1.DBSCAN介绍
密度聚类方法的指导思想是,只要样本点的密度大于某阈值,则将该样本添加到最近的簇中。
这类算法能克服基于距离的算法只能发现“类圆形”的聚类的缺点,可发现任意形状的聚类,且对噪声数据不敏感。但计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
- DBSCAN
- 密度最大值算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。

基于密度这点有什么好处呢,我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面两张图,环形和不规则形,这个时候,那些传统的聚类算法显然就悲剧了。于是就思考,样本密度大的成一类呗。呐这就是DBSCAN聚类算法
推荐一个很形象的描述DBSCAN的网站,可视化
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
2.DBSCAN的重要参数
(1)eps 相当于圈的半径,越大越小都不好,自己合适调节
(2)min_samples 相当于一个圈中最少的样本数,不到的话,就被划分为离散点
(3)metric

3.DBSCAN案例
1 import warnings 2 warnings.filterwarnings('ignore') 3 import numpy as np 4 import matplotlib.pyplot as plt 5 %matplotlib inline 6 7 from sklearn import datasets 8 from sklearn.cluster import DBSCAN,KMeans 9 # noise控制叠加的噪声的大小 10 X,y = datasets.make_circles(n_samples=1000,noise = 0.1,factor = 0.3) 11 12 # centers=[[1.5,1.5]] 坐标位置,在1.5,1.5生成 13 X3,y3 = datasets.make_blobs(n_samples=500,n_features=2,centers=[[1.5,1.5]],cluster_std=0.2) 14 15 # 将两个数据级联 16 X = np.concatenate([X,X3]) 17 18 y = np.concatenate([y,y3+2]) 19 20 plt.scatter(X[:,0],X[:,1],c = y)
生成的数据:

1 # kmeans 2 # 有缺陷 3 kmeans = KMeans(3) 4 kmeans.fit(X) 5 y_ = kmeans.predict(X) 6 plt.scatter(X[:,0],X[:,1],c = y_)
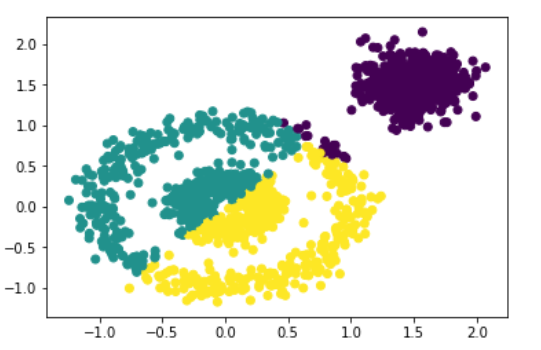
kmeans形成的:可以看出,效果很不好
1 # dbcan 2 dbscan = DBSCAN(eps = 0.15,min_samples=5) 3 dbscan.fit(X) 4 # y_ = dbscan.fit_predict(X) 5 y_ = dbscan.labels_ 6 plt.scatter(X[:,0],X[:,1],c = y_)
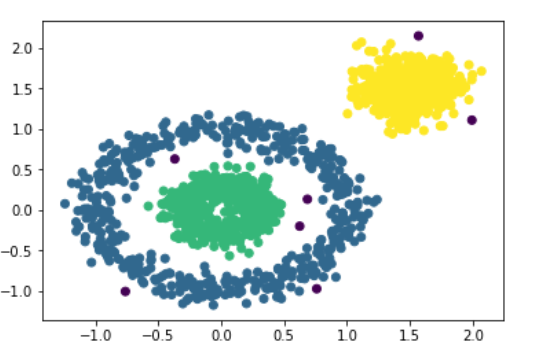
可以看出来,使用dbscan效果明显不错
之后,可以再使用之前kmeans中的评测指标才评测一下
4.总结一下DBSCAN流程:
-
DBSCAN 从一个没有被访问过的任意起始数据点开始。这个点的邻域是用距离 ε(ε 距离内的所有点都是邻域点)提取的。
-
如果在这个邻域内有足够数量的点(根据 minPoints),则聚类过程开始,并且当前数据点成为新簇的第一个点。否则,该点将会被标记为噪声(稍后这个噪声点可能仍会成为聚类的一部分)。在这两种情况下,该点都被标记为「已访问」。
-
对于新簇中的第一个点,其 ε 距离邻域内的点也成为该簇的一部分。这个使所有 ε 邻域内的点都属于同一个簇的过程将对所有刚刚添加到簇中的新点进行重复。
-
重复步骤 2 和 3,直到簇中所有的点都被确定,即簇的 ε 邻域内的所有点都被访问和标记过。
-
一旦我们完成了当前的簇,一个新的未访问点将被检索和处理,导致发现另一个簇或噪声。重复这个过程直到所有的点被标记为已访问。由于所有点都已经被访问,所以每个点都属于某个簇或噪声。
5.DBSCAN的优缺点
优点:
DBSCAN 与其他聚类算法相比有很多优点。首先,它根本不需要固定数量的簇。它也会将异常值识别为噪声,而不像均值漂移,即使数据点非常不同,也会简单地将它们分入簇中。另外,它能够很好地找到任意大小和任意形状的簇。
缺点:
DBSCAN 的主要缺点是当簇的密度不同时,它的表现不如其他聚类算法。这是因为当密度变化时,用于识别邻域点的距离阈值 ε 和 minPoints 的设置将会随着簇而变化。这个缺点也会在非常高维度的数据中出现,因为距离阈值 ε 再次变得难以估计。
补充:
密度最大值聚类:其实就是看哪个簇的密度最大的
高局部密度点距离:换句话说,就是找比你有钱的距离你最近的人的距离

根据高局部密度点距离,可以识别簇中心:
