2020.3.10
发现数据集没有完整的上传到谷歌的colab上去,我说怎么计算出来的step不对劲。
测试集是完整的。
训练集中cat的确是有10125张图片,而dog只有1973张,所以完成一个epoch需要迭代的次数为:
(10125+1973)/128=94.515625,约等于95。
顺便提一下,有两种方式可以计算出数据集的量:
第一种:print(len(train_dataset))
第二种:在../dog目录下,输入ls | wc -c
今天重新上传dog数据集。
分割线-----------------------------------------------------------------
数据集下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
创建数据集:https://www.cnblogs.com/xiximayou/p/12398285.html
读取数据集:https://www.cnblogs.com/xiximayou/p/12422827.html
进行训练:https://www.cnblogs.com/xiximayou/p/12448300.html
epoch、batchsize、step之间的关系:https://www.cnblogs.com/xiximayou/p/12405485.html
之前我们已经可以训练了,接下来我们要保存训练的模型,同时加载保存好的模型,并继续熏训练。
目前的结构:
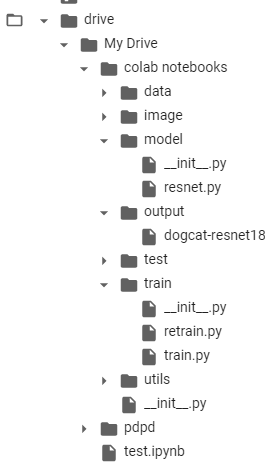
output是我们新建的保存模型的文件夹。
我们首先修改下训练时的代码:
import sys sys.path.append("/content/drive/My Drive/colab notebooks") from utils import rdata from model import resnet import torch.nn as nn import torch import numpy as np import torchvision np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) torch.backends.cudnn.deterministic = True #torch.backends.cudnn.benchmark = False torch.backends.cudnn.benchmark = True device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') train_loader,test_loader,train_data,test_data=rdata.load_dataset() model =torchvision.models.resnet18(pretrained=False) model.fc = nn.Linear(model.fc.in_features,2,bias=False) model.cuda() #print(model) #定义训练的epochs num_epochs=2 #定义学习率 learning_rate=0.01 #定义损失函数 criterion=nn.CrossEntropyLoss() #optimizer #=torch.optim.Adam(model.parameters(),lr=learning_rate) #定义优化方法,简单起见,就是用带动量的随机梯度下降 optimizer = torch.optim.SGD(params=model.parameters(), lr=0.1, momentum=0.9, weight_decay=1*1e-4) # Train the model total_step = len(train_loader) def train(): total_step = len(train_loader) for epoch in range(num_epochs): tot_loss = 0.0 correct = 0 for i ,(images, labels) in enumerate(train_loader): images = images.cuda() labels = labels.cuda() # Forward pass outputs = model(images) _, preds = torch.max(outputs.data,1) loss = criterion(outputs, labels) # Backward and optimizer optimizer.zero_grad() loss.backward() optimizer.step() tot_loss += loss.data if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item())) correct += torch.sum(preds == labels.data).to(torch.float32) ### Epoch info #### epoch_loss = tot_loss/len(train_data) print('train loss: {:.4f}'.format(epoch_loss)) epoch_acc = correct/len(train_data) print('train acc: {:.4f}'.format(epoch_acc)) state = { 'model': model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch': epoch, 'train_loss':epoch_loss, 'train_acc':epoch_acc, } save_path="/content/drive/My Drive/colab notebooks/output/" torch.save(state,save_path+'/dogcat-resnet18'+".t7") train()
这里我们只设置训练2个epoch,在训练完2个epoch之后,我们将模型的参数、模型的优化器、当前epoch、当前损失、当前准确率都保存下来。
看下运行结果:
Epoch: [1/2], Step: [2/95], Loss: 2.9102 Epoch: [1/2], Step: [4/95], Loss: 3.1549 Epoch: [1/2], Step: [6/95], Loss: 3.2473 Epoch: [1/2], Step: [8/95], Loss: 0.7810 Epoch: [1/2], Step: [10/95], Loss: 1.0438 Epoch: [1/2], Step: [12/95], Loss: 1.9787 Epoch: [1/2], Step: [14/95], Loss: 0.4577 Epoch: [1/2], Step: [16/95], Loss: 1.2512 Epoch: [1/2], Step: [18/95], Loss: 1.6558 Epoch: [1/2], Step: [20/95], Loss: 0.9157 Epoch: [1/2], Step: [22/95], Loss: 0.9040 Epoch: [1/2], Step: [24/95], Loss: 0.4742 Epoch: [1/2], Step: [26/95], Loss: 1.3849 Epoch: [1/2], Step: [28/95], Loss: 1.0432 Epoch: [1/2], Step: [30/95], Loss: 0.7371 Epoch: [1/2], Step: [32/95], Loss: 0.5443 Epoch: [1/2], Step: [34/95], Loss: 0.7765 Epoch: [1/2], Step: [36/95], Loss: 0.6239 Epoch: [1/2], Step: [38/95], Loss: 0.7696 Epoch: [1/2], Step: [40/95], Loss: 0.4846 Epoch: [1/2], Step: [42/95], Loss: 0.4718 Epoch: [1/2], Step: [44/95], Loss: 0.4329 Epoch: [1/2], Step: [46/95], Loss: 0.4785 Epoch: [1/2], Step: [48/95], Loss: 0.4181 Epoch: [1/2], Step: [50/95], Loss: 0.4522 Epoch: [1/2], Step: [52/95], Loss: 0.4564 Epoch: [1/2], Step: [54/95], Loss: 0.4918 Epoch: [1/2], Step: [56/95], Loss: 0.5383 Epoch: [1/2], Step: [58/95], Loss: 0.4193 Epoch: [1/2], Step: [60/95], Loss: 0.6306 Epoch: [1/2], Step: [62/95], Loss: 0.4218 Epoch: [1/2], Step: [64/95], Loss: 0.4041 Epoch: [1/2], Step: [66/95], Loss: 0.3234 Epoch: [1/2], Step: [68/95], Loss: 0.5065 Epoch: [1/2], Step: [70/95], Loss: 0.3892 Epoch: [1/2], Step: [72/95], Loss: 0.4366 Epoch: [1/2], Step: [74/95], Loss: 0.5148 Epoch: [1/2], Step: [76/95], Loss: 0.4604 Epoch: [1/2], Step: [78/95], Loss: 0.4509 Epoch: [1/2], Step: [80/95], Loss: 0.5301 Epoch: [1/2], Step: [82/95], Loss: 0.4074 Epoch: [1/2], Step: [84/95], Loss: 0.4750 Epoch: [1/2], Step: [86/95], Loss: 0.3800 Epoch: [1/2], Step: [88/95], Loss: 0.4604 Epoch: [1/2], Step: [90/95], Loss: 0.4808 Epoch: [1/2], Step: [92/95], Loss: 0.4283 Epoch: [1/2], Step: [94/95], Loss: 0.4829 train loss: 0.0058 train acc: 0.8139 Epoch: [2/2], Step: [2/95], Loss: 0.4499 Epoch: [2/2], Step: [4/95], Loss: 0.4735 Epoch: [2/2], Step: [6/95], Loss: 0.3268 Epoch: [2/2], Step: [8/95], Loss: 0.4393 Epoch: [2/2], Step: [10/95], Loss: 0.4996 Epoch: [2/2], Step: [12/95], Loss: 0.5331 Epoch: [2/2], Step: [14/95], Loss: 0.5996 Epoch: [2/2], Step: [16/95], Loss: 0.3580 Epoch: [2/2], Step: [18/95], Loss: 0.4898 Epoch: [2/2], Step: [20/95], Loss: 0.3991 Epoch: [2/2], Step: [22/95], Loss: 0.5849 Epoch: [2/2], Step: [24/95], Loss: 0.4977 Epoch: [2/2], Step: [26/95], Loss: 0.3710 Epoch: [2/2], Step: [28/95], Loss: 0.4745 Epoch: [2/2], Step: [30/95], Loss: 0.4736 Epoch: [2/2], Step: [32/95], Loss: 0.4986 Epoch: [2/2], Step: [34/95], Loss: 0.3944 Epoch: [2/2], Step: [36/95], Loss: 0.4616 Epoch: [2/2], Step: [38/95], Loss: 0.5462 Epoch: [2/2], Step: [40/95], Loss: 0.3726 Epoch: [2/2], Step: [42/95], Loss: 0.4639 Epoch: [2/2], Step: [44/95], Loss: 0.3709 Epoch: [2/2], Step: [46/95], Loss: 0.4054 Epoch: [2/2], Step: [48/95], Loss: 0.4791 Epoch: [2/2], Step: [50/95], Loss: 0.4516 Epoch: [2/2], Step: [52/95], Loss: 0.5251 Epoch: [2/2], Step: [54/95], Loss: 0.5928 Epoch: [2/2], Step: [56/95], Loss: 0.4353 Epoch: [2/2], Step: [58/95], Loss: 0.4750 Epoch: [2/2], Step: [60/95], Loss: 0.5224 Epoch: [2/2], Step: [62/95], Loss: 0.4556 Epoch: [2/2], Step: [64/95], Loss: 0.5933 Epoch: [2/2], Step: [66/95], Loss: 0.3845 Epoch: [2/2], Step: [68/95], Loss: 0.4785 Epoch: [2/2], Step: [70/95], Loss: 0.3595 Epoch: [2/2], Step: [72/95], Loss: 0.4227 Epoch: [2/2], Step: [74/95], Loss: 0.4752 Epoch: [2/2], Step: [76/95], Loss: 0.4309 Epoch: [2/2], Step: [78/95], Loss: 0.6019 Epoch: [2/2], Step: [80/95], Loss: 0.4804 Epoch: [2/2], Step: [82/95], Loss: 0.4837 Epoch: [2/2], Step: [84/95], Loss: 0.4814 Epoch: [2/2], Step: [86/95], Loss: 0.4655 Epoch: [2/2], Step: [88/95], Loss: 0.3835 Epoch: [2/2], Step: [90/95], Loss: 0.4910 Epoch: [2/2], Step: [92/95], Loss: 0.6352 Epoch: [2/2], Step: [94/95], Loss: 0.3918 train loss: 0.0037 train acc: 0.8349
然后就会在output文件夹下生成一个dogcat-resnet18.t7文件。
在train文件夹下新建一个retrain.py文件,在里面加入:
import sys sys.path.append("/content/drive/My Drive/colab notebooks") from utils import rdata from model import resnet import torch.nn as nn import torch import numpy as np import torchvision np.random.seed(0) torch.manual_seed(0) torch.cuda.manual_seed_all(0) torch.backends.cudnn.deterministic = True #torch.backends.cudnn.benchmark = False torch.backends.cudnn.benchmark = True device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') train_loader,test_loader,train_data,test_data=rdata.load_dataset() model =torchvision.models.resnet18(pretrained=False) model.fc = nn.Linear(model.fc.in_features,2,bias=False) model.cuda() #print(model) save_path="/content/drive/My Drive/colab notebooks/output/dogcat-resnet18.t7" checkpoint = torch.load(save_path) model.load_state_dict(checkpoint['model']) optimizer = torch.optim.SGD(params=model.parameters(), lr=0.1, momentum=0.9, weight_decay=1*1e-4) optimizer.load_state_dict(checkpoint['optimizer']) start_epoch = checkpoint['epoch'] start_loss=checkpoint["train_loss"] start_acc=checkpoint["train_acc"] print("当前epoch:{} 当前训练损失:{:.4f} 当前训练准确率:{:.4f}".format(start_epoch+1,start_loss,start_acc)) num_epochs=4 criterion=nn.CrossEntropyLoss() # Train the model total_step = len(train_loader) def train(): total_step = len(train_loader) for epoch in range(start_epoch+1,num_epochs): tot_loss = 0.0 correct = 0 for i ,(images, labels) in enumerate(train_loader): images = images.cuda() labels = labels.cuda() # Forward pass outputs = model(images) _, preds = torch.max(outputs.data,1) loss = criterion(outputs, labels) # Backward and optimizer optimizer.zero_grad() loss.backward() optimizer.step() tot_loss += loss.data if (i+1) % 2 == 0: print('Epoch: [{}/{}], Step: [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item())) correct += torch.sum(preds == labels.data).to(torch.float32) ### Epoch info #### epoch_loss = tot_loss/len(train_data) print('train loss: {:.4f}'.format(epoch_loss)) epoch_acc = correct/len(train_data) print('train acc: {:.4f}'.format(epoch_acc)) """ state = { 'model': model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch': epoch, 'train_loss':epoch_loss, 'train_acc':epoch_acc, } save_path="/content/drive/My Drive/colab notebooks/output/" torch.save(state,save_path+'/dogcat-resnet18'+".t7") """ train()
在test.ipynb中:
看下结果:
当前epoch:2 当前训练损失:0.0037 当前训练准确率:0.8349 Epoch: [3/4], Step: [2/95], Loss: 0.4152 Epoch: [3/4], Step: [4/95], Loss: 0.4628 Epoch: [3/4], Step: [6/95], Loss: 0.4717 Epoch: [3/4], Step: [8/95], Loss: 0.3951 Epoch: [3/4], Step: [10/95], Loss: 0.4903 Epoch: [3/4], Step: [12/95], Loss: 0.5084 Epoch: [3/4], Step: [14/95], Loss: 0.4495 Epoch: [3/4], Step: [16/95], Loss: 0.4196 Epoch: [3/4], Step: [18/95], Loss: 0.5053 Epoch: [3/4], Step: [20/95], Loss: 0.5323 Epoch: [3/4], Step: [22/95], Loss: 0.3890 Epoch: [3/4], Step: [24/95], Loss: 0.3874 Epoch: [3/4], Step: [26/95], Loss: 0.4350 Epoch: [3/4], Step: [28/95], Loss: 0.6274 Epoch: [3/4], Step: [30/95], Loss: 0.4692 Epoch: [3/4], Step: [32/95], Loss: 0.4368 Epoch: [3/4], Step: [34/95], Loss: 0.4563 Epoch: [3/4], Step: [36/95], Loss: 0.4526 Epoch: [3/4], Step: [38/95], Loss: 0.6040 Epoch: [3/4], Step: [40/95], Loss: 0.4918 Epoch: [3/4], Step: [42/95], Loss: 0.4760 Epoch: [3/4], Step: [44/95], Loss: 0.4116 Epoch: [3/4], Step: [46/95], Loss: 0.4456 Epoch: [3/4], Step: [48/95], Loss: 0.3902 Epoch: [3/4], Step: [50/95], Loss: 0.4375 Epoch: [3/4], Step: [52/95], Loss: 0.4197 Epoch: [3/4], Step: [54/95], Loss: 0.4583 Epoch: [3/4], Step: [56/95], Loss: 0.5170 Epoch: [3/4], Step: [58/95], Loss: 0.3454 Epoch: [3/4], Step: [60/95], Loss: 0.4854 Epoch: [3/4], Step: [62/95], Loss: 0.4227 Epoch: [3/4], Step: [64/95], Loss: 0.4466 Epoch: [3/4], Step: [66/95], Loss: 0.3222 Epoch: [3/4], Step: [68/95], Loss: 0.4738 Epoch: [3/4], Step: [70/95], Loss: 0.3542 Epoch: [3/4], Step: [72/95], Loss: 0.4057 Epoch: [3/4], Step: [74/95], Loss: 0.5168 Epoch: [3/4], Step: [76/95], Loss: 0.6254 Epoch: [3/4], Step: [78/95], Loss: 0.4532 Epoch: [3/4], Step: [80/95], Loss: 0.5345 Epoch: [3/4], Step: [82/95], Loss: 0.4308 Epoch: [3/4], Step: [84/95], Loss: 0.4858 Epoch: [3/4], Step: [86/95], Loss: 0.3730 Epoch: [3/4], Step: [88/95], Loss: 0.4989 Epoch: [3/4], Step: [90/95], Loss: 0.4551 Epoch: [3/4], Step: [92/95], Loss: 0.4290 Epoch: [3/4], Step: [94/95], Loss: 0.4964 train loss: 0.0036 train acc: 0.8350 Epoch: [4/4], Step: [2/95], Loss: 0.4666 Epoch: [4/4], Step: [4/95], Loss: 0.4718 Epoch: [4/4], Step: [6/95], Loss: 0.3128 Epoch: [4/4], Step: [8/95], Loss: 0.4594 Epoch: [4/4], Step: [10/95], Loss: 0.4340 Epoch: [4/4], Step: [12/95], Loss: 0.5142 Epoch: [4/4], Step: [14/95], Loss: 0.5605 Epoch: [4/4], Step: [16/95], Loss: 0.3684 Epoch: [4/4], Step: [18/95], Loss: 0.4475 Epoch: [4/4], Step: [20/95], Loss: 0.3848 Epoch: [4/4], Step: [22/95], Loss: 0.4336 Epoch: [4/4], Step: [24/95], Loss: 0.3768 Epoch: [4/4], Step: [26/95], Loss: 0.3612 Epoch: [4/4], Step: [28/95], Loss: 0.4216 Epoch: [4/4], Step: [30/95], Loss: 0.4793 Epoch: [4/4], Step: [32/95], Loss: 0.5047 Epoch: [4/4], Step: [34/95], Loss: 0.3930 Epoch: [4/4], Step: [36/95], Loss: 0.5394 Epoch: [4/4], Step: [38/95], Loss: 0.4942 Epoch: [4/4], Step: [40/95], Loss: 0.3508 Epoch: [4/4], Step: [42/95], Loss: 0.4793 Epoch: [4/4], Step: [44/95], Loss: 0.3653 Epoch: [4/4], Step: [46/95], Loss: 0.3687 Epoch: [4/4], Step: [48/95], Loss: 0.4277 Epoch: [4/4], Step: [50/95], Loss: 0.4232 Epoch: [4/4], Step: [52/95], Loss: 0.6062 Epoch: [4/4], Step: [54/95], Loss: 0.4507 Epoch: [4/4], Step: [56/95], Loss: 0.4614 Epoch: [4/4], Step: [58/95], Loss: 0.4422 Epoch: [4/4], Step: [60/95], Loss: 0.5255 Epoch: [4/4], Step: [62/95], Loss: 0.4257 Epoch: [4/4], Step: [64/95], Loss: 0.4618 Epoch: [4/4], Step: [66/95], Loss: 0.3560 Epoch: [4/4], Step: [68/95], Loss: 0.4291 Epoch: [4/4], Step: [70/95], Loss: 0.3562 Epoch: [4/4], Step: [72/95], Loss: 0.3683 Epoch: [4/4], Step: [74/95], Loss: 0.4324 Epoch: [4/4], Step: [76/95], Loss: 0.3972 Epoch: [4/4], Step: [78/95], Loss: 0.5116 Epoch: [4/4], Step: [80/95], Loss: 0.4582 Epoch: [4/4], Step: [82/95], Loss: 0.4102 Epoch: [4/4], Step: [84/95], Loss: 0.4086 Epoch: [4/4], Step: [86/95], Loss: 0.4178 Epoch: [4/4], Step: [88/95], Loss: 0.3906 Epoch: [4/4], Step: [90/95], Loss: 0.4631 Epoch: [4/4], Step: [92/95], Loss: 0.5832 Epoch: [4/4], Step: [94/95], Loss: 0.3421 train loss: 0.0035 train acc: 0.8361
确实是能够继续进行训练,且相关信息也得到了。
下一节,进行模型的测试工作啦。