相对高并发一样,速度都是优化出来的,在高并发处理的时候,通常采用的是redis缓存,全文搜索引擎,数据库本身优化,sql优化,磁盘优化
看如下图:
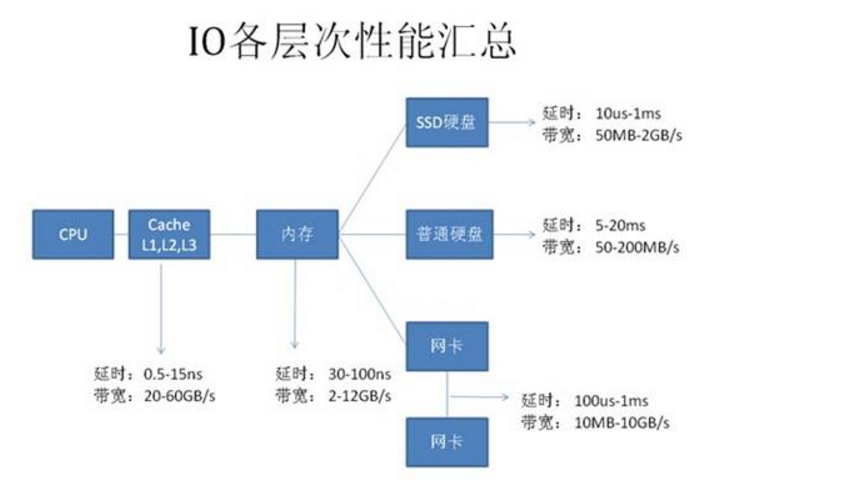
所以可以得出的思想就是:
这个优化法则归纳为5个层次:
1、 减少数据访问(减少磁盘访问)
2、 返回更少数据(减少网络传输或磁盘访问)
3、 减少交互次数(减少网络传输)
4、 减少服务器CPU开销(减少CPU及内存开销)
5、 利用更多资源(增加资源)
1、减少数据访问
1.1、创建并使用正确的索引
数据库索引的原理非常简单,但在复杂的表中真正能正确使用索引的人很少,即使是专业的DBA也不一定能完全做到最优。
索引会大大增加表记录的DML(INSERT,UPDATE,DELETE)开销,正确的索引可以让性能提升100,1000倍以上,不合理的索引也可能会让性能下降100倍,因此在一个表中创建什么样的索引需要平衡各种业务需求。
索引常见问题:
索引有哪些种类?
常见的索引有B-TREE索引、位图索引、全文索引,位图索引一般用于数据仓库应用,全文索引由于使用较少,这里不深入介绍。B-TREE索引包括很多扩展类型,如组合索引、反向索引、函数索引等等,以下是B-TREE索引的简单介绍:
B-TREE索引也称为平衡树索引(Balance Tree),它是一种按字段排好序的树形目录结构,主要用于提升查询性能和唯一约束支持。B-TREE索引的内容包括根节点、分支节点、叶子节点。
叶子节点内容:索引字段内容+表记录ROWID
根节点,分支节点内容:当一个数据块中不能放下所有索引字段数据时,就会形成树形的根节点或分支节点,根节点与分支节点保存了索引树的顺序及各层级间的引用关系。
一个普通的BTREE索引结构示意图如下所示:
1.2、只通过索引访问数据
有些时候,我们只是访问表中的几个字段,并且字段内容较少,我们可以为这几个字段单独建立一个组合索引,这样就可以直接只通过访问索引就能得到数据,一般索引占用的磁盘空间比表小很多,所以这种方式可以大大减少磁盘IO开销。
如:select id,name from company where type='2';
如果这个SQL经常使用,我们可以在type,id,name上创建组合索引
create index my_comb_index on company(type,id,name);
有了这个组合索引后,SQL就可以直接通过my_comb_index索引返回数据,不需要访问company表。
还是拿字典举例:有一个需求,需要查询一本汉语字典中所有汉字的个数,如果我们的字典没有目录索引,那我们只能从字典内容里一个一个字计数,最后返回结果。如果我们有一个拼音目录,那就可以只访问拼音目录的汉字进行计数。如果一本字典有1000页,拼音目录有20页,那我们的数据访问成本相当于全表访问的50分之一。
切记,性能优化是无止境的,当性能可以满足需求时即可,不要过度优化。在实际数据库中我们不可能把每个SQL请求的字段都建在索引里,所以这种只通过索引访问数据的方法一般只用于核心应用,也就是那种对核心表访问量最高且查询字段数据量很少的查询。
1.3、优化SQL执行计划
SQL执行计划是关系型数据库最核心的技术之一,它表示SQL执行时的数据访问算法。由于业务需求越来越复杂,表数据量也越来越大,程序员越来越懒惰,SQL也需要支持非常复杂的业务逻辑,但SQL的性能还需要提高,因此,优秀的关系型数据库除了需要支持复杂的SQL语法及更多函数外,还需要有一套优秀的算法库来提高SQL性能。
目前ORACLE有SQL执行计划的算法约300种,而且一直在增加,所以SQL执行计划是一个非常复杂的课题,一个普通DBA能掌握50种就很不错了,就算是资深DBA也不可能把每个执行计划的算法描述清楚。虽然有这么多种算法,但并不表示我们无法优化执行计划,因为我们常用的SQL执行计划算法也就十几个,如果一个程序员能把这十几个算法搞清楚,那就掌握了80%的SQL执行计划调优知识。
由于篇幅的原因,SQL执行计划需要专题介绍,在这里就不多说了。
2、返回更少的数据
2.1、数据分页处理
一般数据分页方式有:
2.1.1、客户端(应用程序或浏览器)分页
将数据从应用服务器全部下载到本地应用程序或浏览器,在应用程序或浏览器内部通过本地代码进行分页处理
优点:编码简单,减少客户端与应用服务器网络交互次数
缺点:首次交互时间长,占用客户端内存
适应场景:客户端与应用服务器网络延时较大,但要求后续操作流畅,如手机GPRS,超远程访问(跨国)等等。
2.1.2、应用服务器分页
将数据从数据库服务器全部下载到应用服务器,在应用服务器内部再进行数据筛选。以下是一个应用服务器端Java程序分页的示例:
List list=executeQuery(“select * from employee order by id”);
Int count= list.size();
List subList= list.subList(10, 20);
优点:编码简单,只需要一次SQL交互,总数据与分页数据差不多时性能较好。
缺点:总数据量较多时性能较差。
适应场景:数据库系统不支持分页处理,数据量较小并且可控。
2.1.3、数据库SQL分页
采用数据库SQL分页需要两次SQL完成
一个SQL计算总数量
一个SQL返回分页后的数据
优点:性能好
缺点:编码复杂,各种数据库语法不同,需要两次SQL交互。
oracle数据库一般采用rownum来进行分页,常用分页语法有如下两种:
直接通过rownum分页:
select * from (
select a.*,rownum rn from
(select * from product a where company_id=? order by status) a
where rownum<=20)
where rn>10;
数据访问开销=索引IO+索引全部记录结果对应的表数据IO
采用rowid分页语法
优化原理是通过纯索引找出分页记录的ROWID,再通过ROWID回表返回数据,要求内层查询和排序字段全在索引里。
create index myindex on product(company_id,status);
select b.* from (
select * from (
select a.*,rownum rn from
(select rowid rid,status from product a where company_id=? order by status) a
where rownum<=20)
where rn>10) a, product b
where a.rid=b.rowid;
数据访问开销=索引IO+索引分页结果对应的表数据IO
实例:
一个公司产品有1000条记录,要分页取其中20个产品,假设访问公司索引需要50个IO,2条记录需要1个表数据IO。
那么按第一种ROWNUM分页写法,需要550(50+1000/2)个IO,按第二种ROWID分页写法,只需要60个IO(50+20/2);
2.2、只返回需要的字段
通过去除不必要的返回字段可以提高性能,例:
调整前:select * from product where company_id=?;
调整后:select id,name from product where company_id=?;
优点:
1、减少数据在网络上传输开销
2、减少服务器数据处理开销
3、减少客户端内存占用
4、字段变更时提前发现问题,减少程序BUG
5、如果访问的所有字段刚好在一个索引里面,则可以使用纯索引访问提高性能。
缺点:增加编码工作量
由于会增加一些编码工作量,所以一般需求通过开发规范来要求程序员这么做,否则等项目上线后再整改工作量更大。
如果你的查询表中有大字段或内容较多的字段,如备注信息、文件内容等等,那在查询表时一定要注意这方面的问题,否则可能会带来严重的性能问题。如果表经常要查询并且请求大内容字段的概率很低,我们可以采用分表处理,将一个大表分拆成两个一对一的关系表,将不常用的大内容字段放在一张单独的表中。如一张存储上传文件的表:
T_FILE(ID,FILE_NAME,FILE_SIZE,FILE_TYPE,FILE_CONTENT)
我们可以分拆成两张一对一的关系表:
T_FILE(ID,FILE_NAME,FILE_SIZE,FILE_TYPE)
T_FILECONTENT(ID, FILE_CONTENT)
通过这种分拆,可以大大提少T_FILE表的单条记录及总大小,这样在查询T_FILE时性能会更好,当需要查询FILE_CONTENT字段内容时再访问T_FILECONTENT表。
3、减少交互次数
3.1、batch DML
数据库访问框架一般都提供了批量提交的接口,jdbc支持batch的提交处理方法,当你一次性要往一个表中插入1000万条数据时,如果采用普通的executeUpdate处理,那么和服务器交互次数为1000万次,按每秒钟可以向数据库服务器提交10000次估算,要完成所有工作需要1000秒。如果采用批量提交模式,1000条提交一次,那么和服务器交互次数为1万次,交互次数大大减少。采用batch操作一般不会减少很多数据库服务器的物理IO,但是会大大减少客户端与服务端的交互次数,从而减少了多次发起的网络延时开销,同时也会降低数据库的CPU开销。
3.2 缓存概念
通过redis等内存工具将数据库缓存到内存中
3.3 全文搜索 es
可以将数据进行导入es中进行缓存,然后查询只是在es中查询,可以减少对数据库的交互
这个是很早之前总结的,一直在有道云笔记上,希望大家拍砖.