1.导入相应的包
import requests from lxml import etree
2.原始ur
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
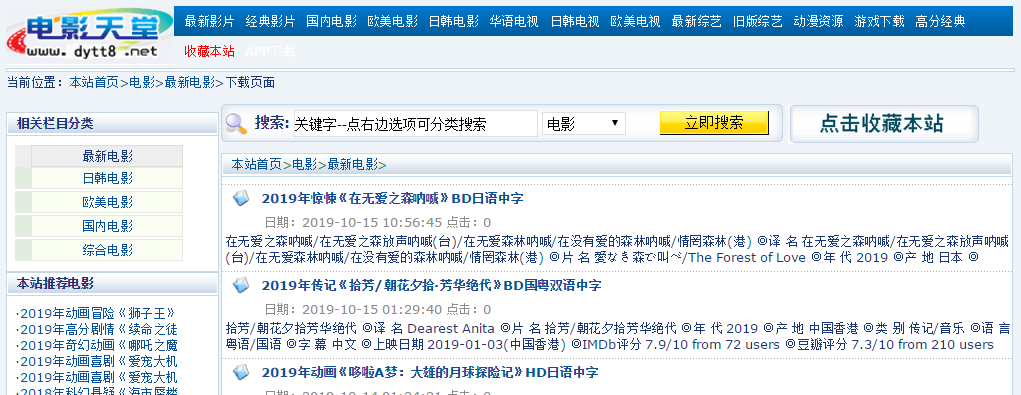
我们要爬取的是最新电影,在该界面中,我们发现,具体的信息存储在每个名字的链接中,因此我们要获取所有电影的链接才能得到电影的信息。同时我们观察url,发现
list_23_1,最后的1是页面位于第几页。右键点击其中一个电影的名字-检查。

我们发现,其部分连接位于具有class="tbspan"的table的<b>中,首先建立一个函数,用来得到所有的链接:
#用于补全url base_url="https://www.dytt8.net" def get_domain_urls(url): response=requests.get(url=url,headers=headers) text=response.text html=etree.HTML(text) #找到具有class="tbspan"的table下的所有a下面的href里面的值 detail_urls=html.xpath("//table[@class='tbspan']//a/@href") #将url进行补全 detail_urls=map(lambda url:base_url+url,detail_urls) return detail_urls
我们输出第1页中的所有url结果:
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html" for i in get_domain_urls(url): print(i)
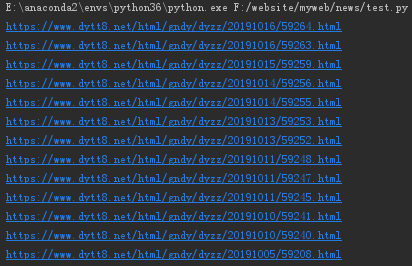
我们随便进入第一个链接:

按下F12,发现这些信息基本上都在div id="Zoom"中,接下来我们就可以对该界面进行解析。

def parse_detail_page(url): movie={} response=requests.get(url,headers=headers) text=response.content.decode("GBK") html=etree.HTML(text) zoom=html.xpath("//div[@id='Zoom']")[0] infos=zoom.xpath("//text()") def parse_info(info,rule): return info.replace(rule,"").lstrip() for k,v in enumerate(infos): if v.startswith("◎译 名"): v=parse_info(v,"◎译 名").split("/")[0] movie["name"]=v elif v.startswith("◎产 地"): v=parse_info(v,"◎产 地") movie["country"]=v elif v.startswith("◎类 别"): v=parse_info(v,"◎类 别") movie["category"]=v elif v.startswith("◎豆瓣评分"): v=parse_info(v,"◎豆瓣评分").split("/")[0] movie["douban"]=v elif v.startswith("◎导 演"): v=parse_info(v,"◎导 演") movie["director"]=v elif v.startswith("◎主 演"): v=parse_info(v,"◎主 演") actors=[v] for x in range(k+1,len(infos)): actor=infos[x].strip() if actor.startswith("◎"): break actors.append(actor) movie["actors"]=actors elif v.startswith("◎简 介"): profile="" for x in range(k+1,len(infos)): tmp=infos[x].strip() if tmp.startswith("【下载地址】"): break else: profile=profile+tmp movie["profile"]=profile down_url=html.xpath("//td[@bgcolor='#fdfddf']/a/@href") movie["down_url"]=down_url return movie
最后将这两个整合进一个爬虫中:
def spider(): domain_url="https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html" movies=[] for i in range(1,2): page=str(i) url=domain_url.format(page) detail_urls=get_domain_urls(url) for detail_url in detail_urls: movie = parse_detail_page(detail_url) movies.append(movie) print(movies)
运行爬虫,得到以下结果(在Json查看器中进行格式化):
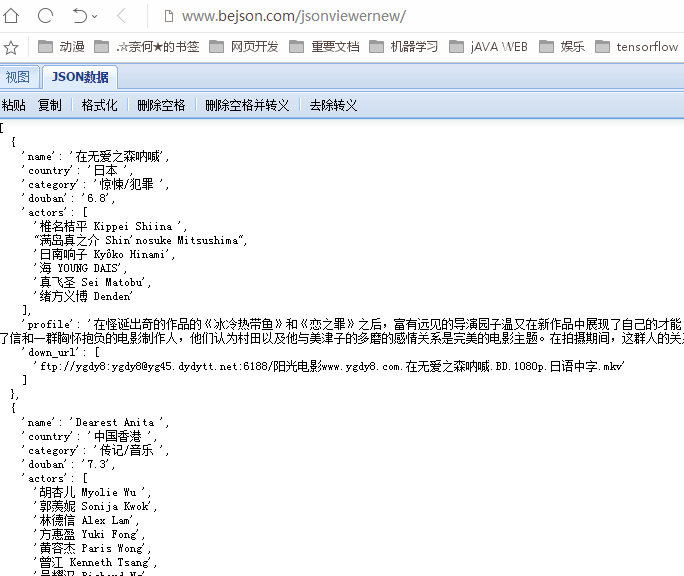
至此,一个简单的电影爬虫就完成了。