分布函数 randn 来随机产生其他两列的数据,并用show函数查看结果。两个随机数函数中的参数为种子值(Seed)。
df.select($"id",rand(57).alias("uniform distribution"),randn(15).alias("standard normal distribution")).show()
执行结果如下(由于是随机数,列表中的数值可能不同):
数据概要和描述性统计
在实际工程中,我们在导入数据后,通常需要通过数据的描述性统计信息来验证这些数据是否是我们想要的那些。数据的描述性统计信息能够刻画一堆数据的分布情况,例如非空实体的数量、所有数据的平均值和标准差、每个数值列的最大最小值等等。
这一切都只需要通过一个简单的 describe() 函数来实现。
首先我们还是需要产生一个 DataFrame ,这次仍然可以通过随机的方式来产生。代码如下:
val df1 = sqlContext.range(0,15).withColumn("uniform distribution",rand(99)).withColumn("standard normal distribution",randn(234))
执行结果如下:

接下来,调用 describe() 函数来计算描述性信息,并通过 show() 函数展现出来。代码如下:
df1.describe().show()
执行结果如下图所示(数值可能不同):
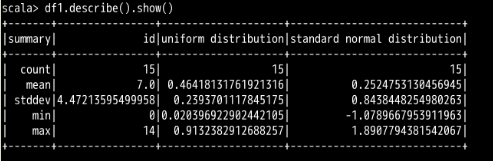
试想:如果需要计算的 DataFrame 体量非常大,我们为了得到这个描述信息就可能需要花费更多的时间。因此,在选择计算对象的时候,我们可以将范围缩小在某一列上。达到这个目的只需要在
describe() 函数中填入指定的列名即可。 不妨试试下面的代码:
df1.describe("uniform distribution").show()
执行结果如下图所示:
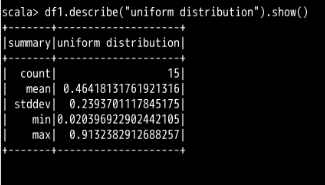
我们可以看到结果中只针对
uniform distribution 一列进行了描述性信息的计算。 当然,除了通过
describe() 函数去进行数据分析,我们也可以把这些描述性信息的计算手段用到一个普通的 select 检索过程中。在需要什么信息的时候,就填入相应的计算函数即可,如下面的代码: //这里的 uniform distribution 为列名
df1.select(mean("uniform distribution"),min("uniform distribution"),max("uniform distribution")).show()
执行结果如下图所示:

样本协方差和相关性计算
对于两个变量A和B而言,协方差表示了它们总体的误差大小。如果协方差为正数,说明变量A可能会随着变量B的增加面增加;如果协方差为负数,则说明变量A(或B)随着变量B(或A)的增加而减少。
现在,我们随机产生两个列的数据,从而创建一个 DataFrame:
// 这里我们使用了 withColumn 方法来为已有的DataFrame 附加列数据。每一次调用都会附加想应的列。
val df2 = sqlContext.range(0,18).withColumn("data1",rand(1290)).withColumn("data2",rand(5223))
执行结果如下:

接下来,使用 cov() 函数来计算任意两列之间的样本协方差。代码如下:
df2.stat.cov("data1","data2")
执行结果如下图所示:

可以观察到,这个样本协方差的数值十分地小,几乎接近于0。这也说明了随机产生的
data1 列与 data2 列的数据之间的差异较小。 如果是两个相同的列来比较呢?我们用
id 列尝试一下: df2.stat.cov("id","id)
计算结果如下图所示(因为有取样过程,所有数据值可能不同):
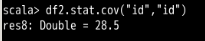
可以看到这个数字非常地大。试想一下造成这二者巨大区别的原因是什么呢?
最后我们再来计算一下数据的相关性。相关性是协方差的归一化度量,因此它能够更好地被理解,因为它的范围始终在正负的 0 到 1 之间。
计算两个不同列的相关性:
df2.stat.corr("data1","data2")
执行结果如下图所示:

同样地,计算两个相同列的相关性:
df2.stat.corr("id","id")
计算结果如下图所示:

此时两个相同列的相关性肯定就为 1 了。
SparkSQL案例
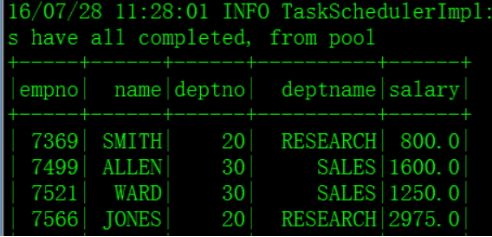
需求:将Hive中的emp表与mysql中的dept表进行连接查询
一、启动spark-shell
spark2-shell --master local[2] --driver-class-path /var/lib/sqoop/mysql-connector-java-5.1.46-bin.jar
或
spark2-shell --master local[2] --jars /var/lib/sqoop/mysql-connector-java-5.1.46-bin.jar
二、引包并建立JDBC连接 val url = "jdbc:mysql://vin01:3306/test?user=root&password=123456"
import java.util.Properties
val props = new Properties() 
三、创建DataFrame
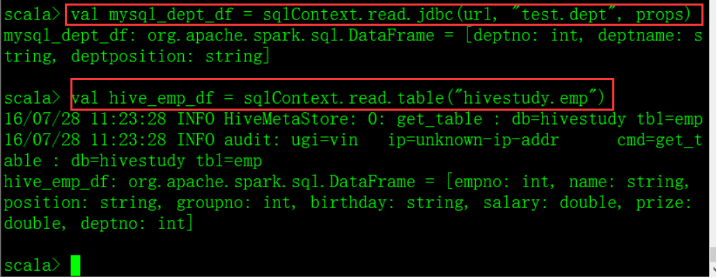
四、jion val join_df = hive_emp_df.join(mysql_dept_df, "deptno")

五、 将jion出来的值注册为临时表,方便查询 join_df.registerTempTable("join_emp_dept")
查询: sqlContext.sql("select empno, ename, deptno, deptname, sal from join_emp_dept order by empno").show