import datetime import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms, utils, datasets from tensorflow import summary
%load_ext tensorboard
根据情况换成
%load_ext tensorboard.notebook
class Network(nn.Module): def __init__(self): super(Network, self).__init__() self.conv1 = nn.Conv2d(1, 20, 5, 1) self.conv2 = nn.Conv2d(20, 50, 5, 1) self.fc1 = nn.Linear(4*4*50, 500) self.fc2 = nn.Linear(500, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = F.max_pool2d(x, 2, 2) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, 2, 2) x = x.view(-1, 4*4*50) x = F.relu(self.fc1(x)) x = self.fc2(x) return F.log_softmax(x, dim=1)
class Config: def __init__(self, **kwargs): for key, value in kwargs.items(): setattr(self, key, value) model_config = Config( cuda = True if torch.cuda.is_available() else False, device = torch.device("cuda" if torch.cuda.is_available() else "cpu"), seed = 2, lr = 0.01, epochs = 4, save_model = False, batch_size = 32, log_interval = 100 ) class Trainer: def __init__(self, config): self.cuda = config.cuda self.device = config.device self.seed = config.seed self.lr = config.lr self.epochs = config.epochs self.save_model = config.save_model self.batch_size = config.batch_size self.log_interval = config.log_interval self.globaliter = 0 #self.tb = TensorBoardColab() torch.manual_seed(self.seed) kwargs = {'num_workers': 1, 'pin_memory': True} if self.cuda else {} self.train_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=self.batch_size, shuffle=True, **kwargs) self.test_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=self.batch_size, shuffle=True, **kwargs) self.model = Network().to(self.device) self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr) def train(self, epoch): self.model.train() for batch_idx, (data, target) in enumerate(self.train_loader): self.globaliter += 1 data, target = data.to(self.device), target.to(self.device) self.optimizer.zero_grad() predictions = self.model(data) loss = F.nll_loss(predictions, target) loss.backward() self.optimizer.step() if batch_idx % self.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format( epoch, batch_idx * len(data), len(self.train_loader.dataset), 100. * batch_idx / len(self.train_loader), loss.item())) with train_summary_writer.as_default(): summary.scalar('loss', loss.item(), step=self.globaliter) def test(self, epoch): self.model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in self.test_loader: data, target = data.to(self.device), target.to(self.device) predictions = self.model(data) test_loss += F.nll_loss(predictions, target, reduction='sum').item() prediction = predictions.argmax(dim=1, keepdim=True) correct += prediction.eq(target.view_as(prediction)).sum().item() test_loss /= len(self.test_loader.dataset) accuracy = 100. * correct / len(self.test_loader.dataset) print(' Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%) '.format( test_loss, correct, len(self.test_loader.dataset), accuracy)) with test_summary_writer.as_default(): summary.scalar('loss', test_loss, step=self.globaliter) summary.scalar('accuracy', accuracy, step=self.globaliter) def main(): trainer = Trainer(model_config) for epoch in range(1, trainer.epochs + 1): trainer.train(epoch) trainer.test(epoch) if (trainer.save_model): torch.save(trainer.model.state_dict(),"mnist_cnn.pt")
current_time = str(datetime.datetime.now().timestamp())
train_log_dir = 'logs/tensorboard/train/' + current_time
test_log_dir = 'logs/tensorboard/test/' + current_time
train_summary_writer = summary.create_file_writer(train_log_dir)
test_summary_writer = summary.create_file_writer(test_log_dir)
%tensorboard --logdir logs/tensorboard
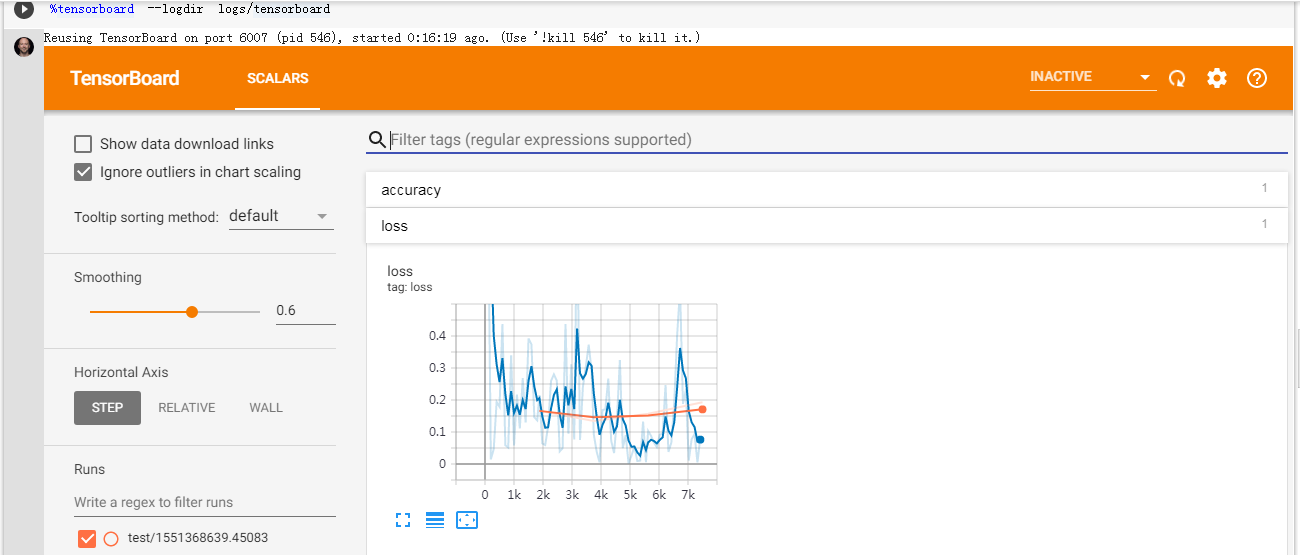
main()
Train Epoch: 1 [0/60000 (0%)] Loss: 2.320306 Train Epoch: 1 [3200/60000 (5%)] Loss: 0.881239 Train Epoch: 1 [6400/60000 (11%)] Loss: 0.014427 Train Epoch: 1 [9600/60000 (16%)] Loss: 0.046511 Train Epoch: 1 [12800/60000 (21%)] Loss: 0.194090 Train Epoch: 1 [16000/60000 (27%)] Loss: 0.178779 Train Epoch: 1 [19200/60000 (32%)] Loss: 0.437568 Train Epoch: 1 [22400/60000 (37%)] Loss: 0.058614 Train Epoch: 1 [25600/60000 (43%)] Loss: 0.051354 Train Epoch: 1 [28800/60000 (48%)] Loss: 0.339627 Train Epoch: 1 [32000/60000 (53%)] Loss: 0.057814 Train Epoch: 1 [35200/60000 (59%)] Loss: 0.216959 Train Epoch: 1 [38400/60000 (64%)] Loss: 0.111091 Train Epoch: 1 [41600/60000 (69%)] Loss: 0.268371 Train Epoch: 1 [44800/60000 (75%)] Loss: 0.129569 Train Epoch: 1 [48000/60000 (80%)] Loss: 0.392319 Train Epoch: 1 [51200/60000 (85%)] Loss: 0.374106 Train Epoch: 1 [54400/60000 (91%)] Loss: 0.145877 Train Epoch: 1 [57600/60000 (96%)] Loss: 0.136342 Test set: Average loss: 0.1660, Accuracy: 9497/10000 (95%) Train Epoch: 2 [0/60000 (0%)] Loss: 0.215095 Train Epoch: 2 [3200/60000 (5%)] Loss: 0.064202 Train Epoch: 2 [6400/60000 (11%)] Loss: 0.059504 Train Epoch: 2 [9600/60000 (16%)] Loss: 0.116854 Train Epoch: 2 [12800/60000 (21%)] Loss: 0.259310 Train Epoch: 2 [16000/60000 (27%)] Loss: 0.280154 Train Epoch: 2 [19200/60000 (32%)] Loss: 0.260245 Train Epoch: 2 [22400/60000 (37%)] Loss: 0.039311 Train Epoch: 2 [25600/60000 (43%)] Loss: 0.049329 Train Epoch: 2 [28800/60000 (48%)] Loss: 0.437081 Train Epoch: 2 [32000/60000 (53%)] Loss: 0.094939 Train Epoch: 2 [35200/60000 (59%)] Loss: 0.311777 Train Epoch: 2 [38400/60000 (64%)] Loss: 0.076921 Train Epoch: 2 [41600/60000 (69%)] Loss: 0.800094 Train Epoch: 2 [44800/60000 (75%)] Loss: 0.074938 Train Epoch: 2 [48000/60000 (80%)] Loss: 0.240811 Train Epoch: 2 [51200/60000 (85%)] Loss: 0.303044 Train Epoch: 2 [54400/60000 (91%)] Loss: 0.372847 Train Epoch: 2 [57600/60000 (96%)] Loss: 0.290946 Test set: Average loss: 0.1341, Accuracy: 9634/10000 (96%) Train Epoch: 3 [0/60000 (0%)] Loss: 0.092767 Train Epoch: 3 [3200/60000 (5%)] Loss: 0.038457 Train Epoch: 3 [6400/60000 (11%)] Loss: 0.005179 Train Epoch: 3 [9600/60000 (16%)] Loss: 0.168411 Train Epoch: 3 [12800/60000 (21%)] Loss: 0.171331 Train Epoch: 3 [16000/60000 (27%)] Loss: 0.267252 Train Epoch: 3 [19200/60000 (32%)] Loss: 0.072991 Train Epoch: 3 [22400/60000 (37%)] Loss: 0.034315 Train Epoch: 3 [25600/60000 (43%)] Loss: 0.143128 Train Epoch: 3 [28800/60000 (48%)] Loss: 0.324783 Train Epoch: 3 [32000/60000 (53%)] Loss: 0.049743 Train Epoch: 3 [35200/60000 (59%)] Loss: 0.090172 Train Epoch: 3 [38400/60000 (64%)] Loss: 0.002107 Train Epoch: 3 [41600/60000 (69%)] Loss: 0.025945 Train Epoch: 3 [44800/60000 (75%)] Loss: 0.054859 Train Epoch: 3 [48000/60000 (80%)] Loss: 0.009291 Train Epoch: 3 [51200/60000 (85%)] Loss: 0.010495 Train Epoch: 3 [54400/60000 (91%)] Loss: 0.132548 Train Epoch: 3 [57600/60000 (96%)] Loss: 0.005778 Test set: Average loss: 0.1570, Accuracy: 9553/10000 (96%) Train Epoch: 4 [0/60000 (0%)] Loss: 0.103177 Train Epoch: 4 [3200/60000 (5%)] Loss: 0.087844 Train Epoch: 4 [6400/60000 (11%)] Loss: 0.066604 Train Epoch: 4 [9600/60000 (16%)] Loss: 0.052869 Train Epoch: 4 [12800/60000 (21%)] Loss: 0.091576 Train Epoch: 4 [16000/60000 (27%)] Loss: 0.094903 Train Epoch: 4 [19200/60000 (32%)] Loss: 0.247008 Train Epoch: 4 [22400/60000 (37%)] Loss: 0.037751 Train Epoch: 4 [25600/60000 (43%)] Loss: 0.067071 Train Epoch: 4 [28800/60000 (48%)] Loss: 0.191988 Train Epoch: 4 [32000/60000 (53%)] Loss: 0.403029 Train Epoch: 4 [35200/60000 (59%)] Loss: 0.547171 Train Epoch: 4 [38400/60000 (64%)] Loss: 0.187923 Train Epoch: 4 [41600/60000 (69%)] Loss: 0.231193 Train Epoch: 4 [44800/60000 (75%)] Loss: 0.010785 Train Epoch: 4 [48000/60000 (80%)] Loss: 0.077892 Train Epoch: 4 [51200/60000 (85%)] Loss: 0.093144 Train Epoch: 4 [54400/60000 (91%)] Loss: 0.004715 Train Epoch: 4 [57600/60000 (96%)] Loss: 0.083726 Test set: Average loss: 0.1932, Accuracy: 9584/10000 (96%)
核心就是标红的地方。